
操作系统概念
目录
第一章 操作系统基础
第二章 操作系统结构与设计
第三章 进程管理管理
第四章 CPU调度
第五章 进程同步
第一章 操作系统基础
1.1 操作系统的作用
- 用户视图:操作系统的界面因设备而异,如PC、移动设备和嵌入式系统。
- 系统视图:操作系统作为资源分配器和控制程序,管理CPU、内存、I/O设备等资源。
- 定义操作系统:操作系统没有统一定义,但通常指核心内核、中间件框架及系统程序。
1.2 计算机系统组织
1.2.1 中断
- 中断机制用于处理异步事件,通过中断服务例程响应硬件请求。
- 中断优先级机制允许区分高/低优先级中断,确保紧急任务优先处理。
- 中断向量表通过唯一编号索引中断服务例程地址。
1.2.2 存储结构
- 主要存储单元包括寄存器、高速缓存、主存(RAM)、非易失性存储(NVM)和二级存储(硬盘)。
- 存储层次结构按容量与访问时间排序,速度越快的存储越接近CPU。
- 非易失性存储用于保存引导程序和静态数据。
1.2.3 I/O结构
- I/O由设备控制器和驱动程序管理,采用中断或DMA方式减少CPU开销。
- DMA允许设备直接读写内存,仅在传输完成后触发一次中断。
- 高端系统使用交换架构替代总线架构以提高并发性能。
1.3 计算机系统架构
1.3.1 单处理器系统
- 一个通用CPU加上多个专用处理器(如磁盘控制器)组成。
- 专用处理器运行有限指令集,协助主CPU完成特定任务。
1.3.2 多处理器系统
- 对称多处理(SMP)系统中每个CPU执行所有任务,共享内存。
- 多核系统将多个计算核心集成在一个芯片上,提升效率并降低功耗。
- NUMA架构为每个CPU提供本地内存,避免总线竞争瓶颈。
1.3.3 集群系统
- 由多个节点组成的松耦合系统,通过局域网或InfiniBand互联。
- 提供高可用性服务,支持故障转移与负载均衡。
- 并行集群允许多个主机访问共享存储,需特殊软件支持。
1.4 操作系统操作
1.4.1 多道程序设计与多任务处理
- 多道程序设计提高CPU利用率,通过进程切换保持CPU忙碌。
- 多任务系统频繁切换进程,提供快速用户响应。
- 虚拟内存技术使程序可大于物理内存,分离逻辑与物理地址空间。
1.4.2 双模式与多模式操作
- 用户模式与内核模式通过模式位区分,防止非法指令执行。
- 特权指令仅能在内核模式下执行,如I/O控制、定时器管理。
- 支持更多保护级别的架构(如Intel四环模型、ARM七种模式)。
1.4.3 定时器
- 定时器用于防止用户程序无限循环,强制中断返回控制权给操作系统。
- Linux中的HZ参数决定定时中断频率,jiffies记录启动以来的中断次数。
1.5 资源管理
操作系统是资源管理者,负责管理CPU、内存空间、文件存储空间和I/O设备等资源。
1.5.1 进程管理
- 程序在执行时被称为进程。
- 进程需要CPU时间、内存、文件和I/O设备等资源来完成任务。
- 单线程进程只有一个程序计数器,多线程进程有多个程序计数器。
- 进程是系统中的工作单元,分为操作系统进程(执行系统代码)和用户进程(执行用户代码)。
- 操作系统负责创建和删除进程、调度进程和线程、挂起和恢复进程、提供进程同步和通信机制。
1.5.2 内存管理
- 主存是计算机系统操作的核心,必须将程序映射到绝对地址并加载到内存中才能执行。
- 多道程序设计要求系统保持多个程序在内存中,以提高CPU利用率和响应速度。
- 操作系统负责跟踪内存使用情况、分配和释放内存空间、决定哪些进程和数据应调入或调出内存。
1.5.3 文件系统管理
- 操作系统提供统一的逻辑视图,将文件抽象为逻辑存储单元。
- 文件可以代表程序和数据,组织成目录结构便于管理。
- 操作系统负责创建和删除文件与目录、支持文件操作原语、将文件映射到物理存储介质,并进行备份。
1.5.4 存储设备管理
- 操作系统需有效管理二级存储(如硬盘)和三级存储(如磁带)。
- 管理功能包括挂载与卸载、空闲空间管理、存储分配、磁盘调度、分区和保护。
- 三级存储用于长期备份和不常用数据存储,由操作系统或应用程序管理。
1.5.5 缓存管理
- 缓存通过复制信息到更快的存储系统中提升性能。
- 寄存器、高速缓存、主存、固态硬盘和磁盘构成存储层次结构。
- 缓存大小和替换策略影响性能,操作系统控制数据在不同层级之间的移动。
- 在多任务和多处理器环境中,需确保缓存一致性。
1.5.6 I/O系统管理
- 操作系统隐藏硬件设备细节,通过I/O子系统管理缓冲、缓存、假脱机。
- 设备驱动程序负责特定硬件的操作。
- 操作系统处理中断、设备控制寄存器访问和I/O完成检测。
1.6 安全与保护
- 多用户和多进程环境下需调节对数据的访问。
- 保护机制防止未经授权的进程操作资源,如内存地址限制、定时器防止无限循环。
- 安全机制防御外部和内部攻击,如病毒、拒绝服务攻击、身份盗用。
- 用户身份识别通过用户名和用户ID实现,支持用户组权限管理。
- 特权升级机制允许临时获取更高权限,如UNIX的setuid属性。
1.7 虚拟化
- 虚拟化技术将单个计算机硬件抽象为多个执行环境。
- 支持在同一台机器上运行多个操作系统,如Windows和UNIX。
- 虚拟机管理器(VMM)负责资源管理和隔离虚拟机。
- 虚拟化广泛应用于服务器、桌面和数据中心,提高资源利用率和灵活性。
1.8 分布式系统
- 分布式系统是由网络连接的多个独立计算机组成的集合。
- 提供资源共享、提高计算速度、数据可用性和可靠性。
- 网络按协议、节点距离和传输介质分类,如局域网(LAN)、广域网(WAN)。
- 网络操作系统提供文件共享和进程通信功能;分布式操作系统提供单一系统外观。
1.9 内核数据结构
- 操作系统广泛使用链表、栈、队列、树、哈希表和位图等数据结构。
1.9.1 列表、栈和队列
- 链表支持动态插入和删除,适用于变长数据。
- 栈采用后进先出(LIFO)原则,常用于函数调用。
- 队列采用先进先出(FIFO)原则,常用于打印作业和任务调度。
1.9.2 树
- 树结构表示数据层次关系,二叉搜索树支持高效查找。
- 平衡二叉搜索树(如红黑树)用于Linux调度算法。
1.9.3 哈希函数与映射
- 哈希函数将数据映射为索引,实现快速检索。
- 哈希冲突通过链表解决,常用于密码验证等场景。
1.9.4 位图
- 位图用于高效表示大量资源状态,如磁盘块可用性。
1.10 计算环境
- 操作系统适应多种计算环境,包括传统计算、移动计算、客户端-服务器、点对点、云计算和实时嵌入式系统。
1.10.1 传统计算
- 包括PC、服务器、网络和远程访问。
- 时间分片技术允许多用户共享系统资源。
1.10.2 移动计算
- 手持设备如智能手机和平板电脑。
- 支持多媒体、GPS定位、加速度传感器等功能。
- Android和iOS为主流移动操作系统。
1.10.3 客户端-服务器计算
- 服务器满足客户端请求,分为计算服务器和文件服务器。
1.10.4 点对点计算
- 所有节点平等,可同时作为客户端和服务器。
- 优势在于去中心化,避免服务器瓶颈。
1.10.5 云计算
- 提供计算、存储和应用作为服务,基于虚拟化技术。
- 包括公有云、私有云、混合云及SaaS、PaaS、IaaS模式。
1.10.6 实时嵌入式系统
- 用于汽车引擎、医疗设备等,具有严格的时间约束。
- 实时系统需在限定时间内完成处理,否则导致失败。
1.11 自由与开源操作系统
- 开源软件提供源代码,允许自由使用、修改和分发。
- GNU/Linux、BSD UNIX、Solaris为典型开源系统。
1.11.1 历史
- 早期软件附带源代码,后逐渐转向闭源。
- Richard Stallman发起GNU项目,倡导自由软件理念。
1.11.2 自由操作系统
- 自由软件强调用户自由而非价格,保障四项基本自由。
1.11.3 GNU/Linux
- Linux内核结合GNU工具形成完整操作系统。
- 多种发行版如Red Hat、Ubuntu、Debian等。
1.11.4 BSD UNIX
- 衍生于AT&T UNIX,发展出FreeBSD、NetBSD等多个版本。
- 提供完整的源代码,支持开发者研究和定制。
1.11.5 Solaris
- Sun Microsystems开发的商业UNIX系统。
- OpenSolaris开源项目衍生出Project Illumos。
1.11.6 开源系统作为学习工具
- 开源项目促进学生理解操作系统原理,参与开发和改进。
1.12 总结
- 操作系统管理硬件资源,提供应用程序运行环境。
- 中断机制协调硬件与CPU交互,主存为直接访问唯一存储。
- 多道程序设计和多任务提升CPU利用率和响应速度。
- 用户模式与内核模式区分权限,保障系统安全。
- 进程是操作系统的基本工作单元,涉及创建、调度、同步和通信。
- 内存管理、文件系统、存储设备和缓存优化系统性能。
- 保护与安全机制防止非法访问,虚拟化技术提升资源利用率。
- 数据结构支撑操作系统功能实现,适应多样计算环境。
- 自由与开源系统推动教育与技术创新。#### 第一章练习
- 1.12 集群系统与多处理器系统的区别在于集群由多个独立节点组成,通过网络通信协作;而多处理器系统共享内存和总线。要实现高可用服务,集群需要心跳机制、故障检测、数据复制和自动故障转移。
- 1.13 数据库集群的两种管理方式包括共享磁盘(所有节点访问同一存储)和主从复制(一个节点写,其他节点读)。前者提供一致性但存在单点故障风险;后者提高可用性但可能有数据同步延迟。
- 1.14 中断用于响应外部事件(如I/O完成),由硬件触发;陷阱是软件产生的异常或系统调用。用户程序可以有意生成陷阱以请求操作系统服务(如系统调用)。
- 1.15 Linux中HZ表示每秒时钟中断次数,jiffies记录自启动以来的中断总数。通过jiffies / HZ可计算出系统运行的秒数。
- 1.16 a.
CPU通过DMA控制器设置源地址、目标地址和传输长度来协调数据传输。
- 1.16 b. DMA完成后会触发中断通知CPU操作结束。
- 1.16 c. DMA允许CPU并发执行其他任务,不会直接干扰用户程序,但在内存带宽竞争激烈时可能导致性能下降。
- 1.17 没有硬件特权模式仍可通过软件仿真、解释执行或虚拟机监控器构造安全操作系统,但效率低且安全性依赖于软件实现,难以完全替代硬件支持。
- 1.18 多级缓存设计是为了平衡速度与容量:本地缓存速度快但容量小,适合私有数据;共享缓存容量大但访问延迟稍高,适合多核间共享数据。
- 1.19 存储系统按速度排序为:磁带 < 光盘 < 硬盘 < 非易失性存储 < 主存 < 缓存 < 寄存器。
- 1.20 示例:在SMP系统中,两个核心各自缓存同一内存变量,若其中一个修改了值但未同步,则另一核心看到的是旧值。
- 1.21 a.
单处理器中缓存一致性问题出现在不同指令阶段对同一数据的访问。
- 1.21 b.
