
虚拟机
虚拟机
Emulation
指令集模拟是在一个平台上模拟另一个(或同一)CPU 的指令与执行语义。常见场景包括:跨架构仿真(比如在 x86 上跑 ARM 二进制)、系统模拟(Bochs)、动态二进制分析
Interpretation
解释执行(Interpretation):逐条取出目标指令,解析并执行对应的宿主(host)操作。
simple interpreter
是一种执行程序的方法,它不直接在硬件上运行目标二进制,而是 逐条读取(decode)、理解(dispatch)、执行(interpret)指令的语义。Decode-and-Dispatch 模式
- 核心机制:有一个大循环(interpreter
loop),每次循环:
- 取指 (fetch):从“程序计数器(PC)”指向的内存里读一条指令。
- 解码 (decode):解析这条指令是什么类型(加法?加载?跳转?)。
- 分发 (dispatch):根据指令类型,跳转到对应的解释函数/分支逻辑。
- 执行 (execute):修改解释器内部维护的状态(寄存器、内存、标志位等)。
- 更新 PC:让 PC 指向下一条指令,然后继续循环。
- 这种结构叫 decode-and-dispatch interpreter,因为它的循环主要做两件事:解码 + 分发。
Threaded Interpretation
其中 dispatch(分派)开销很大:
- 每条 guest 指令都要走一次
switch-case,即使宿主已经知道下一条指令的类型。 - 分支预测容易失败(尤其是 guest 指令随机混合时)。
Threaded Interpretation 的核心思想
- 提前把“分派信息”存好,减少运行时的 switch-case 开销。
- 通过 直接跳转表(jump table) 或 函数指针数组,让解释器在执行完一条指令后,能直接跳到下一条指令对应的解释代码。
(a) 指令预处理
- 把 guest 指令流转成一组“解释器操作码(interpreter opcodes)”,
- 每个操作码对应一个 函数指针 / 标签地址。
(b) 执行循环
1 | // 每个指令对应的函数(handler) |
性能大幅提升:消除了大 switch
的分支预测开销,指令执行效率更接近 DBT。
结构紧凑:代码逻辑更接近汇编跳转流程。
易扩展:只要给新指令定义 handler 即可。
Predecoding and Direct Threaded Interpretation
Threaded Interpretation 优化掉了分派开销(通过
goto *pc->handler),但还有一个问题:解码成本仍然存在。真实
ISA 的二进制指令通常比较复杂(如 x86 可变长指令)。
每次执行前都要从原始二进制里解码 → 很浪费
Predecoding(预解码)
在程序加载或第一次扫描时,把原始二进制指令解码成一种更容易解释的“中间表示(IR)”。
- 把 guest 二进制逐条读取 → 解码成一个结构体(保存操作码、寄存器编号、立即数、偏移量等)。
- 在结构体里额外存一个指向 解释函数 handler 的指针。
这样一来,解释器执行时就不用再做复杂解码了,直接使用预先存好的 handler 地址和参数即可。
Direct Threaded Interpretation
- 每个预解码后的指令条目都带有 直接跳转到对应 handler 的地址。
- 执行时:
goto *pc->handler,执行 handler,handler 里再跳到下一条。
这样:
- 无需中心调度循环。
- 无需在执行时再查找 opcode → handler 的映射。
Interpreting a Complex Instruction Set
RISC(简化指令集):指令长度固定、格式统一、操作数数量有限、寻址方式少。比如 PowerPC、MIPS、RISC-V。→ 解释器很容易写:PC 每次 +4,解码也很简单。
CISC(复杂指令集):指令长度不固定、寻址模式多、单条指令可能做很多事(如加载、算术、存储、条件更新标志)。典型代表:x86。
Interpretation of the IA-32 ISA
IA-32 的解释器通常分成 两步走:
- 填充通用指令模板
- 把原始字节流解码成一个“中间表示”(类似指令对象),包括操作码、操作数类型、寻址模式、立即数/位移等。
- 这一步解决变长指令与复杂寻址的解析。
- 分发至专用例程
- 根据解码结果(操作码、寻址模式等),调用相应的解释函数来模拟执行。
👉 实现方式通常依赖一个 大型查找表:
- 输入是操作码,输出是对应的解码/执行函数。
- 遇到 ModR/M、SIB、位移、立即数时,还要进一步解析并存入模板。