多处理器中每个核心有自己的缓存,需通过协议(如MESI)保持一致性。
- 1.21 c. 分布式系统中数据分布于不同节点,需使用一致性算法(如Paxos、Raft)保证全局一致性。
- 1.22 内存保护机制包括分段与分页,结合基址与界限寄存器限制程序访问范围,利用MMU进行地址转换并检查权限,防止非法访问。
- 1.23 a. 校园学生活动中心适合LAN配置。
- 1.23 b. 跨校区大学系统适合WAN连接。
- 1.23 c. 居民小区适合LAN或WLAN配置。
- 1.24 移动设备操作系统需考虑电池寿命、屏幕尺寸、触控输入、传感器集成、应用沙箱化及频繁更新需求,相比传统PC更注重资源优化与安全性。
- 1.25 P2P系统无需中央服务器,具有更高的容错性、负载均衡能力和扩展性,适用于文件共享、流媒体、分布式计算等场景。
- 1.26 适合P2P系统的应用包括BitTorrent文件共享、Skype语音通信、IPFS分布式文件系统、区块链网络等。
- 1.27 开源操作系统的优点包括透明性(开发者喜欢)、可定制性(高级用户喜欢)、低成本(中小企业喜欢);缺点包括技术支持不足(普通用户困扰)、碎片化(企业IT管理困难)、安全更新滞后(安全专家担忧)。
第二章 操作系统结构与设计
2.1 操作系统服务
- 提供用户界面(GUI、触摸屏、命令行)。
- 程序执行:加载和运行程序,正常或异常终止。
- I/O操作:读写文件或设备,需通过操作系统控制。
- 文件系统管理:创建/删除/读取/写入文件,设置权限。
- 通信:共享内存或消息传递,支持进程间或跨机器通信。
- 错误检测:处理硬件、I/O设备及程序错误,并采取适当措施。
- 资源分配:为多个进程分配CPU周期、内存、外设等资源。
- 日志记录:用于计费、统计资源使用情况。
- 保护与安全:防止非法访问系统资源,要求用户身份验证。
2.2 用户与操作系统接口
- 命令解释器(Shell):
- 如UNIX/Linux的bash、C Shell,Windows的cmd。
- 可通过系统程序实现命令(如rm)。
- 图形用户界面(GUI):
- 使用窗口、菜单、图标,如macOS的Aqua、Windows的Explorer。
- 开源桌面环境包括KDE和GNOME。
- 触摸屏接口:
- 适用于移动设备,如iPhone的Springboard、Android的触控交互。
- 接口选择:
- 高级用户倾向CLI,普通用户偏好GUI。
- CLI可通过脚本自动化重复任务。
2.3 系统调用
- 系统调用作用:
- 提供应用程序与操作系统之间的接口。
- 实现对文件、进程、设备、通信等的操作。
- 示例流程:
- 如复制文件涉及open()、read()、write()、close()等系统调用。
- 应用编程接口(API):
- Windows API、POSIX API、Java API。
- API函数通常封装系统调用。
- 参数传递方式:
- 寄存器、堆栈、内存块。
- 系统调用分类:
- 进程控制:create(), terminate(), wait(), signal()等。
- 文件管理:open(), read(), write(), delete()等。
- 设备管理:request(), release(), read(), write()等。
- 信息维护:get_time(), set_time(), get_process_attributes()等。
- 通信:send(), receive(), pipe(), socket()等。
- 保护:chmod(), chown(), set_permissions()等。
2.4 系统服务
- 文件管理:创建、删除、复制、编辑文件。
- 状态信息:获取时间、内存、磁盘空间、用户数等。
- 文件修改:提供文本编辑器和搜索工具。
- 编程语言支持:编译器、调试器、解释器(如C/C++、Java、Python)。
- 程序加载与执行:绝对加载器、可重定位加载器、链接编辑器。
- 通信:虚拟连接、网络服务、远程登录、邮件传输。
- 后台服务(守护进程):
- 如网络服务、定时任务、打印服务器。
- Linux中称为daemon,Windows中称为service。
2.5 链接器与加载器
- 编译过程:
- 源代码 → 目标文件(relocatable) → 链接生成可执行文件。
- 链接器功能:
- 合并目标文件与库,解决符号引用。
- 加载器功能:
- 将可执行文件加载到内存并启动执行。
- 动态链接:
- 允许在运行时加载库(如Windows的DLL、Linux的.so)。
- ELF格式:
- Executable and Linkable Format,定义可执行文件结构。
- 包含入口地址、段表、符号表等信息。
2.6 应用为何依赖操作系统
- 不同操作系统差异:
- 系统调用接口不同。
- 可执行文件格式不同(如Windows PE、macOS Mach-O)。
- CPU指令集不同(如x86 vs ARM)。
- 跨平台解决方案:
- 解释型语言(Python、Ruby)。
- 虚拟机(如Java JVM)。
- 标准化API(如POSIX)。
- ABI(应用二进制接口):
- 定义参数传递方式、栈布局、数据类型大小等底层细节。
- 不同ABI之间不兼容,限制跨平台能力。
2.7 操作系统设计与实现
- 设计目标:
- 用户视角:易用、快速、可靠。
- 开发者视角:易维护、灵活、高效。
- 机制与策略分离:
- 机制决定如何实现,策略决定做什么。
- 微内核将策略与机制解耦,增强灵活性。
- 实现语言:
- 多数操作系统使用C/C++,部分关键代码用汇编。
- Android示例:内核用C+ASM,系统库用C/C++,框架用Java。
- 优势:
- 开发效率高、易于移植、便于优化。
- 劣势:
- 性能略低,但现代编译器和硬件优化弥补此问题。
2.8 操作系统结构
- 单体结构(Monolithic):
- 所有功能集中在内核,如早期UNIX。
- 优点:性能高;缺点:难以维护。
- 分层结构(Layered):
- 分层模块化设计,如THE OS。
- 优点:结构清晰;缺点:效率低。
- 微内核(Microkernel):
- 内核仅提供基础机制(如进程管理、通信),其他服务作为用户进程。
- 如Minix、QNX、Mach。
- 优点:稳定性好、扩展性强;缺点:性能开销大。
- 模块化结构(Modular):
- 支持动态加载内核模块(如Linux的loadable kernel modules)。
- 混合结构(Hybrid):
- 结合微内核与单体内核特性,如Windows NT、macOS XNU。
- Android架构:
- 基于Linux内核,系统库用C/C++,应用框架用Java。
- 采用Binder进行IPC通信。#### 第二章 操作系统结构(续)
2.8 操作系统结构
- 单体结构:
- 所有功能集中在单一地址空间中,如UNIX和早期Linux。
- 优点:性能高;缺点:难以维护和扩展。
- 分层结构:
- 将操作系统划分为多个层次,每一层仅使用下层提供的服务。
- 优点:便于调试与验证;缺点:性能较差,接口定义复杂。
- 微内核结构:
- 核心功能最小化,其余服务作为用户态进程运行。
- 优点:可移植性好、稳定性强;缺点:消息传递开销大,影响性能。
- 模块化结构:
- 支持动态加载/卸载内核模块,如Linux的LKM。
- 提供灵活性和良好的性能平衡。
- 混合结构:
- 结合单体内核与模块化设计,如Windows NT、macOS XNU。
- 平衡性能与可维护性。
2.9 构建与启动操作系统
- 操作系统生成步骤:
- 编写或获取源代码 → 配置系统 → 编译 → 安装 → 启动。
- 系统配置方式:
- 修改源码重新编译,或从库中链接预编译模块。
- Linux构建流程:
- 下载源码 → 使用make menuconfig配置 → 编译内核与模块 → 安装并重启。
- 虚拟机安装选项:
- 可使用ISO镜像快速部署,或使用预配置虚拟机镜像。
2.9.2 系统启动过程
- BIOS/UEFI引导流程:
- 引导程序定位并加载内核 → 初始化硬件 → 挂载根文件系统。
- 多阶段引导:
- BIOS加载MBR中的boot loader,再加载完整操作系统。
- UEFI优势:
- 支持更大磁盘、64位系统,集成完整引导管理器。
- GRUB引导器:
- 支持参数设置、多内核选择、内核参数修改。
- Android启动流程:
- 使用LK引导器,initramfs作为根文件系统。
- 恢复模式支持:
- 所有主流系统均提供恢复或单用户模式用于诊断修复。
2.10 操作系统调试
- 故障分析:
- 内核崩溃时保存内存状态至专用区域,重启后生成core dump。
- 用户进程失败时记录日志并生成core文件供调试。
- 性能监控工具:
- Linux:ps、top、vmstat、iostat、netstat。
- Windows:任务管理器。
- 追踪工具:
- strace、gdb、perf、tcpdump。
- BCC工具集:
- 基于eBPF实现动态内核追踪,提供Python接口。
- 示例工具:disksnoop、opensnoop,支持实时生产环境监控。
2.11 总结
- 操作系统核心功能:
- 提供程序执行环境,通过系统调用接口为用户提供服务。
- 系统调用分类:
- 进程控制、文件管理、设备管理、信息维护、通信、保护。
- 应用依赖原因:
- 可执行格式差异(PE/Mach-O/ELF)、指令集不同、系统调用不兼容。
- 操作系统结构演进:
- 单体 → 分层 → 微内核 → 模块化 → 混合结构。
- 启动机制:
- 引导程序负责加载内核、初始化硬件、挂载根文件系统。
- 调试与性能优化:
- 使用计数器与追踪工具进行系统行为分析,BCC/eBPF提供高效内核级追踪能力。#### 第四章 编程项目
4.1 Linux内核模块简介
- 本项目介绍如何创建并加载内核模块到Linux内核。
- 模块可在/proc文件系统中添加条目。
- 使用虚拟机完成实验,需通过终端编译程序并管理模块。
4.2 内核模块概述
- 使用
lsmod命令查看当前加载的内核模块。 simple.c示例模块在加载和卸载时输出信息。simple_init():模块加载时调用,返回整数表示成功或失败。simple_exit():模块卸载时调用,无返回值。
- 使用
printk()函数输出日志信息,可通过dmesg查看。 - 注册模块入口和出口点:
module_init(simple_init)module_exit(simple_exit)
- 模块元信息:
MODULE_LICENSE("GPL")MODULE_DESCRIPTION("Simple Module")MODULE_AUTHOR("SGG")
4.3 加载与卸载内核模块
- 编译模块使用
make命令,生成simple.ko文件。 - 加载模块使用
sudo insmod simple.ko。 - 卸载模块使用
sudo rmmod simple。 - 使用
dmesg查看模块加载和卸载日志。 - 清空日志缓冲区使用
sudo dmesg -c。
4.4 扩展功能练习
- 在模块中调用内核提供的常量和函数:
GOLDEN_RATIO_PRIME:定义在<linux/hash.h>。gcd()函数:定义在<linux/gcd.h>,用于计算最大公约数。
- 输出
HZ和jiffies变量:HZ:定时器中断频率,定义在<asm/param.h>。jiffies:系统启动以来的中断次数,定义在<linux/jiffies.h>。
4.5 /proc文件系统模块
/proc文件系统是伪文件系统,用于查询内核和进程状态。- 创建
/proc/hello文件示例(hello.c):- 使用
proc_create()创建文件。 - 定义读取操作函数
proc_read()。
- 使用
proc_read()函数实现:- 将“Hello World”写入内核缓冲区。
- 使用
copy_to_user()将数据复制到用户空间。 - 控制只输出一次,避免重复读取。
4.6 实验任务
- 设计两个内核模块:
- 创建
/proc/jiffies文件:- 读取时显示当前
jiffies值。 - 模块卸载时删除该文件。
- 读取时显示当前
- 创建
/proc/seconds文件:- 显示自模块加载以来经过的秒数。
- 使用
jiffies和HZ进行换算(秒数 = jiffies / HZ)。 - 模块卸载时删除该文件。
- 创建
第三章 进程管理
3.1 进程概念
3.1.1 进程
- 进程是正在执行的程序。
- 程序是被动实体,进程是主动实体。
- 内存布局包括:
- 文本段(可执行代码)
- 数据段(全局变量)
- 堆段(动态分配内存)
- 栈段(函数调用临时数据)
- 程序变为进程需加载到内存。
- 同一程序可运行多个进程实例。
3.1.2 进程状态
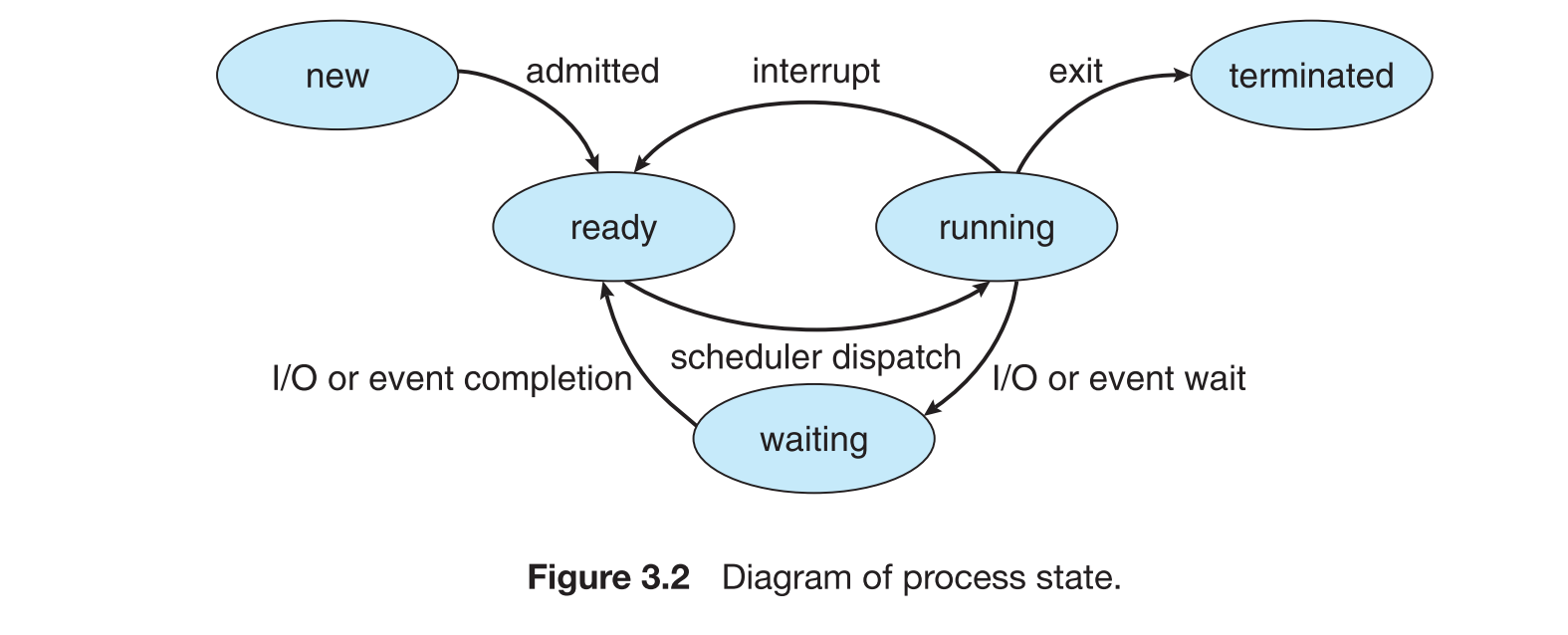
- 进程状态包括:
- 新建(new)
- 就绪(ready)
- 运行(running)
- 等待(waiting)
- 终止(terminated)
- 多个进程可处于就绪或等待状态,但仅一个进程在运行。
3.1.3 进程控制块(PCB)
Process Control Block
PCB(进程控制块)是操作系统用于管理每个“进程”的一个数据结构。每当创建一个进程时,系统就会生成一个对应的 PCB,记录它的所有相关信息。
PCB 是操作系统核心管理进程的关键数据结构,必须受保护,防止用户程序直接访问或修改。
因此,PCB 存放在内核态专用的内存区域,只有操作系统内核代码能够访问。
即使你用
sudo(以管理员权限运行用户命令),你获得的是用户态的超级用户权限,而不是直接内核态权限。
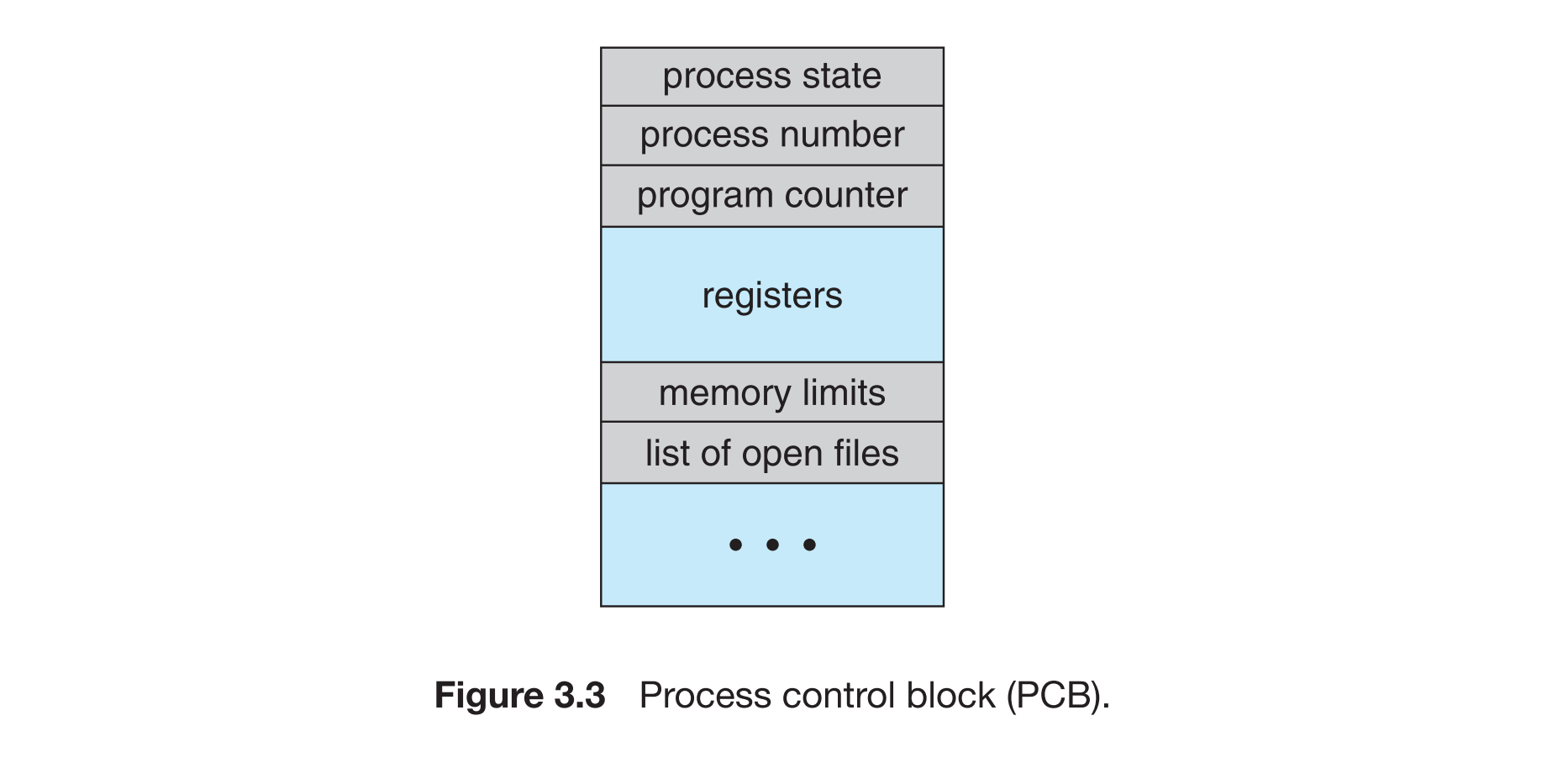
- 每个进程由PCB表示,包含以下信息:
- 进程状态
- 程序计数器
- CPU寄存器
- 调度信息
- 内存管理信息
- I/O状态信息
3.1.4 线程
- 单线程进程只能顺序执行一个任务。
- 多线程进程可并发执行多个任务。
- 支持多核并行处理,提升性能。
- PCB扩展以支持每个线程的信息。
3.2 进程调度
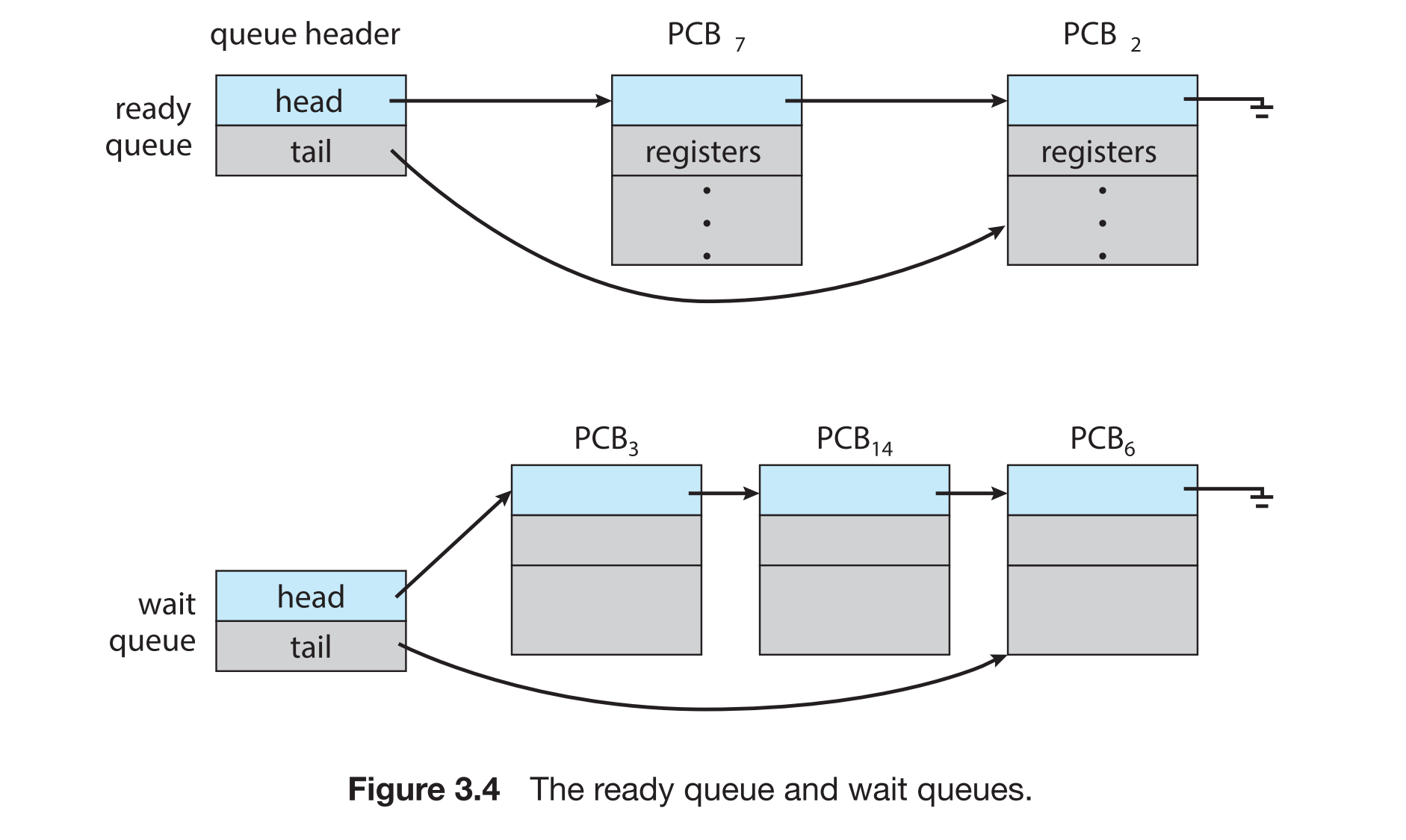
3.2.1 调度队列
- 就绪队列:准备运行的进程。存放已准备好运行但尚未分配 CPU 的进程(也叫就绪进程)。通常是链表结构,头结点指向第一个 PCB(进程控制块)
- 等待队列:等待事件完成的进程。存放正在等待某个事件发生(如 I/O 完成、子进程结束、时钟中断等)的进程。每类事件都有自己的等待队列。
- 队列结构为链表,每个PCB含指针指向下一个PCB。
3.2.2 CPU调度
调度器的职责:
从就绪队列中选择一个进程
把它分配给一个 CPU 核心执行
决定何时切换(即上下文切换)
目标是最大化CPU利用率和实现时间分片。
CPU调度器从就绪队列选择进程执行。
I/O密集型与CPU密集型进程行为不同。
多核系统可同时运行多个进程。
3.2.3 上下文切换
上下文切换是操作系统在多个进程或线程之间切换执行的过程。每次切换,系统必须保存当前进程的执行状态,并恢复下一个进程的状态。
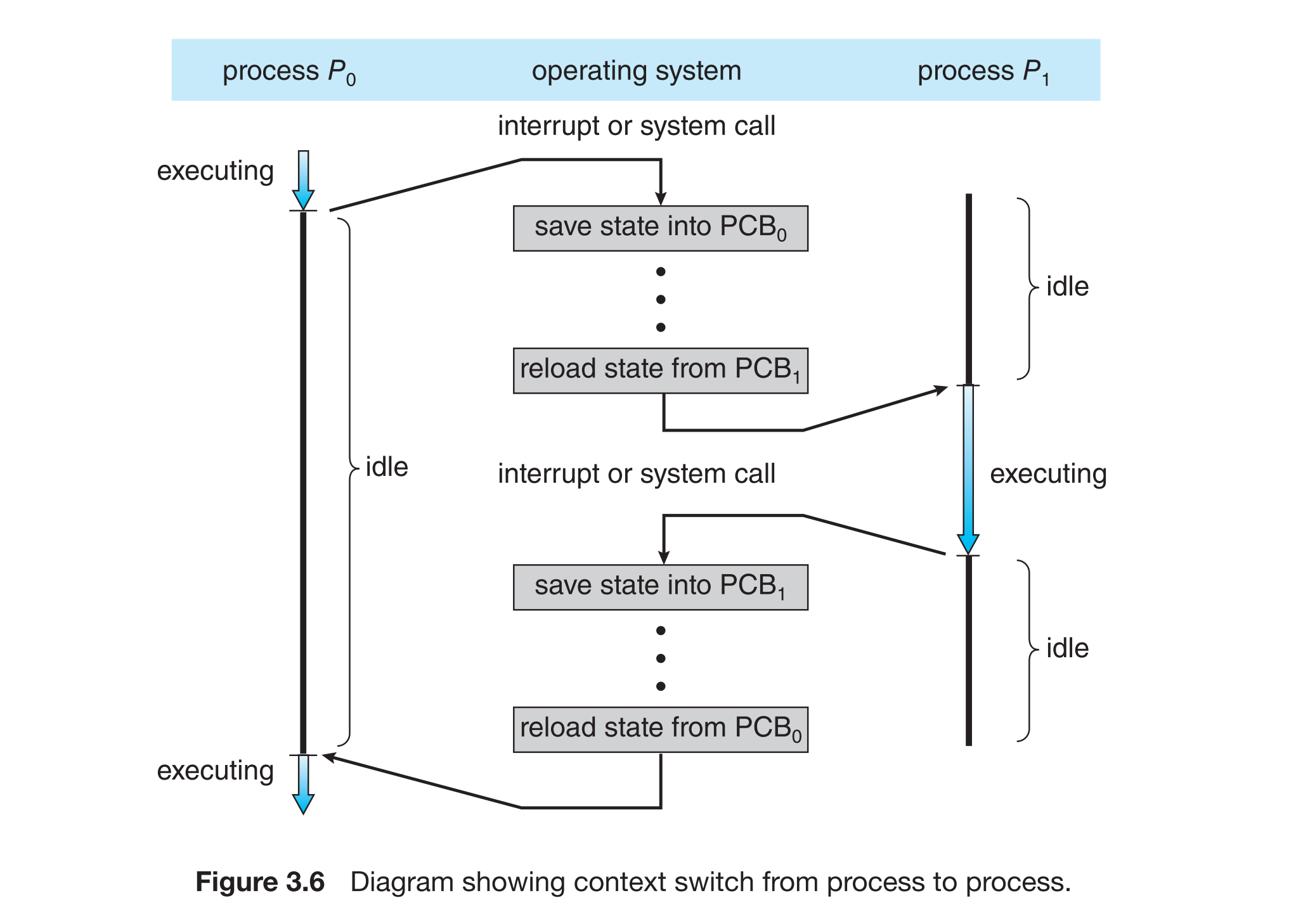
- 中断导致当前进程上下文保存至PCB。
- 切换过程包括:
- 保存旧进程上下文
- 加载新进程上下文
- 上下文切换纯属开销,无实际工作。
- 切换速度依赖硬件支持和操作系统复杂度。
3.3 进程操作
3.3.1 进程创建
- 父进程创建子进程,形成进程树。
- 子进程获取资源:CPU时间、内存、文件、I/O设备。
- UNIX使用fork()创建子进程,随后可用exec()替换地址空间。
- Windows使用CreateProcess()创建新进程。
3.3.2 进程终止
- 进程通过exit()系统调用结束。
- 父进程可通过wait()获取子进程退出状态。
- 子进程资源被回收,若父进程未调用wait()则成为僵尸进程。
- 若父进程终止,init/systemd接管孤儿进程。
Android进程层次
- 进程按重要性排序,优先级从高到低:
- 前台进程(用户交互)
- 可见进程(前台引用)
- 服务进程(后台可见)
- 后台进程(非可见)
- 空进程(无活动组件)
- 系统优先终止空进程,然后是后台进程等。
3.4 进程间通信(IPC)
- 独立进程不共享数据,合作进程共享数据。
- 提供IPC的原因:
- 信息共享
- 计算加速(多核并行)
- 模块化设计
3.5 共享内存模型下的IPC
- 进程建立共享内存区域进行通信。
- 生产者-消费者问题示例:
- 使用循环缓冲区(bounded buffer)
- in和out指针管理缓冲区读写
- 同步机制防止同时访问冲突
3.6 消息传递模型下的IPC
- 不共享地址空间,通过send()和receive()交换消息。
- 适用于分布式系统。
- 支持直接通信(命名对方)或间接通信(通过邮箱/端口)。
3.6.1 命名方式
- 直接通信:
- send(P, message)
- receive(Q, message)
- 间接通信:
- send(A, message) 发送到邮箱A
- receive(A, message) 从邮箱A接收
3.6.2 同步方式
- 阻塞发送/接收(同步)
- 非阻塞发送/接收(异步)
- 阻塞发送+阻塞接收实现同步 rendezvous
3.6.3 缓冲机制
- 零容量:发送方必须等待接收方接收。
- 有界容量:最多n条消息,满时发送方阻塞。
- 无界容量:发送方永不阻塞。### 第三章 进程管理(续)
3.7 IPC系统示例
3.7.1 POSIX共享内存
- 使用内存映射文件组织共享内存。
- shm_open() 创建共享内存对象。
- ftruncate() 设置共享内存大小。
- mmap() 建立内存映射,实现共享内存访问。
- 示例程序展示生产者写入 “Hello World!”,消费者读取并输出。
3.7.2 Mach消息传递
- Mach是专为分布式系统设计的操作系统,也用于macOS和iOS。
- 任务间通信通过端口(Port)进行,支持单向、有限长度的消息队列。
- mach_msg() 是发送和接收消息的标准API。
- 支持简单消息(用户数据)和复杂消息(含内存指针或端口权限传输)。
- 利用虚拟内存技术避免消息复制,提升性能。
3.7.3 Windows
- Windows使用ALPC(高级本地过程调用)机制进行进程通信。
- 通信分为三种方式:
- 小消息(≤256字节)直接复制到端口队列。
- 大消息通过共享内存段(Section Object)传递。
- 超大消息允许服务器直接读写客户端地址空间。
- ALPC由系统内部使用,应用程序通过RPC间接调用。
3.7.4 管道(Pipes)
3.7.4.1 普通管道(Ordinary Pipes)
- 单向通信:一端写入,另一端读取。
- UNIX使用pipe()创建,fd[0]为读端,fd[1]为写端。
- 通常用于父子进程间通信。
- 若需双向通信,需使用两个管道。
- Windows称其为匿名管道,使用CreatePipe()创建。
3.7.4.2 命名管道(Named Pipes)
- 支持跨无亲缘关系进程通信。
- UNIX中称为FIFO,使用mkfifo()创建。
- 可持续存在,直到被显式删除。
- Windows命名管道支持全双工通信,可跨机器使用。
- 使用CreateNamedPipe()创建,ConnectNamedPipe()连接。
3.8 客户端-服务器系统通信
3.8.1 套接字(Sockets)
- 套接字是网络通信的端点,由IP+端口号唯一标识。
- 典型服务端口:SSH(22)、FTP(21)、HTTP(80)。
- Java提供Socket类(TCP)、DatagramSocket类(UDP)及MulticastSocket类。
- 示例:日期服务器与客户端通过Socket交换当前时间。
3.8.2 远程过程调用(RPC)
- RPC抽象了函数调用机制,适用于网络环境。
- 消息包含调用函数名、参数、返回值。
- 参数编组(Marshaling)解决不同机器的数据表示差异(如大端/小端)。
- XDR(外部数据表示)定义平台无关的数据格式。