Threaded Interpretation
问题:如果每个解释例程都内嵌完整的“解码逻辑”,代码会非常庞大、冗余。
优化思路:混合模型
- 简单、常见指令 → 用轻量级 direct threading 技术,直接跳转到 handler,避免大开销。
- 复杂、少见指令 → 回退到 集中式解码器,统一解析。
Binary Translation
它是比“逐条解释”更高效的一种指令集模拟技术,同时涉及 代码发现与动态翻译(DBT, Dynamic Binary Translation)。
二进制翻译:把一段源 ISA 的指令序列(通常是基本块 basic block)一次性翻译为目标 ISA 的等效代码。
代码块翻译与缓存
- 单位:基本块(single-entry, single-exit),因为控制流简单,便于翻译。
- 翻译后存入 代码缓存(code cache),下次遇到直接跳转到缓存的机器码。
- 若源代码有 自修改(self-modifying code),需要失效并重新翻译。
寄存器状态映射
- 源 ISA 的寄存器数量/功能 ≠ 目标 ISA。
- 通过 寄存器映射,把源寄存器直接绑定到目标物理寄存器,减少访存。
- 比如:IA-32 的
EAX直接映射到 PowerPC 的r5。
指令序列优化
翻译不仅是逐条对等替换,还能做优化:
- 死代码消除(eliminate dead code)。
- 公共子表达式消除(common subexpression elimination)。
- 寄存器复用(避免多余 load/store)。
- 常量折叠(constant folding)。
Code Discovery and Dynamic Translation
The Code-Discovery Problem
翻译器必须知道哪些字节是 可执行的指令,才能正确解码。但在 CISC 架构(如 IA-32/x86) 上,这个过程非常棘手。
难点
- 变长指令
- 间接跳转(Indirect Jumps/Calls)
- 目标地址不是立即数,而是寄存器值或内存取值。
- 只有运行时才能知道跳到哪里。
- 静态分析无法提前收集所有目标地址。
- 数据混杂在代码段中
- 某些程序在代码段中嵌入数据(例如查表、只读掩码、对齐填充)。
- 如果翻译器误把这些数据当成指令解码,就会出错。
- 指令对齐(Alignment)问题
- 编译器可能在代码里插入对齐填充(如
0x90NOP), - 甚至可能造成某些字节既是对齐填充又可能被跳转到作为指令入口。
- 这使得静态预解码更加困难。
- 编译器可能在代码里插入对齐填充(如
👉 结论:CISC 上几乎无法通过静态分析完整、准确地发现所有代码块。 因此,动态二进制翻译(DBT)一般采用 运行时发现 + 按需翻译。
The Code-Location Problem
当源代码被翻译为目标 ISA 代码后,就存在 两套 PC(程序计数器):
- SPC(Source PC):源 ISA 的指令地址。
- TPC(Target PC):翻译后代码在宿主 ISA 中的地址。
问题:
- guest 程序在执行时,寄存器保存的是 SPC 地址。
- 但 DBT 翻译后的代码在宿主机器上运行时,需要跳转到 TPC。
- 如果直接用 SPC 跳转,会跳到错误的地方(因为 SPC ≠ TPC)。
解决办法:
- 建立映射表(Mapping Table):
- 记录每个 SPC 对应的 TPC。
- 在执行间接跳转时:
- 取出 guest 代码给的 SPC;
- 查映射表找到对应的 TPC;
- 跳转到 TPC。
- 优化手段:
- 直接插桩:在翻译后的代码里,用跳转表或内联检查,把 SPC → TPC 的转换直接嵌入。
- 快速路径 + 慢路径:
- 常见的目标 SPC 直接内联成直接跳转。
- 不常见的 SPC 则走查表。
Incremental Predecoding and Translation
动态二进制翻译系统(DBT)通常包含:
- 解释器 (Interpreter):兜底执行,或者在翻译前先跑一段。
- 二进制翻译器 (Translator):把源 ISA 指令块转换为目标 ISA 代码。
- 仿真管理器 (EM, Execution Manager):调度运行时流程,负责 SPC→TPC 映射、桩代码管理、异常/中断恢复。
- 代码缓存 (Code Cache):存放已经翻译好的目标代码。
- SPC-TPC 映射表:源地址(Source PC)和目标地址(Target PC)的映射,用于间接跳转和异常处理。
Dynamic Basic Block
使用动态基本块作为翻译单元 ,从一个控制流入口(通常是分支/跳转目标)开始,顺序包含多条指令,直到遇到下一个分支/跳转结束。