- 语义保证:“最多一次”(At Most Once)和“恰好一次”(Exactly Once)。
- 绑定方式:
- 静态绑定:固定端口号。
- 动态绑定:通过匹配服务(Matchmaker)获取端口号。
3.8.2.1 Android中的RPC
- Android使用Binder框架实现IPC,支持RPC。
- Service组件可通过bindService()绑定,并提供远程接口。
- AIDL(Android接口定义语言)生成Stub和服务接口。
- 客户端调用远程方法时,Binder自动处理参数编组、进程间传输及结果返回。
3.9 总结
- 进程是正在执行的程序,具有文本段、数据段、堆、栈。
- 进程状态包括就绪、运行、等待、终止。
- PCB记录进程状态、寄存器、调度信息等。
- fork() 和 CreateProcess() 分别用于UNIX和Windows创建进程。
- 共享内存(POSIX API)、消息传递(Mach、Windows)、管道(普通/命名)是常见IPC方式。
- 套接字和RPC用于客户端-服务器通信。
- Android使用Binder框架支持RPC作为IPC机制。### 第三章 进程管理(续)
3.7 进程调度与上下文切换
- 上下文切换时,内核保存当前进程状态至PCB。
- 恢复下一个进程的上下文以继续执行。
- 包括程序计数器、寄存器、内存管理信息等。
- 切换速度受硬件和操作系统机制影响。
3.8 进程树与系统工具
- 使用
ps -ael查看UNIX/Linux进程树。 - Windows可用Process Monitor查看进程父子关系。
- init/systemd负责回收孤儿进程资源。
3.9 进程创建与终止
- fork() 创建子进程,exec() 替换地址空间。
- wait() 系统调用用于父进程等待子进程结束。
- 子进程未被wait()回收将变为僵尸进程。
- 父进程结束后,init/systemd接管孤儿进程。
3.10 进程数量计算示例
- 图中程序循环4次调用fork(),共创建15个子进程(包括初始进程)。
3.11 IPC通信方式比较
- 普通管道适用于父子进程间临时通信。
- 命名管道支持无亲缘关系进程通信。
- RPC若不保证“最多一次”或“恰好一次”语义可能导致重复请求或丢失。
3.12 共享内存与消息传递
- 共享内存实现高效数据交换,但需同步机制。
- 消息传递适用于分布式系统,提供更高抽象层次。
- 同步方式:阻塞/非阻塞发送与接收。
- 缓冲机制:零容量、有界容量、无界容量。
3.13 编程问题解析
3.18 创建僵尸进程
- 子进程退出后父进程不调用wait()。
- 可通过
ps -l查看Z状态确认。 - 使用kill命令终止父进程可清除僵尸进程。
3.19 测量命令执行时间
- 使用共享内存或管道在父子进程间传输开始时间。
- gettimeofday()获取微秒级时间戳。
- 父进程等待子进程结束并计算时间差。
3.20 PID管理器
- 定义PID范围为300~5000。
- 使用位图表示PID使用状态。
- 实现allocate_map(), allocate_pid(), release_pid()接口。
3.21 Collatz猜想多进程实现
- 子进程生成序列并输出。
- 父进程调用wait()等待子进程完成。
- 需验证输入是否为正整数。
3.22 使用共享内存优化Collatz程序
- 父进程创建共享内存区域。
- 子进程写入序列数据。
- 父进程读取并输出,使用wait()同步。
3.23~3.25 网络服务实现
- 修改日期服务器为“每日一句”服务器,监听端口6017。
- 实现Haiku诗歌服务器,监听端口5575。
- 编写回声服务器,使用InputStream处理二进制数据。
3.26~3.27 管道通信编程
- 设计双管道实现字符串大小写反转通信。
- filecopy.c使用管道复制文件内容。
- 父进程写入管道,子进程读取并写入目标文件。#### 编程项目
- 项目目标:设计一个C程序作为shell接口,支持命令执行、输入输出重定向、管道通信。
项目1:UNIX Shell
- 功能要求:
- 接收用户命令并创建子进程执行。
- 支持后台运行(使用&符号)。
- 支持命令历史(!!执行上一条命令)。
- 支持输入输出重定向(< 和 >)。
- 支持管道通信(|)。
- 使用系统调用:
- fork():创建子进程。
- execvp():执行命令。
- wait():等待子进程结束。
- dup2():重定向标准输入输出。
- pipe():建立进程间管道。
- 程序结构:
- main()函数循环读取命令、解析参数、执行命令。
- 支持命令参数数组解析(args)。
- 支持错误处理(如无历史命令时输入!!)。
项目2:Linux内核模块显示任务信息
- 功能:
- 通过写入/proc/pid获取进程信息。
- 读取/proc/pid显示命令名、PID、状态。
- 关键函数:
- proc_write():接收用户写入的PID。
- pid_task():通过PID获取task_struct。
- copy_from_user(), kstrtol():用户空间数据处理。
- 内存管理:
- kmalloc() / kfree():分配和释放内核内存。
- 注意防止内存泄漏。
项目3:Linux内核模块列出所有任务
部分一:线性遍历任务
- 使用宏for_each_process()遍历所有任务。
- 输出每个任务的命令名、状态、PID。
- 模块加载时输出到内核日志(dmesg查看)。
- 与ps -el命令对比验证。
部分二:深度优先遍历任务树
- 使用init_task作为根节点。
- 使用children和sibling字段遍历进程树。
- 使用list_for_each()宏遍历子进程链表。
- 输出任务信息并与ps -eLf对比验证。
项目4:内核数据结构
部分一:链表操作
- 定义结构体struct color,包含红、蓝、绿三色值。
- 使用Linux内核链表结构struct list_head。
- 实现链表操作:
- LIST_HEAD():定义链表头。
- INIT_LIST_HEAD():初始化节点。
- list_add_tail():尾部插入节点。
- list_for_each_entry():遍历链表。
- list_del():删除节点。
- list_for_each_entry_safe():安全删除遍历。
- 模块加载时创建并输出四个颜色节点;卸载时释放内存。
部分二:模块参数传递
- 使用module_param()传递整型参数。
- 示例:insmod collatz.ko start=15。
- 默认值设置:start=25。
- 生成Collatz序列并存储在链表中。
- 加载时输出序列,卸载时清理内存。
3.2 进程操作
3.3.2 进程终止
- 进程执行完最后一条指令后通过 exit() 系统调用请求操作系统删除它。
- 终止时,进程可返回状态值给父进程(通过 wait() 系统调用)。
- 操作系统回收进程的所有资源(内存、文件、I/O 缓冲区等)。
- 进程可通过 TerminateProcess() 等系统调用被其他进程终止。
- 父进程可因以下原因终止子进程:
- 子进程超过资源配额。
- 子进程任务不再需要。
- 父进程退出,操作系统不允许子进程继续存在。
- 如果父进程未调用 wait() 就退出,子进程会变成“孤儿进程”,init 或 systemd 会接管这些进程并调用 wait() 回收它们。
- 已终止但未被父进程调用 wait() 的进程称为“僵尸进程”。
3.3.2.1 Android 进程层级
- Android 根据资源重要性对进程进行分类,系统终止进程时优先结束重要性较低的进程。
- 进程分类(从高到低):
- 前台进程(用户当前交互的应用)。
- 可见进程(非前台但被前台引用的进程)。
- 服务进程(如音乐播放)。
- 后台进程(用户不可见但运行任务的进程)。
- 空进程(无活跃组件的进程)。
- Android 会尽量赋予进程尽可能高的优先级。
- 开发者应遵循进程生命周期规范,以实现状态保存和恢复。
3.4 进程间通信(IPC)
3.4.1 IPC 的基本模型
- 进程可分为独立进程(不共享数据)和协作进程(共享数据)。
- 协作进程需通过 IPC 机制进行通信,主要有两种模型:
- 共享内存模型:多个进程访问同一内存区域进行数据交换。
- 消息传递模型:进程通过发送和接收消息进行通信。
3.4.2 Chrome 浏览器的多进程架构
- Chrome 使用多进程架构隔离网页内容,防止一个网页崩溃影响整个浏览器。
- 主要进程类型:
- 浏览器进程:管理 UI、磁盘和网络 I/O。
- 渲染器进程:处理 HTML、JavaScript、图像等。
- 插件进程:运行 Flash、QuickTime 等插件。
- 渲染器进程运行在沙箱中,限制对系统资源的访问。
3.5 共享内存中的 IPC
3.5.1 共享内存通信机制
- 协作进程需建立共享内存区域,其他进程将其附加到自己的地址空间。
- 共享内存通信速度快,但需要进程自行同步访问。
- 示例:生产者-消费者问题使用共享内存实现。
- 共享缓冲区使用循环数组,in 和 out 指针管理。
- 生产者等待缓冲区不满,消费者等待缓冲区不空。
- 代码实现需注意并发访问同步问题。
3.5.2 POSIX 共享内存 API
- 使用 shm_open() 创建共享内存对象。
- 使用 ftruncate() 设置共享内存大小。
- 使用 mmap() 将共享内存映射到进程地址空间。
- 示例:生产者写入 “Hello World!”,消费者读取并输出。
3.6 消息传递系统中的 IPC
3.6.1 命名机制
- 进程通信可采用直接通信(明确指定发送者或接收者)或间接通信(通过邮箱或端口)。
- 直接通信:send(P, message)、receive(Q, message),通信链路自动建立。
- 间接通信:通过邮箱(Mailbox)收发消息,多个进程可共享邮箱。
- 邮箱可由进程或操作系统拥有,操作系统需提供创建、发送、接收、删除邮箱的机制。
3.6.2 同步机制
- send() 和 receive() 可为阻塞或非阻塞:
- 阻塞发送:发送进程等待消息被接收。
- 非阻塞发送:发送进程立即返回。
- 阻塞接收:接收进程等待消息到达。
- 非阻塞接收:接收进程获取有效消息或空值。
- 若 send() 和 receive() 均为阻塞,则形成“同步握手”。
3.6.3 缓冲机制
- 消息队列可实现为三种方式:
- 零容量:发送者必须等待接收者接收消息。
- 有限容量:最多 n 个消息,满时发送者等待。
- 无限容量:发送者永不等待。
- 零容量称为无缓冲消息系统,其他称为自动缓冲系统。
3.7 IPC 系统示例
3.7.1 POSIX 共享内存
- 使用内存映射文件实现共享内存。
- 示例:生产者写入共享内存,消费者读取并输出。
3.7.2 Mach 消息传递
- Mach 操作系统支持任务(类似进程)间的消息传递。
- 消息通过端口(Port)收发,端口为单向,支持双向通信需两个端口。
- 每个端口有端口权限(Port Rights),如 MACH_PORT_RIGHT_RECEIVE。
- 使用 mach_msg() 实现消息发送和接收。
3.7.3 Windows IPC
- Windows 使用 ALPC(高级本地过程调用)机制进行进程间通信。
- ALPC 支持三种消息传递方式:
- 小消息(≤256 字节)直接复制。
- 大消息通过共享内存段(Section Object)传输。
- 超大消息允许服务器直接读写客户端地址空间。
- ALPC 不是公开 API,应用程序通过 RPC 调用间接使用。
3.7.4 管道(Pipes)
3.7.4.1 普通管道(Ordinary Pipes)
- UNIX 和 Windows 都支持普通管道,用于父子进程间单向通信。
- UNIX 使用 pipe() 创建管道,读写端分别用 fd[0] 和 fd[1]。
- Windows 使用 CreatePipe() 创建匿名管道,需设置 SECURITY_ATTRIBUTES 和 STARTUPINFO。
3.7.4.2 命名管道(Named Pipes)
- 命名管道可在不同进程间通信,无需父子关系。
- UNIX 命名管道称为 FIFO,使用 mkfifo() 创建。
- Windows 命名管道支持全双工通信,使用 CreateNamedPipe() 创建。
3.8 客户端-服务器系统中的通信
3.8.1 套接字(Sockets)
- 套接字提供跨网络的进程间通信机制。
- 支持 TCP(面向连接)和 UDP(无连接)协议。
- 套接字编程接口包括 socket()、bind()、listen()、accept()、connect()、send()、recv() 等函数。
3.8.2 远程过程调用(RPC)
- RPC 允许程序调用远程主机上的过程,如同本地调用一样。
- RPC 系统自动处理通信细节,如参数打包、网络传输、结果返回。
- Windows 使用 ALPC 优化本地 RPC 调用。#### 3.8 客户端-服务器系统中的通信
- 套接字(Socket)是一个通信端点,通常使用客户端-服务器架构。
- 套接字由IP地址和端口号组成,服务器监听特定端口以接收客户端请求。
- 所有低于1024的端口被认为是知名端口,用于标准服务(如SSH、FTP、HTTP)。
- 客户端发起连接时会被分配一个大于1024的随机端口,确保连接唯一。
- 示例说明了使用Java实现的日期服务器和客户端,使用TCP套接字进行通信。
- 套接字通信虽然高效,但属于低级通信方式,仅支持无结构的字节流。
3.8.1 套接字
- Java提供了三种类型的套接字:Socket(TCP)、DatagramSocket(UDP)和MulticastSocket。
- 示例展示了使用ServerSocket和Socket类实现的日期服务器。
- 客户端通过Socket连接到服务器并读取返回的日期信息。
- 使用IP地址127.0.0.1(回环地址)可以实现本机客户端与服务器通信。
3.8.2 远程过程调用(RPC)
- RPC是一种抽象的远程服务机制,允许客户端像调用本地函数一样调用远程函数。
- 每个RPC消息包含目标函数标识和参数,通过端口与RPC守护进程通信。
- 参数编组(marshaling)解决客户端与服务器之间数据表示差异问题。
- 使用外部数据表示(XDR)实现机器无关的数据格式。
- RPC调用语义包括“最多一次”和“恰好一次”两种,分别处理网络错误导致的重复调用问题。
- “恰好一次”需要服务器确认调用已执行,客户端持续重试直到收到确认。
- 客户端与服务器之间的绑定可以通过固定端口或通过“会合机制”动态获取端口实现。
3.8.2.1 Android中的RPC
- Android使用Binder框架支持RPC,允许进程间通信。
- 应用组件Service可通过绑定实现客户端-服务器通信。
- 使用AIDL(Android接口定义语言)定义远程接口,并生成Stub文件。
- 客户端通过bindService()绑定服务,并调用远程方法。
- Android内部处理参数编组、跨进程传递、调用服务实现并返回结果。
3.9 小结
- 进程是正在执行的程序,状态由程序计数器和其他寄存器表示。
- 进程在内存中分为四个部分:文本段、数据段、堆和栈。
- 进程状态包括就绪、运行、等待和终止。
- 进程控制块(PCB)是操作系统中表示进程的数据结构。
- 进程调度器负责选择可用进程在CPU上运行。
- 上下文切换发生在切换运行进程时。
- fork()和CreateProcess()分别用于在UNIX和Windows中创建进程。
- 共享内存允许多个进程共享同一内存区域。
- 消息传递是进程间通信的另一种方式,Mach和Windows都支持。
- 管道(Pipe)提供两个进程之间的通信通道,分为普通管道和命名管道。
- UNIX使用pipe()系统调用创建普通管道,命名管道称为FIFO。
- Windows提供匿名管道和命名管道,后者功能更强大。
- 客户端-服务器通信常用方式包括套接字和远程过程调用(RPC)。
- Android使用Binder框架支持RPC作为进程间通信机制。#### 编程项目
- 项目1—UNIX Shell:设计一个C程序作为Shell接口,支持用户命令的输入、执行、输入输出重定向和管道通信。
- 使用系统调用如fork()、exec()、wait()、dup2()和pipe()。
- 支持后台运行命令(使用&符号)。
- 实现命令历史功能,用户可通过!!执行最近一次命令。
- 支持输入输出重定向(> 和 < 操作符)。
- 实现进程间通信(使用管道|操作符)。
- 项目2—Linux内核模块用于显示任务信息:编写内核模块,通过/proc/pid文件显示任务的命令名、PID和状态。
- 用户通过echo写入PID,通过cat读取任务信息。
- 使用kstrtol()将字符串转换为整数,使用proc_write()函数处理写入。
- 使用task_struct结构获取任务信息。
- 项目3—Linux内核模块用于列出所有任务:通过for_each_process()宏线性遍历任务。
- 使用深度优先搜索(DFS)遍历任务树,从init_task开始遍历子进程。
- 输出任务的命令名、状态和PID,并与ps命令结果对比验证。
- 项目4—内核数据结构:使用Linux内核提供的链表结构实现颜色结构的插入、遍历和删除。
- 使用LIST_HEAD()定义链表头,INIT_LIST_HEAD()初始化链表成员。
- 使用list_add_tail()添加节点,list_for_each_entry()遍历链表。
- 使用list_del()删除节点,并用kfree()释放内存。
- 模块入口中创建四个颜色结构节点并输出到日志,模块出口中删除节点并释放内存。
- 参数传递部分:通过insmod传递参数给内核模块,如初始值start=15。
- 内核模块使用module_param()声明参数,生成Collatz序列并存储在链表中。
- 模块加载时生成并输出序列,模块卸载时清理链表内存。### 线程与并发
第四章 CPU调度
- 线程是CPU调度的基本单位,包括线程ID、程序计数器、寄存器集合和栈。
- 同一进程的线程共享代码段、数据段、打开的文件和信号等资源。
- 多线程进程可以同时执行多个任务,例如浏览器同时显示内容和下载数据。
- 在多核系统中,多线程可充分利用多个CPU核心提升性能。
- 使用多线程的Web服务器可以同时处理多个客户端请求,提高效率。
- Linux内核本身也使用多线程处理设备管理、内存管理和中断处理等任务。
4.1.1 动机
- 图像处理应用可为每张图片生成缩略图使用单独线程。
- 浏览器可使用不同线程进行网络数据下载和内容显示。
- 文字处理软件可使用多个线程分别处理图形显示、键盘响应和拼写检查。
- 多线程Web服务器可创建多个线程处理请求,而无需创建新进程,节省资源。
4.1.2 优势
- 响应性:多线程应用在执行耗时操作时仍能保持用户界面响应。
- 资源共享:线程默认共享进程资源,便于在同一个地址空间中实现多任务。
- 经济性:线程创建和上下文切换比进程更节省时间和内存。
- 可扩展性:多线程在多核系统中可真正实现并行执行,提升性能。
4.2 多核编程
- 单核系统中线程是并发执行(时间交错),多核系统中可实现真正的并行执行。
- 并发表示多个任务交替执行,而并行表示多个任务同时执行。
4.2.1 编程挑战
- 任务识别:将应用划分为可并行执行的独立任务。
- 负载均衡:确保各任务工作量均衡,避免资源浪费。
- 数据划分:将任务处理的数据分割以支持并行。
- 数据依赖:确保任务间数据依赖关系正确同步。
- 测试调试:多线程程序的执行路径复杂,测试和调试难度大。
4.2.2 并行类型
- 数据并行:将相同数据的不同子集分配到不同核心处理,如数组求和。
- 任务并行:将不同任务分配到不同核心处理,如对同一数组执行不同统计操作。
- 实际应用中常结合数据并行和任务并行策略。
4.3 多线程模型
- 线程可在用户空间或内核空间实现。
- 用户线程由线程库管理,内核线程由操作系统直接管理。
4.3.1 多对一模型
- 多个用户线程映射到一个内核线程,线程管理效率高。
- 但一个线程阻塞会导致整个进程阻塞,且无法在多核上并行执行。
- 早期的Green线程库采用此模型。
4.3.2 一对一模型
- 每个用户线程对应一个内核线程,允许线程阻塞时其他线程继续执行。
- 支持多核并行,但大量线程可能影响系统性能。
- Linux和Windows采用此模型。
4.3.3 多对多模型
- 多个用户线程映射到少量或等量的内核线程,支持灵活的并发执行。
- 不受线程数量限制,适合多核系统。
- 有些系统支持两层模型,允许用户线程绑定到内核线程。
- 实际实现复杂,多数系统仍采用一对一模型。
4.4 线程库
- 线程库提供创建和管理线程的API。
- 线程库可在用户空间或内核空间实现。
4.4.1 POSIX线程(Pthreads)
- Pthreads是POSIX标准定义的线程API,可实现为用户级或内核级线程。
- 示例程序使用pthread_create创建线程,pthread_join等待线程结束。
- 可使用循环等待多个线程完成。
4.4.2 Windows线程
- Windows线程库使用CreateThread创建线程,WaitForSingleObject等待线程结束。
- 支持等待多个线程的WaitForMultipleObjects函数。
4.4.3 Java线程
- Java线程基于Thread类或Runnable接口实现。
- 使用Lambda表达式简化线程创建语法。
- Java线程通过join()方法等待线程完成。
- Java Executor框架提供更高级的线程管理功能。
Java Executor框架
- Executor接口提供execute方法执行任务。
- ExecutorService扩展Executor,支持任务提交和线程池管理。
- Callable接口支持返回结果的任务,Future对象用于获取结果。
- 示例程序使用Callable实现数组求和,ExecutorService执行任务。
4.5 隐式线程
- 隐式线程将线程创建和管理交给编译器和运行库,开发者只需识别可并行任务。
4.5.1 线程池
- 线程池在启动时创建多个线程并放入池中,按需分配任务。
- 优点包括快速响应请求、限制线程数量、支持不同任务调度策略。
- Windows和Java均提供线程池支持。
Java线程池
- Java的Executors类提供newSingleThreadExecutor、newFixedThreadPool和newCachedThreadPool三种线程池。
- 示例程序使用newCachedThreadPool创建线程池并执行任务。
4.5.2 Fork-Join模型
- Fork-Join模型通过分治算法将任务拆分为子任务并行执行。
- Java的ForkJoinPool实现该模型,支持递归任务拆分。
- 示例程序使用ForkJoinPool计算数组求和。
Java中的Fork-Join
- ForkJoinTask是抽象基类,RecursiveTask返回结果,RecursiveAction不返回结果。
- SumTask类实现RecursiveTask,compute方法执行分治计算。
- THRESHOLD参数决定何时直接计算而非继续拆分任务。
4.5.3 OpenMP
- OpenMP是一组用于C/C++/FORTRAN的编译指令和API,支持共享内存环境下的并行编程。
- 使用#pragma omp parallel指令创建线程,线程数由系统核心数决定。
- 支持并行化循环,如#pragma omp parallel for。
4.5.4 Grand Central Dispatch(GCD)
- GCD是Apple开发的并发技术,结合运行库、API和语言扩展。
- 任务通过dispatch队列调度,分为串行队列和并发队列。
- 并发队列分为四个服务质量等级:用户交互、用户发起、实用工具、后台。
- 使用Block或Closure定义任务,dispatch_async提交任务。
4.5.5 Intel线程构建模块(TBB)
- TBB是C++模板库,支持并行编程,无需特殊编译器支持。
- 提供parallel_for等模板实现并行循环。
- 自动划分任务并负载均衡,优先执行缓存命中任务。
- 提供线程安全的数据结构如并发哈希表、队列和向量。#### 4.6 线程问题
- 在多线程程序设计中需要考虑多个问题,包括系统调用、信号处理、线程取消、线程局部存储和调度激活等。
4.6.1 fork() 和 exec() 系统调用
fork()创建新进程时,在多线程程序中需决定是否复制所有线程或仅复制调用线程。- 一些 UNIX 系统提供两个版本的
fork(),一个复制所有线程,另一个仅复制调用线程。 exec()会替换整个进程(包括所有线程),因此若在fork()后立即调用exec(),仅复制调用线程即可;否则应复制所有线程。
4.6.2 信号处理
- 信号用于通知进程某个事件发生,分为同步信号(如非法内存访问)和异步信号(如
终止进程)。 - 多线程程序中,信号可被发送到特定线程、所有线程、某些线程或指定线程。
- 同步信号应发送给引发信号的线程,异步信号通常发送给未阻塞该信号的第一个线程。
- POSIX 提供
pthread_kill()函数将信号发送到指定线程,Windows 使用异步过程调用(APC)模拟信号。
4.6.3 线程取消
- 线程取消包括异步取消(立即终止线程)和延迟取消(线程周期性检查是否应终止)。
- 异步取消可能导致资源无法释放或数据不一致,因此推荐使用延迟取消。
- Pthreads 提供
pthread_cancel()取消线程,并支持三种取消模式:禁用、延迟取消和异步取消。 - 默认使用延迟取消,通过
pthread_testcancel()检查是否收到取消请求,并可在取消时调用清理函数释放资源。 - Java 中通过
interrupt()方法设置中断状态,线程通过isInterrupted()检查中断状态并响应取消请求。
4.6.4 线程局部存储 (TLS)
- 线程局部存储允许每个线程拥有独立的数据副本,适用于每个线程需维护独立状态的场景。
- TLS 与局部变量不同,其作用域跨越多个函数调用。
- Java 使用
ThreadLocal<T>类实现 TLS,Pthreads 使用pthread_key_t,C# 使用[ThreadStatic],gcc 使用thread关键字。
4.6.5 调度激活
- 多对多和两级线程模型中需要内核与线程库通信,通过轻量级进程(LWP)协调用户线程与内核线程。
- 调度激活机制允许内核通知应用程序线程阻塞或唤醒事件,确保线程调度高效。
- 当线程阻塞时,内核分配新 LWP 并运行上行调用处理程序保存阻塞线程状态,调度其他线程运行。
4.7 操作系统示例
4.7.1 Windows 线程
- Windows 使用一对一模型,每个用户线程对应一个内核线程。
- 线程结构包括线程 ID、寄存器集、程序计数器、用户栈和内核栈、私有存储区。
- 主要数据结构为 ETHREAD(线程控制块)、KTHREAD(内核线程块)和 TEB(线程环境块)。
4.7.2 Linux 线程
- Linux 使用
clone()系统调用创建线程,通过标志位控制父子任务的资源共享程度。 clone()可创建类似进程或线程的任务,未设置标志时行为等同于fork()。- Linux 将线程和进程统称为任务,使用
struct task_struct表示每个任务。 clone()的灵活性支持容器技术,允许创建隔离的 Linux 系统实例。
4.8 小结
- 线程是 CPU 调度的基本单位,共享进程资源如代码和数据。
- 多线程应用的四大优势:响应性、资源共享、经济性和可扩展性。
- 多线程程序设计挑战包括任务划分、数据共享、依赖识别和调试。
- 数据并行和任务并行分别用于分布式数据和任务。
- 线程库如 Windows、Pthreads 和 Java 提供线程创建和管理 API。
- 隐式线程通过线程池、fork-join 框架等机制简化并发编程。
- 线程取消支持异步和延迟两种方式,推荐使用延迟取消。
- Linux 不区分线程和进程,使用
clone()实现灵活的任务创建。## 第四章 CPU调度
5.1 基本概念
5.1.1 CPU–I/O突发周期
- 进程执行由CPU执行和I/O等待交替组成。
- 大多数CPU突发时间较短,少数较长,分布呈指数或超指数形式。
- I/O密集型程序有大量短CPU突发,CPU密集型程序有少量长CPU突发。
5.1.2 CPU调度器
- 当CPU空闲时,调度器从就绪队列中选择一个进程执行。
- 就绪队列可以是FIFO、优先队列、树或无序链表。
- 队列中的记录通常是进程控制块(PCB)。
5.1.3 抢占式与非抢占式调度
- 调度决策发生在进程状态转换时。
- 非抢占式调度仅在进程等待或终止时调度,抢占式调度可在任何时间中断进程。
- 现代系统如Windows、Linux、UNIX等使用抢占式调度。
- 抢占可能导致竞态条件和内核设计复杂性。
5.1.4 分派器
- 分派器将CPU控制权交给调度器选中的进程。
- 包括上下文切换、切换到用户模式、跳转到用户程序恢复执行。
- 分派延迟是指分派器停止一个进程并启动另一个进程所需的时间。
5.2 调度准则
- CPU利用率:尽可能保持CPU忙碌,通常在40%到90%之间。
- 吞吐量:单位时间内完成的进程数量。
- 周转时间:从进程提交到完成的总时间。
- 等待时间:在就绪队列中等待的时间。
- 响应时间:从请求提交到首次响应的时间。
- 目标是最大化CPU利用率和吞吐量,最小化周转时间、等待时间和响应时间。
5.3 调度算法
5.3.1 先来先服务调度(FCFS)
- 最简单的调度算法,使用FIFO队列。
- 平均等待时间可能较长。
- 可能导致“车队效应”,降低CPU和设备利用率。
- 非抢占式,适用于批处理系统,不适用于交互式系统。
5.3.2 最短作业优先调度(SJF)
- 最优调度算法,最小化平均等待时间。
- 需要知道下一次CPU突发时间,实际中不可实现。
- 使用指数平均预测下一次CPU突发时间。
- 可分为抢占式(最短剩余时间优先)和非抢占式。
5.3.3 轮转调度(RR)
- 类似FCFS,但加入时间片(时间量子)机制。
- 时间片通常为10到100毫秒。
- 抢占式调度,确保公平分配CPU时间。