与 静态基本块的区别:
- 静态基本块由编译器分析决定,唯一划分。
- 动态基本块依赖运行时的控制流路径 → 更大、更多样。
- 同一条指令可能出现在多个不同的动态块里(因为来自不同路径)。

DBT 不会在运行前翻译整个程序(那是静态翻译的思路)。
采用 增量式:
- 第一次执行某段 SPC 时 → 翻译成目标代码,存入缓存。
- 下一次再遇到同一 SPC → 直接跳转到缓存好的 TPC。
SPC-TPC 映射表
- 功能:把源程序的 PC(SPC)转换成翻译后目标代码的入口(TPC)。
- 典型实现:哈希表,查询快、可扩展。
桩代码(Stubs)
- 动态块通常以 分支或跳转结束。
- DBT 会在末尾插入 桩代码 (stub):
- 保存下一个 SPC 值。
- 把控制权交回仿真管理器(EM)。
- EM 根据 SPC 查映射表:
- 如果已翻译 → 跳到对应的 TPC。
- 如果没翻译 → 调用翻译器生成新块。
👉 桩代码相当于 中转站,保证动态控制流始终能正确跳转。
自修改代码 (Self-Modifying Code)
- 如果源程序修改了自己(写入代码段),则对应的翻译版本失效。
- 需要检测并 重新翻译该代码块。
自引用代码 (Self-Referential Code)
- 程序有时会读取自身指令字节作为数据。
- 在这种情况下,必须返回 原始二进制,而不是翻译后的版本。
- 因此,DBT 系统必须同时保留原始代码副本
源 ISA 可能要求某些异常/中断发生时,必须在精确的指令边界恢复上下文。
DBT 在翻译时必须保证:
- 如果 TPC 执行时出错(如访问越界),系统能回溯到对应的 SPC。
- 并且恢复源寄存器、标志位等上下文。
这要求翻译器在生成代码时插入 映射点 (mapping points),保证能从宿主状态恢复出精确的源状态。
Same-ISA Emulation
虽然源程序和宿主机器的 指令集架构(ISA)相同,理论上可以直接运行,但仍然通过一个“仿真层”来间接执行程序。这样做的目的,不是跨平台,而是为了 控制、监控和优化 程序运行。
应用场景
- 程序性能模拟
- 例如 Shade 系统(早期的 SPARC 同 ISA 仿真器),通过插桩收集性能数据,评估程序行为。
- 操作系统调用模拟
- 即使 ISA 一样,不同 OS 也有差异(如 Linux vs. BSD)。
- 仿真层可以把源 OS 的系统调用转化为宿主 OS 的调用。
- 特权操作检测与处理
- 捕获内核相关指令(如 I/O、内存管理指令),避免直接执行带来安全风险。
- 安全防护
- 在仿真层中插入监控逻辑,比如控制流完整性检查,防止攻击者劫持跳转。
- 动态二进制优化
- DBT 技术可以利用运行时信息(热点路径、分支预测结果等)来做动态优化。
- 例如在运行时对频繁执行的循环进行指令级优化,提高整体性能。
同 ISA 仿真器往往不需要复杂的“翻译”工作,因为源/目标 ISA 一致。
实际做法类似于 源码复制 + 轻量包装:
- 普通指令 → 直接执行或简单转发;
- 系统调用、特权指令等特殊情况 → 拦截并处理。
Control Transfer Optimizations
动态二进制翻译(DBT)中的控制流优化,目标是减少“翻译块之间的切换开销”,让程序在缓存好的翻译代码中更顺畅地执行。
Translation Chaining
问题:在基础的 DBT 中,每个翻译块(Translation Block, TB)执行结束时,通常会通过桩代码(stub)返回到仿真管理器(EM),再由 EM 决定下一个要执行的 TB。这样一来,每个跳转都会有 EM 介入,性能开销很大。
优化:
- 初始时,块末尾放一段跳转到 EM 的桩代码。
- 当后续块被翻译出来后,可以 回填(patch) 前一块的桩代码 → 直接跳转到新块的入口。
- 这样两个翻译块就被“链”在一起,运行时直接跳过去,减少 EM 调度。
限制:
- 仅适用于 直接跳转(目标固定可知)。
- 间接跳转(比如函数返回,目标依赖寄存器或内存值)不适合直接链接。
Software Indirect Jump Prediction
问题:间接跳转(如函数指针调用、虚函数调用、switch 表、返回地址)在运行时目标可能变化。没法提前静态链接,只能依赖查表 → 成本高。
优化:内联缓存 (Inline Caching, IC)
- 在翻译块中直接嵌入“快速判断逻辑”:
- 如果当前跳转目标 = 最近一次/常见的 SPC → 直接跳转到缓存的 TPC。
- 如果不匹配 → 回退到 EM,通过映射表查找正确目标。
Shadow Stack
问题:函数调用/返回是最常见的间接跳转。如果每次返回都要查映射表,成本高。
优化:
- 在 函数调用时,除了正常把返回地址压入源栈,还把该返回地址(SPC)和对应的 TPC 压入 影子栈。
- 在 函数返回时:
- 比较源栈顶的 SPC 与影子栈顶的 SPC。
- 如果匹配 → 直接用影子栈中的 TPC 跳转,避免查表。
- 如果不匹配 → 回退到正常查表机制。
安全性:
- 同时保存源栈指针(SP)值,检测栈截断或修改,保证影子栈和源栈同步。
Instruction Set Issues
动态二进制翻译(DBT)中与指令集差异相关的挑战。当源 ISA 和目标 ISA 不同的时候,必须解决寄存器、条件码和数据表示等方面的不匹配问题,否则翻译出来的代码要么不能执行,要么语义不对。
Register Architectures
挑战:目标架构的寄存器既要保存源程序的寄存器值,还要承担运行时环境管理(比如指向上下文块)和翻译过程中生成的中间值。如果目标架构寄存器数量少,就容易不够用。
情况一:寄存器宽裕(RISC 模拟 CISC)
- 比如用 PowerPC/RISC-V 来模拟 x86,目标寄存器数量多,可以 静态分配。
- 常用策略:给源寄存器分配固定的目标寄存器,把一部分寄存器专门用来保存上下文指针或中间值。
情况二:寄存器紧张
- 比如在寄存器少的目标 ISA 上模拟寄存器多的源 ISA。
- 必须 动态管理:在翻译块入口/出口处,把源寄存器状态保存/恢复到内存的“上下文块”,在块内灵活分配寄存器。
Condition Codes
差异来源:
- IA-32 (x86):有隐式条件码(EFLAGS),每次算术操作自动更新。
- SPARC / PowerPC:条件码是显式设置的(需要单独指令)。
- MIPS:没有条件码,而是通过比较指令直接得到分支结果。
最难情况:源 ISA 有隐式条件码(x86),但目标 ISA 没有(MIPS)。这意味着必须模拟条件码更新,但不能直接映射寄存器。
常见优化:
- 惰性求值 (Lazy Evaluation):不立即计算条件码,而是记录“由哪条操作生成了哪些标志位”,只有当真正用到时才计算。
- 数据流分析:如果确定某些条件码值根本没被用到,可以完全跳过,减少开销。
异常情况:如果程序在一条指令后触发异常,必须立即 物化(materialize) 出所有相关条件码,确保系统能恢复到与源 ISA 完全一致的状态。
Data Formats and Arithmetic
相对容易的情况:
- 整数:大多数 ISA 都用二进制补码。
- 浮点:大多数遵循 IEEE 754 标准。
- → 这部分通常能直接映射。
差异与挑战:
- IA-32:使用 80 位浮点中间结果(比常见的 64 位双精度更高)。在模拟时,可能需要额外保存精度,否则结果不一致。
- PowerPC:部分浮点乘加指令精度高于 IEEE 标准 → 必须小心保持一致性。
缺失功能的替代:
- 目标 ISA 没有对应指令时,可以用多条指令组合实现。例如:
- 除法缺失 → 用移位和减法迭代实现。
- 复杂寻址模式(如 x86 的
[base+index*scale+disp]) → 拆解为加法 + 乘法 + 加载序列。
- 立即数长度不够 → 用多条加载/移位/或运算组合出完整常量。
Memory Address Resolution
问题:不同 ISA 支持的最小存取单位不同。
- 有的 ISA 是 字节寻址(x86、ARM 等),最小单位 1 byte。
- 有的 ISA 是 字寻址(早期的 PDP-11、部分 DSP),最小单位是 word。
挑战:
- 如果目标 ISA 只支持 word 级访问,但源 ISA 允许 byte 访问,就需要用移位、掩码来提取特定字节。
- 反之,如果目标 ISA 是 byte 寻址,模拟 word 寻址的源机就比较容易(属于“强模拟弱”)。
Memory Data Alignment
问题:
- 有些 ISA 要求 自然对齐(比如 4 字节 word 必须在 4 的倍数地址)。
- 但像 x86 允许非对齐访问。
挑战:
- 如果目标 ISA 不支持非对齐访问,就要在 DBT 中拆成多个 byte
load/store,或使用目标 ISA 的专用指令(如 ARM 的
LDRD/STRD辅助)。
优化:
- 运行时分析访问地址是否对齐:
- 若对齐 → 用高效的 word 访问。
- 若不对齐 → 退化成字节级操作。
Byte Order
差异:
- 大端 (Big-endian):最高有效字节在低地址(PowerPC、SPARC)。
- 小端 (Little-endian):最低有效字节在低地址(x86、RISC-V)。
挑战:
- 若源/目标 ISA 字节序不同,每次 load/store 都要做字节翻转。
- 非对齐访问时更麻烦,往往需要逐字节重组,或者利用双字加载+移位来拼接。
优化:
- 如果目标 ISA 硬件支持双端模式(bi-endian),直接切换模式,避免软件翻转。
- 系统调用数据交互时,也要用包装代码保证字节序一致。
Addressing Architecture
问题:ISA 在地址空间、页面大小、特权机制上可能不同。
- 比如源 ISA 支持 32 位虚拟地址,目标 ISA 是 64 位。
- 或者源机有段式内存模型,目标机没有。
挑战:
- 这类问题不是单条 load/store 就能解决的,而是涉及 整个虚拟内存系统设计。
- 必须通过 虚拟机架构 来协调,例如 shadow page table、二级地址翻译。
结论:这个部分通常被延迟到更高层的虚拟机设计里讨论,而不是在单纯的指令翻译阶段处理。
System Virtual Machines
应用场景
- 实现多道程序与时间共享:使用多个单用户虚拟机替代复杂的多道程序操作系统,提升效率与灵活性。
- 多个单应用虚拟机:提高系统鲁棒性,一个应用或操作系统的故障不会影响其他虚拟机。
- 多安全环境:提供沙箱机制,确保不同用户环境之间的隔离,防止数据泄露或监控。
- 受控应用环境:核心应用运行于受保护虚拟机中,用户自定义应用运行于另一虚拟机,避免干扰。
- 混合操作系统环境:同一硬件平台同时运行不同操作系统,满足多样化需求。
- 遗留应用支持:在旧操作系统虚拟机中运行性能敏感的旧应用,在新系统中利用新特性。
- 多平台开发:开发者可在同一硬件上测试跨操作系统软件,降低成本与复杂性。
- 系统迁移过渡:逐步迁移到新操作系统,旧系统继续运行关键应用直至验证完成。
- 系统软件开发:开发与生产环境分离,避免开发中的错误导致系统崩溃。
- 操作系统培训:在虚拟机中进行参数调整实验,不影响真实系统用户。
- 帮助台支持:模拟客户硬件配置以诊断问题,无需物理设备。
- 操作系统仪器化:VMM 可监控硬件访问行为,记录事件详情用于研究与调试。
- 事件监控:支持执行轨迹记录、状态快照与重放,便于分析异常行为。
- 系统封装:完整保存虚拟机状态,支持检查点与迁移。
Key Concepts
- 系统虚拟机通过虚拟机监控器(VMM)在主机硬件上创建多个隔离的虚拟系统环境,每个虚拟机运行独立的操作系统和应用程序。
- VMM 拥有对真实硬件资源的控制权,并将其分配给多个客户操作系统,使每个客户系统以为自己独占资源。
- 虚拟资源可对应真实物理资源(如CPU、内存、I/O设备),也可由VMM通过软件模拟实现。
Outward Appearance
虚拟机给用户的“错觉”是:它就像一台独立的计算机。
这种表现可通过软件模拟(纯软件复制)或硬件支持(部分功能直接由硬件加速)实现。
用户专用的设备(键盘、显示器等)可以:
- 物理复制 → 每个虚拟机独立拥有。
- 共享切换 → 多个虚拟机通过时分/窗口机制共享同一设备。
在宿主操作系统上,客户机界面甚至可以嵌入窗口,比如 DOS 程序运行在 Windows 的窗口中。
State Management
每个虚拟机需要独立的体系结构状态(寄存器、内存、I/O 设备状态)。
状态管理方式:
- 间接访问:虚拟机的寄存器状态保存在主机内存中,通过指针访问。优点是容易实现,但性能较差。
- 直接复制:切换虚拟机时,把客户机寄存器状态复制到物理寄存器中,以获得更高性能。
权衡点:使用频率高的状态(如寄存器)更适合直接复制;使用不频繁或不匹配的资源,可以存放在内存里,用间接方式访问。
Resource Control
- VMM 必须拥有硬件的 最终控制权,哪怕资源在客户机手中。
- 实现方式类似操作系统:
- 操作系统依赖定时器中断来收回 CPU。
- VMM 截获对特权资源(如定时器)的访问,向客户机提供 虚拟定时器。
- 这样可以防止某个客户机垄断资源,保证公平调度。
- 调度权衡:
- 时间片过大 → 响应慢,不公平。
- 时间片过小 → 上下文切换开销太大。
Native and Hosted Virtual Machines
原生虚拟机 (Native VM):
- VMM 直接运行在最高特权级,直接控制硬件。
- 客户机 OS 在较低特权级运行。
- 优点:性能高,开销小。
托管虚拟机 (Hosted VM):
- VMM 作为应用运行在宿主操作系统之上。
- 用户态托管:VMM 全部运行在用户态,灵活但性能较差。
- 双模式托管:部分组件(如驱动)运行在宿主内核中,性能更高。
- 优点:易于部署和维护,不需要完全控制底层硬件。
对比:原生更高效,托管更方便。
IBM VM/370
历史意义:最早的系统虚拟机环境之一。
硬件基础:基于 IBM System/360 Model 40,后来发展到 System/370。
设计目标:把虚拟内存的概念推广到整个系统级别,让每个虚拟机都看到完整的 ISA。
模块化结构:
- 控制程序 (CP) = VMM,负责资源管理。
- 单用户操作系统 CMS = 用户环境。
- CP 和 CMS 分离,使得资源管理与用户服务职责清晰。
硬件演进:System/370 增加了专门的虚拟化支持,降低 VMM 开销。这种思路延续至现代 IBM z/VM。
Resource Virtualization — Processors
处理器资源虚拟化 的主题,核心是 客户指令如何在虚拟机上被执行。
- 关键问题:客户机(guest)指令要么直接执行在硬件上(原生执行),要么由 VMM 模拟(interpret/translate)。
- ISA 相同时 → 尽量让无害指令直接跑在硬件上,性能最佳;只有涉及特权或敏感行为的指令才需要 VMM 截获并模拟。
Conditions for ISA Virtualizability
- Popek 与 Goldberg 三条件:
- 效率 (Efficiency):绝大多数无害指令无需 VMM 干预,能直接在硬件执行。
- 资源控制 (Resource control):客户机软件不能直接改系统资源,VMM 保持最终控制权。
- 等价性 (Equivalence):虚拟机上运行程序的效果必须和真实机器上一致(性能差异除外)。
- 定理 1:若“敏感指令集” ⊆ “特权指令集”,则该 ISA
可高效虚拟化。
- 敏感指令:分为控制敏感(改变资源配置)、行为敏感(结果依赖资源状态)。
- 特权指令:只能在内核态执行,用户态执行会陷阱(trap)到 VMM。
- 理想情况:所有敏感指令都是特权指令 → 可以通过陷阱交给 VMM 处理。
Recursive Virtualization
概念:在一个 VM 内再运行另一个 VMM,形成层次化虚拟化。
要求:VMM 本身不能依赖“绝对时间”,否则破坏等价性。
局限:每层 VMM 占用资源(尤其内存),递归层数有限;一般 ≤2 层可接受。
Handling Problem Instructions
问题:一些 ISA 不满足定理 1。
- 例如 Intel IA-32 存在 敏感但非特权 指令(称为 关键指令),在用户态不会陷阱,但会暴露硬件状态 → 威胁虚拟化。
- 例子:
POPF(修改标志寄存器),在用户态也能执行部分操作。
解决办法:
- 扫描并修补 (patching):运行前扫描代码流,把关键指令替换为会触发陷阱的指令,从而交由 VMM 处理。
Patching of Critical Instructions
- 执行步骤:
- VMM 扫描客户机代码流,遇到关键指令时 → 插入陷阱。
- 陷阱触发后 → VMM 执行模拟逻辑,并继续扫描后续基本块。
- 优化:
- 已修补的基本块可以 直接链接(类似代码缓存),减少重复陷阱。
- 间接跳转目标难预测 → 通常保留陷阱机制。
- 范围:扫描仅限 已加载到内存的代码页,避免因换页带来开销。
Caching Emulation Code
问题:高频关键指令若每次都解释,会产生巨大开销。
解决:
- 把模拟动作编译成 缓存代码块,下次执行时直接运行缓存逻辑,而不是重复解释。
- 缓存以“陷阱地址”为索引。
- 返回时直接跳过已模拟过的部分,提高效率。
- 若客户机代码自修改 → 必须检测并使缓存失效,避免错误执行
Efficient Virtualizability of Common Instruction Sets
IBM System/370
- 所有敏感指令 = 特权指令 → 天然可虚拟化。
- VM/370 中大多数指令原生执行,特权指令陷阱交给 VMM。
- 客户 OS(CMS)允许用户发特权指令,VMM 安全模拟。
Intel IA-32
- 存在“敏感但非特权”指令(如
POPF),不满足定理 1。 - 必须用 修补 或 二进制翻译 (binary translation) 解决。
历史转折:
- 早期(硬件便宜时)一度认为虚拟机没价值。
- 但随着安全、服务器整合、跨平台需求的兴起,虚拟化重新变得重要。
Resource Virtualization — Memory
Virtual Memory Support in a System Virtual Machine Environment
在普通系统中:
- 应用程序 看到的是逻辑地址空间。
- 操作系统 通过页表把逻辑地址映射到真实硬件的物理内存。
在 系统虚拟机 中:
- 每个客户 VM 以为自己独占物理内存(称为“实内存”)。
- 实际上,这个“实内存”只是 VMM 虚拟出来的错觉。
- VMM 把客户 VM 的“实地址”再映射到宿主机的 物理内存。
资源过订阅问题:
- 多个 VM 的实内存总和可能 > 宿主机实际物理内存。
- VMM 需要维护独立的 交换区 (swap space),负责页的换入换出。