- 平均等待时间较长,但适用于交互式系统。
- 时间片大小影响性能:过大退化为FCFS,过小导致频繁上下文切换。
5.3.4 优先级调度
- SJF是优先级调度的特例,优先级由预测的CPU突发时间决定。
- 可分为抢占式和非抢占式。
- 存在“无限阻塞”或“饥饿”问题,可通过“老化”机制解决。
- 优先级可由内部或外部因素定义。
5.3.5 多级队列调度
- 将进程按类型分到不同队列,每个队列可有不同调度算法。
- 队列之间调度通常采用固定优先级抢占式调度。
- 例如:前台进程(交互式)使用RR,后台进程(批处理)使用FCFS。
5.3.6 多级反馈队列调度
- 允许进程在不同队列间移动,根据CPU突发行为调整优先级。
- 短CPU突发进程保留在高优先级队列,长CPU突发进程降级。
- 防止饥饿,通过老化机制提升低优先级进程优先级。
- 参数包括队列数量、每个队列的调度算法、进程升级/降级方法等。
5.4 线程调度
5.4.1 竞争范围
- 用户级线程调度(PCS):在线程库内部调度,竞争发生在同一进程内的线程之间。
- 内核级线程调度(SCS):由操作系统调度,竞争发生在系统内所有线程之间。
- 多对一和多对多模型使用PCS,一对一模型(如Windows、Linux)使用SCS。
5.4.2 Pthread调度
- POSIX Pthread API支持设置竞争范围为PTHREAD_SCOPE_PROCESS(PCS)或PTHREAD_SCOPE_SYSTEM(SCS)。
- 使用pthread_attr_setscope和pthread_attr_getscope函数设置和获取调度策略。
- Linux和macOS仅支持PTHREAD_SCOPE_SYSTEM。
5.5 多处理器调度
5.5.1 多处理器调度方法
- 非对称多处理(AMP):单一主处理器处理所有调度和I/O,其他处理器执行用户代码。
- 对称多处理(SMP):每个处理器自我调度,共享就绪队列或各自私有队列。
- 私有队列减少锁竞争,但需负载均衡算法保持负载均衡。
5.5.2 多核处理器
- 多核处理器在单一芯片上集成多个核心,每个核心相当于一个逻辑CPU。
- 多线程核心通过硬件线程提升性能,减少内存等待时间。
- 细粒度和粗粒度多线程技术不同,影响调度策略。
- 操作系统需考虑线程在逻辑CPU上的调度和核心内硬件线程的调度。
5.5.3 负载均衡
- 负载均衡确保所有处理器负载均衡,提高系统吞吐量。
- 推迁移(push migration):定期检查并迁移线程。
- 拉迁移(pull migration):空闲处理器主动从繁忙处理器拉取线程。
- Linux CFS调度器和FreeBSD ULE调度器同时使用推和拉迁移。
5.5.4 处理器亲和性
- 线程在特定处理器上运行后,缓存数据被填充,称为“热缓存”。
- 迁移线程需清空缓存并重新填充,代价高。
- 操作系统尽量避免线程迁移,保持“处理器亲和性”。
- 软亲和性:尽量保持线程在同处理器运行,但不保证。
- 硬亲和性:通过系统调用指定线程可在哪些处理器上运行。
- NUMA系统中,线程应尽量在本地内存访问快的处理器上运行。
5.5.5 异构多处理
- 异构多处理(HMP)使用不同性能和功耗的核心(如ARM big.LITTLE架构)。
- 高性能核心用于短时间高负载任务,低功耗核心用于长时间后台任务。
- Windows 10支持根据任务需求选择调度策略。#### 5.6 实时CPU调度
- 实时系统分为软实时系统和硬实时系统,软实时系统不保证关键进程的调度时间,硬实时系统必须在截止时间前完成任务。
- 事件延迟包括中断延迟和调度延迟,中断延迟是中断到达至服务程序开始的时间,调度延迟是调度器停止当前进程并启动新进程的时间。
- 实时系统需最小化延迟,硬实时系统要求中断延迟和调度延迟必须被严格限制。
- 优先级调度算法是实时系统的核心,支持抢占式调度,高优先级进程可抢占低优先级进程。
- 周期性任务具有固定的处理时间、截止时间和周期,调度器根据任务的截止时间或速率分配优先级。
- 抢占式优先级调度仅能保证软实时功能,硬实时系统还需额外的调度机制确保任务在截止时间前完成。
5.6.3 速率单调调度
- 速率单调调度基于静态优先级,任务周期越短优先级越高。
- 示例:P1周期50,处理时间20;P2周期100,处理时间35,总CPU利用率为75%。若P2优先级高于P1,会导致P1错过截止时间;若P1优先级更高,则两者均可按时完成。
- 速率单调调度是最优算法,若一组进程不能通过此算法调度,则无法通过其他静态优先级算法调度。
- 但存在局限性:CPU利用率受限,N个进程的最差利用率为N(2^(1/N)−1),随着进程数量增加,利用率下降。
5.6.4 最早截止时间优先调度
- 最早截止时间优先(EDF)调度动态分配优先级,截止时间越早优先级越高。
- 示例:P1周期50,处理时间25;P2周期80,处理时间35,总CPU利用率为94%。在速率单调调度下P2会错过截止时间,但在EDF调度下两者均可按时完成。
- EDF调度不依赖任务周期性,仅需任务宣布截止时间,理论上可达到100%的CPU利用率,但实际受上下文切换和中断处理影响。
5.6.5 比例共享调度
- 比例共享调度将T份时间分给所有应用,每个应用获得N份时间,确保其获得N/T的处理器时间。
- 示例:总份额T=100,A分配50份,B分配15份,C分配20份,分别获得50%、15%、20%的CPU时间。
- 需结合准入控制策略,确保应用获得分配的时间份额,若新进程请求的份额不可用,则拒绝其进入系统。
5.6.6 POSIX实时调度
- POSIX标准定义了两种实时调度类:SCHED_FIFO(先来先服务)和SCHED_RR(轮转法)。
- SCHED_FIFO按FIFO队列调度,无同优先级时间片划分;SCHED_RR提供同优先级时间片划分。
- 提供API获取和设置调度策略:pthread_attr_getschedpolicy() 和 pthread_attr_setschedpolicy()。
5.7 操作系统示例
5.7.1 示例:Linux调度
- Linux调度基于调度类,CFS(完全公平调度器)为默认调度算法。
- CFS使用虚拟运行时间(vruntime)决定任务调度顺序,优先级高的任务vruntime增长较慢。
- Linux支持实时调度,采用POSIX标准,实时任务优先级高于普通任务,分为0-99(实时)和100-139(普通)两个优先级范围。
- 支持负载均衡,基于调度域结构平衡负载,考虑NUMA架构减少线程迁移带来的内存访问延迟。
5.7.2 示例:Windows调度
- Windows采用抢占式优先级调度,32级优先级方案,16-31为实时类,1-15为变量类。
- 提供API设置进程优先级类(如NORMAL、HIGH、REALTIME等)和线程相对优先级(如NORMAL、HIGHEST、TIME_CRITICAL等)。
- 线程时间片用尽后优先级降低,等待I/O后优先级提升,增强交互线程响应。
- Windows 7引入用户模式调度(UMS),应用程序可独立创建和管理线程,提升效率。
5.7.3 示例:Solaris调度
- Solaris支持六种调度类:时间共享(TS)、交互(IA)、实时(RT)、系统(SYS)、公平共享(FSS)、固定优先级(FP)。
- 时间共享类动态调整优先级,高优先级用于交互进程,低优先级用于CPU密集型进程。
- 实时类优先级最高,确保任务在截止时间内完成;系统类用于内核线程。
- 调度器将类内优先级转换为全局优先级,选择最高优先级线程运行。
5.8 算法评估
5.8.1 确定性建模
- 确定性建模使用特定工作负载评估算法性能,计算平均等待时间等指标。
- 示例:FCFS平均等待时间28ms,SJF为13ms,RR为23ms,SJF最优。
- 优点:简单快速,提供精确数字;缺点:仅适用于特定输入,需精确数据。
5.8.2 排队模型
- 排队模型基于CPU和I/O突发的概率分布,计算平均吞吐量、等待时间等。
- Little公式:n = λ×W,表示队列长度、到达率和等待时间的关系。
- 优点:适用于动态工作负载;缺点:数学复杂,假设独立性可能不准确。
5.8.3 模拟
- 使用模拟器建模系统,记录调度性能数据。
- 数据来源:随机生成或实际系统测量(如trace文件)。
- 优点:更准确,可重复测试;缺点:计算资源消耗大,设计复杂。
5.8.4 实现
- 在真实系统中实现调度算法并测试,最准确但成本高。
- 需修改操作系统代码,进行回归测试确保稳定性。
- 用户行为可能影响调度效果,需动态调整参数适应不同应用场景。
5.9 总结
- CPU调度选择等待队列中的进程并分配CPU,调度算法分为抢占式和非抢占式。
- 调度算法评估标准包括CPU利用率、吞吐量、周转时间、等待时间和响应时间。
- 常见算法:FCFS简单但可能导致长进程阻塞短进程;SJF最优但实现困难;RR提供时间片,防止长进程阻塞;优先级调度按优先级分配CPU。
- 多级队列和多级反馈队列将进程分组调度,允许进程在队列间迁移。
- 多核处理器需负载均衡,但线程迁移可能影响缓存性能。
- 实时调度分为软实时和硬实时,硬实时需提供时间保证。
- Linux使用CFS基于vruntime公平分配CPU时间;Windows使用32级优先级调度;Solaris使用六类调度映射全局优先级。
- 算法评估方法包括建模、模拟和实现,各有优劣。#### 第五章 习题
- 5.11 I/O密集型程序更可能进行自愿上下文切换,CPU密集型程序更可能进行非自愿上下文切换。因为I/O密集型程序经常主动等待I/O操作完成,而CPU密集型程序更可能被调度器抢占。
- 5.12 调度准则之间存在冲突:CPU利用率高可能增加响应时间;最小平均周转时间可能增加最大等待时间;提高I/O设备利用率可能降低CPU利用率。
- 5.13 BTV调度器通过为高优先级线程分配更多彩票票数,使其在每次抽奖中获胜概率更高,从而获得更多CPU时间。
- 5.14 每个核心独立运行队列可减少锁竞争,但可能导致负载不均;共享运行队列可实现负载均衡,但可能引发并发访问性能问题。
- 5.15 α=0时预测始终为初始值τ0=100ms;α=0.99时预测几乎完全依赖最近一次CPU突发时间。