影子页表机制 (Shadow Page Tables)
- 问题:如果直接使用两层映射(虚→实→物),性能会很差。
- 解决方案:影子页表
- 客户 OS 仍维护 虚拟地址 → 实地址 的页表。
- VMM 维护 虚拟地址 → 物理地址 的 影子页表,交由硬件直接使用。
- 机制:
- VMM 虚拟化页表寄存器:客户机切换页表时,VMM 让硬件实际加载影子页表。
- 客户机对页表寄存器的读写会触发陷阱,由 VMM 拦截并维护同步。
- 保证等价性:如果客户 OS 认为某页不可用,影子页表中也必须保持不可用。
- 缺页异常处理:
- 如果客户 OS 已经映射该页 → VMM 从 swap 恢复物理页,更新影子页表。
- 如果客户 OS 未映射该页 → VMM 把缺页异常传递给客户 OS,由其加载 I/O;VMM 再同步更新影子页表。
- I/O 映射问题:
- I/O 操作常用实地址,VMM 必须转换成宿主物理地址。
- 可能涉及非连续页 → VMM 需要拆分请求或提前换页。
Virtualizing an Architected TLB
背景:TLB 是硬件缓存,用来加速地址转换。
问题:当 ISA 采用 软件管理 TLB 时,客户 OS 可能直接写 TLB,这就需要 VMM 进行虚拟化。
方法一:重写物理 TLB
- 每次 VM 切换时,VMM 重写 TLB,把客户的虚拟 TLB 条目翻译后写入物理 TLB。
- 缺点:频繁刷新,开销大。
方法二:ASID 映射机制
- 硬件支持 ASID (Address Space Identifier) → 区分不同地址空间。
- VMM 维护 虚拟 ASID → 物理 ASID 的映射表。
- 多个 VM 的地址空间可以共存于物理 TLB,不必频繁刷新。
- 当客户 OS 写 ASID 寄存器时:VMM 截获,更新虚拟副本,并调整映射关系。
- 例如:两个 VM 都认为自己用 ASID=1,VMM 实际分配给它们不同的物理 ASID,避免冲突。
Resource Virtualization — Input/Output
I/O 虚拟化比 CPU、内存更复杂,因为设备种类多、操作系统抽象不同。基本策略是 构建虚拟设备模型,拦截客户机的 I/O 请求并转发/模拟。
Virtualizing Devices
- 专用设备:如键盘、鼠标、显示器 → 必须分配给特定 VM,VMM 负责转发请求和中断。
- 分区设备:如磁盘 → VMM 把物理磁盘划分成多个虚拟磁盘,维护参数映射(磁道、扇区)。
- 共享设备:如网卡 → 多 VM 共享,VMM 维护虚拟状态(虚拟 MAC/IP),负责路由数据包。
- 缓冲池设备(spooled devices):如打印机 → 客户 OS 先写入 VMM 的缓冲池,由 VMM 统一调度输出。
- 无物理对应的虚拟设备:如虚拟网卡 → 专供 VM 间通信,VMM 拦截 I/O 请求并注入中断。
Virtualizing I/O Activity
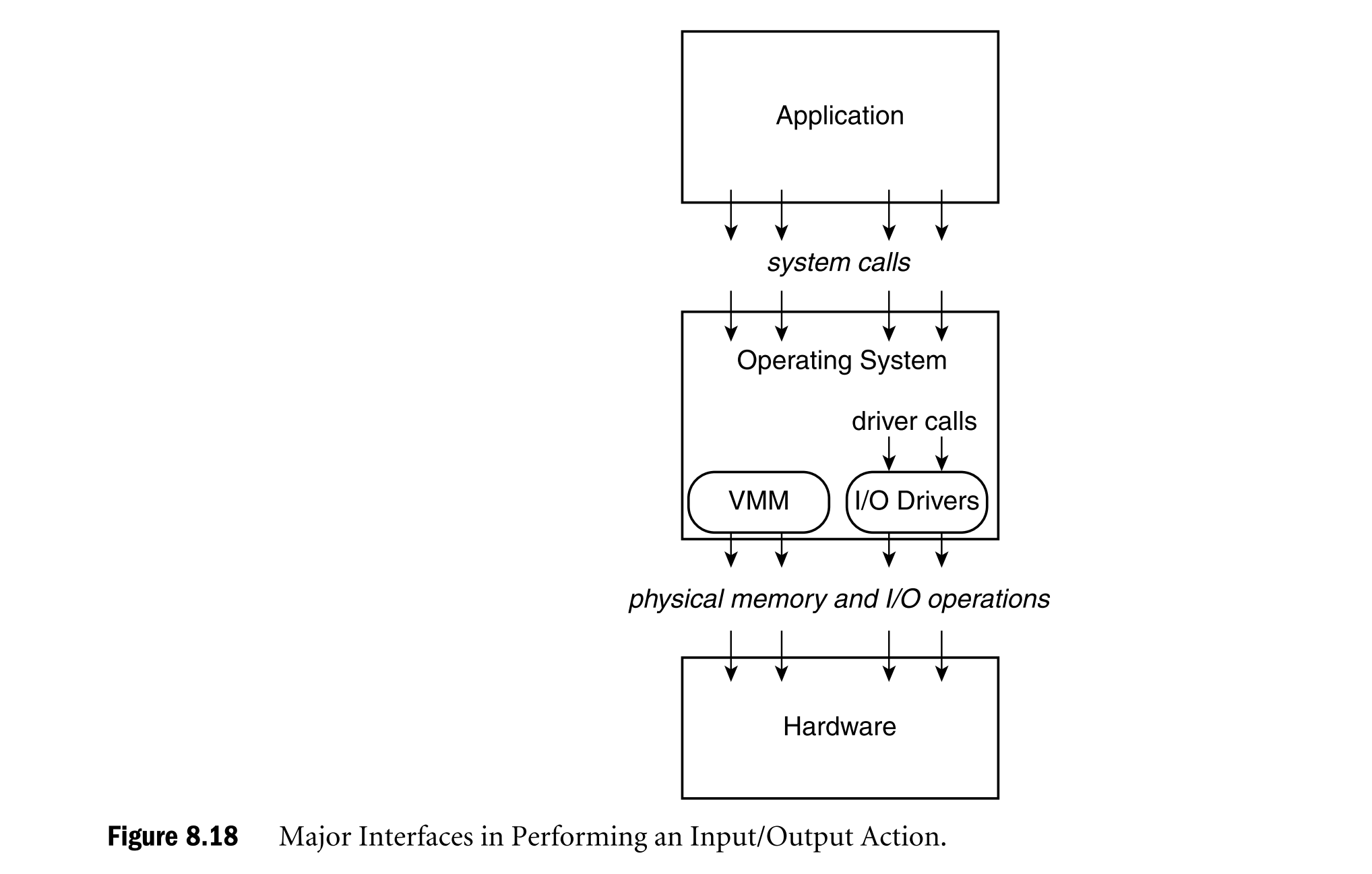
Virtualizing at the I/O Operation Level (操作级虚拟化)
- 机制:
- I/O 操作通过 内存映射 I/O (MMIO) 或 特权 I/O 指令 (如 IA-32 的 in/out, System/360 的 SIO) 来完成。
- 用户态程序不能直接执行这些操作,必须通过系统调用进入内核。
- 在虚拟机中,这些特权操作触发陷阱,交给 VMM 来处理 → 所以 VMM 很容易“截获”到。
- 难点:
- 一次完整 I/O 动作(例如“磁盘读一块”)通常不是一条 I/O 指令完成的,而是由设备驱动发出的 一系列小粒度操作(读写寄存器、加载地址、分段传输)。
- VMM 截获到的只是零散的低级指令,必须 反向推导 (reverse engineer) 才能理解高层 I/O 意图。
- 这种推导非常复杂,在实践中几乎不可行。
📌 总结:截获简单,但难以理解语义。
Virtualizing at the Device Driver Level (驱动级虚拟化)
- 机制:
- 操作系统把系统调用(如
read())转换成 驱动调用,交给设备驱动。 - 如果 VMM 能拦截驱动层接口,就能把 虚拟设备请求 → 物理设备驱动请求。
- 实现方式:
- 为每个客户 OS 提供一套 虚拟设备驱动(例如 VirtualBox/VMware Tools 中的“虚拟网卡/虚拟磁盘驱动”)。
- 安装客户 OS 时,虚拟驱动也会随 VMM 一起安装。
- 操作系统把系统调用(如
- 优点:
- 截获点自然,不必拼凑零碎的 I/O 操作。
- 可以直接利用客户 OS 的抽象层次。
- 缺点:
- 需要对客户 OS 内部接口有了解。
- 对未知/任意 OS 很难做到,但对主流 OS(如 Windows, Linux)是可行的。
- 扩展:
- 在 原生 VM 系统 中,VMM 需要同时拥有 虚拟设备驱动和物理设备驱动。
- 在 托管 VM 系统 中,VMM 可以直接“借用”宿主 OS 的驱动(例如 Linux 的驱动),减少开发成本。
📌 总结:适合常见 OS,开发成本较高,但效果好。
Virtualizing at the System Call Level (系统调用级虚拟化)
- 机制:
- 在 ABI 层直接截获系统调用(例如应用程序的
read())。 - VMM 模拟整个 ABI 接口,由它直接完成 I/O 请求。
- 在 ABI 层直接截获系统调用(例如应用程序的
- 优点:
- 截获在最上层,一次性理解完整的 I/O 意图,不需要反向推导。
- 缺点:
- VMM 必须为每个客户 OS 编写一整套 ABI 模拟库。
- 开发难度极高,因为需要完整理解客户 OS 的系统调用语义,并正确模拟与 OS 其他部分的交互。
- 只有在 客户 OS 结构非常清晰且被深度掌握 的情况下才可能实现。
📌 总结:理论上最简洁,但实际难度最大,几乎只适合非常有限的场景。
网络虚拟化示例
- 场景一:客户VM发送数据包至外部主机。
- 客户OS生成OUTS指令 → VMM截获并转换为目标物理NIC端口指令。
- 数据地址转换至VMM空间,由物理NIC驱动发送。
- 场景二:客户VM间通信。
- VMM识别目标为本地VM,不触发物理信号,直接在内部转发数据包。
- 目标VM的中断处理程序接收数据,实现高效零拷贝通信。
- 可通过VMM内核层重定向进一步提升效率,如z/VM的minidisk缓存减少磁盘I/O。
Input/Output Virtualization and Hosted Virtual Machines
- 托管型 VM:运行在已有宿主操作系统 (host OS) 上,依赖宿主 OS 提供底层服务。
- 与 原生型 VM (native VM) 不同,它不直接管理所有硬件,而是把很多工作交给宿主 OS 完成。
- 优势:省去了 VMM 自己实现完整设备驱动的负担(PC 生态下设备种类繁多,驱动维护难度大)。
为了实现高效虚拟化,托管型 VM 被分成三个主要部分:
- VMM-n (native 部分)
- 运行在硬件的最高特权级(内核态)。
- 类似于原生 VMM 的角色,负责拦截客户机执行的特权指令或关键指令(通过陷阱或补丁)。
- 可能为少数性能关键或宿主 OS 不支持的设备提供专用驱动。
- VMM-u (user 部分)
- 运行在宿主 OS 的用户态,表现为一个普通进程。
- 负责代表 VMM-n 向宿主 OS 发起
资源请求(例如内存分配、I/O 调用),通常调用宿主 OS
的库函数(如
read())。 - 等于把客户机的请求转译为宿主 OS 的请求。
- VMM-d (driver 部分)
- 是安装在宿主 OS 内核中的一个特殊驱动。
- 它让 VMM-n 看起来像宿主 OS 上的一个“设备”,从而使 VMM-u 能与 VMM-n 通信。
- VMM-u 是唯一能访问这个“设备”的用户程序。
4. 优点
- 驱动复用:不需要 VMM 自己维护庞大的驱动库,直接利用宿主 OS 的现有驱动。
- 易部署:用户可以在已有操作系统上快速安装虚拟机系统,非常适合 PC 桌面环境。
5. 缺点
- 安全风险:VMM-n 与宿主 OS 都运行在特权级,彼此可能互相干扰;宿主 OS 并未以 VMM 共存为前提来设计。
- 资源不可控:资源调度完全由宿主 OS 决定,VMM 难以掌握或预测实际资源分配策略。
- 性能损耗:
- 频繁发生 世界切换 (world switch):在 VMM-n 与宿主 OS 之间切换时,需要保存和恢复大量状态。
- 特别是在 I/O 密集型工作负载下,性能下降比 CPU 密集型场景更显著。
Input/Output Virtualization in VM/370
背景:VM/370 是 IBM 的经典系统虚拟机,直接运行在硬件上(原生型 VMM)。
机制:
- 通道 (IOP) + CCW (通道命令字):I/O 操作通过 CCW 链描述。
- 客户机构建 CCW 链 → 执行
SIO→ 陷入 VMM (CP)。 - CP 查影子页表,生成对应的物理 CCW,保证数据页在内存中。
- 如果跨页,要拆分为多个 CCW。
- CP 把 CCW 交给物理设备执行,I/O 完成后通过中断返回,再由 CP 注入到客户机。
优化点:
- spooling:对于慢速设备(如打印机),采用缓冲池,避免阻塞,提高并发。
- 虚拟设备:比如 minidisk,没有直接物理对应,方便资源高效共享。