- 5.16 回归轮转调度偏向I/O密集型进程,因为它们频繁让出CPU,不会导致时间片增加,而CPU密集型进程会因用满时间片而获得更长时间片和优先级提升。
- 5.17 包括绘制Gantt图、计算不同调度算法下的周转时间和等待时间,并比较平均等待时间。
- 5.18 使用优先级抢占调度,高优先级进程可中断低优先级进程,相同优先级使用轮转调度(时间片为10)。
- 5.19 nice值小于0表示更高优先级,系统通常限制只有root可设置,防止普通用户滥用高优先级影响系统稳定性。
- 5.20 可能导致饥饿的算法:优先级调度(低优先级进程可能永远得不到执行)。
- 5.21 在就绪队列中放入同一进程的两个指针可增加其执行频率,但会增加调度开销和复杂性。可通过动态调整时间片实现类似效果。
- 5.22 轮转调度下,时间片为1ms时CPU利用率约为98%,为10ms时约为91%,因为I/O密集型任务频繁切换导致更多上下文切换开销。
- 5.23 用户可通过将任务拆分为多个子任务,使其在多级队列中分布更广,从而获得更多CPU时间。
- 5.24 β>α>0时等价于最短作业优先;α<β<0时等价于最长作业优先。
- 5.25 RR和多级反馈队列偏向短进程;FCFS不利于短进程,因其需等待前面长进程完成。
- 5.26 共享就绪队列在SMP环境中可能导致缓存一致性问题和锁竞争,影响性能。
- 5.27 若一个队列全是高优先级线程,另一个全是低优先级线程,负载均衡会破坏优先级调度效果。
- 5.28 将新进程放在父进程队列可提高缓存命中率;放在不同队列可提高负载均衡。
- 5.29 NUMA感知调度应将线程重新调度到原CPU,以减少远程内存访问延迟。
- 5.30 Windows调度优先级计算示例:实时优先级类NORMAL为24;高于正常类HIGHEST为13;低于正常类ABOVE NORMAL为6。
- 5.31 最高优先级为“高于正常”优先级类+“最高”相对优先级。
- 5.32 Solaris时间片调度:优先级15为60ms,优先级40为5ms;优先级50完成后调整为45;优先级20阻塞后调整为35。
- 5.33 CFS调度下,nice值-5的A进程比nice值+5的B进程具有更低的vruntime,获得更多的CPU时间。
- 5.34 在任务周期不固定或有多个任务共享相同周期时,最早截止优先调度(EDF)优于速率单调调度(RMS)。
- 5.35 P1和P2在速率单调调度下无法满足截止时间,但在最早截止优先调度下可以。
- 5.36 在硬实时系统中,中断和调度延迟必须有上限,以确保任务在截止时间前完成。
- 5.37 异构多处理可提高能效和性能,适合移动设备中不同任务需求。#### 编程项目
- 项目涉及实现多种进程调度算法,包括先来先服务(FCFS)、最短作业优先(SJF)、优先级调度、轮转调度(RR),以及结合优先级和轮转的调度算法。
- 优先级范围为1到10,数值越高优先级越高;轮转调度的时间片为10毫秒。
- 所有任务同时到达,不需要支持抢占式调度。
- 任务格式为[任务名] [优先级] [CPU突发时间],例如:T1, 4, 20。
实现策略
- 可使用单一无序任务列表,根据调度算法选择任务。
- 可按调度标准排序列表(如优先级)。
- 可为每个唯一优先级设置单独队列。
- 列表和队列功能不同,一般列表更适合本项目。
C语言实现细节
- driver.c读取任务、插入链表并调用schedule()函数。
- schedule()函数通过pickNextTask()选择任务,并通过run()执行。
- 使用Makefile指定调度算法,如输入make fcfs构建先来先服务调度器。
- 执行方式为./fcfs schedule.txt。
Java实现细节
- Driver.java读取任务、插入ArrayList并调用schedule()方法。
- 通过Algorithm接口实现五种调度算法,定义schedule()和pickNextTask()方法。
- Task类通过CPU.java的run()方法执行。
- 执行方式为java Driver fcfs schedule.txt。
进阶挑战
- 使用原子整数(AtomicInteger)解决SMP环境中任务标识符分配的竞态条件。
- 在Linux/macOS中使用sync_fetch_and_add()函数实现原子操作。
- 计算每种调度算法的平均周转时间、等待时间和响应时间。
第五章 进程同步
6.1 背景
- 并发执行可能导致数据不一致问题。
- 举例说明生产者-消费者问题中的竞态条件(race condition)。
- count变量在并发操作中可能产生错误值。
- 指令交错执行是竞态条件的根本原因。
- 需要进程同步机制来防止竞态条件。
6.2 临界区问题
- 多个进程共享数据时,必须确保同一时间只有一个进程进入临界区。
- 解决方案需满足三个要求:
- 互斥:一个进程在临界区执行时,其他进程不能进入。
- 进展:没有进程在临界区时,有请求的进程应能进入。
- 有限等待:等待进入临界区的次数必须有限。
- 操作系统内核也面临竞态条件问题,例如文件列表、PID分配、内存分配等。
6.3 Peterson解决方案
- 仅适用于两个进程的软件解决方案。
- 共享变量:turn 和 flag[2]。
- 满足互斥、进展、有限等待。
- 现代架构中因指令重排可能失效。
6.4 硬件同步支持
6.4.1 内存屏障
- 防止指令重排,确保内存操作顺序。
- 用于解决Peterson算法中的指令交错问题。
6.4.2 硬件指令
- Test-and-Set:原子操作,用于实现互斥。
- Compare-and-Swap (CAS):比较并交换,用于实现互斥和有限等待。
- 使用这些指令可构建更高级的同步机制。
6.4.3 原子变量
- 提供原子操作,如加减。
- 适用于单一变量更新,但无法解决复杂临界区问题。
6.5 互斥锁(Mutex Locks)
- 最简单的同步工具。
- 进程在进入临界区前获取锁,退出后释放锁。
- acquire() 和 release() 必须原子执行。
- 实现方式可基于CAS指令。
- 自旋锁(Spinlock):忙等待,适合短时间持有锁。
- 高争用下性能下降,适合多核系统。
6.6 信号量(Semaphores)
6.6.1 信号量使用
- 计数信号量:控制多个资源实例的访问。
- 二值信号量:行为类似于互斥锁。
- 可用于进程同步,例如确保某段代码在另一段执行后才执行。
6.6.2 信号量实现
- wait() 和 signal() 操作必须原子执行。
- 改进实现:使用等待队列避免忙等待。
- 每个信号量包含一个值和一个等待进程队列。
- wait():值减一,若小于0则进程进入等待队列。
- signal():值加一,若仍小于等于0则唤醒一个等待进程。
6.7 管程(Monitors)
6.7.1 管程使用
- 高级同步抽象,封装共享数据和操作。
- 确保同一时间只有一个进程在管程内执行。
- 条件变量(condition variables)用于等待特定条件。
6.7.2 使用信号量实现管程
- 使用互斥锁(mutex)保证互斥。
- 使用next信号量控制信号发送后的进程切换。
- 条件变量通过信号量和计数器实现。
6.7.3 管程内的进程恢复顺序
- FCFS调度或优先级调度。
- 条件等待(conditional-wait)机制允许优先级排序。
6.8 活跃性(Liveness)
6.8.1 死锁(Deadlock)
- 多个进程相互等待资源释放,导致无法继续执行。
- 示例:两个进程交叉等待两个信号量。
6.8.2 优先级反转(Priority Inversion)
- 低优先级进程持有资源,高优先级进程等待。
- 解决方案:优先级继承协议(priority inheritance protocol)。
6.9 同步工具评估
- 不同争用场景下选择合适的同步机制:
- 无争用:CAS更快。
- 中等争用:CAS更优。
- 高争用:传统锁更优。
- 原子变量适用于单一变量更新。
- 自旋锁适合短时间持有。
- 信号量适合资源控制。
- 管程和条件变量提供更高抽象,但可能性能较差。
- 研究方向:编译器优化、并发语言支持、库性能改进。#### 6.10 总结
- 竞态条件是指多个进程并发访问共享数据时,最终结果依赖于并发访问顺序的情况,可能导致共享数据的值被破坏。
- 临界区是一段可能操作共享数据、可能发生竞态条件的代码区域。临界区问题的目标是设计一种进程间协同的协议,以实现数据共享。
- 临界区问题的解决方案必须满足三个要求:(1) 互斥;(2) 进展;(3) 有界等待。
- 软件解决方案(如Peterson算法)在现代计算机架构上效果不佳。
- 硬件支持包括内存屏障、比较并交换指令(CAS)和原子变量。
- 互斥锁通过在进入临界区前获取锁、退出时释放锁来实现互斥。
- 信号量类似于互斥锁,但使用整数值,可解决多种同步问题。
- 管程是一种高级进程同步机制,使用条件变量让进程等待特定条件变为真,并在条件满足时互相通知。
- 临界区问题的解决方案可能遇到活跃性问题,如死锁。
- 不同同步工具在不同竞争负载下表现不同,应根据具体情况选择合适的工具。
练习题
- 6.1:频繁禁用中断会影响系统时钟,可通过减少中断禁用时间或使用硬件辅助来减轻影响。
- 6.2:忙等待是指进程在等待资源时持续检查资源状态,其他等待方式包括阻塞等待。在某些情况下无法完全避免忙等待。
- 6.3:自旋锁不适合单处理器系统,因为会浪费CPU时间;但在多处理器系统中可用于短时间锁定。
- 6.4:若wait()和signal()操作非原子执行,可能导致多个进程同时进入临界区,破坏互斥。
- 6.5:使用二值信号量实现n个进程之间的互斥。
- 6.6:夫妻同时对银行账户进行存款和取款操作时可能发生竞态条件,可通过互斥机制防止。
进一步阅读
- 临界区问题最早由Dijkstra提出,信号量概念也由其提出;管程由Brinch-Hansen提出,Hoare对其进行了完整描述。
- 可参考Mars Pathfinder问题、内存屏障、缓存机制、多处理器编程相关内容的文献。
习题
- 6.7:数组栈操作在并发环境下存在栈顶指针和数组元素的竞态条件,可通过互斥锁或原子操作解决。
- 6.8:在线拍卖系统中,竞拍操作存在竞态条件,可通过信号量或互斥锁解决。
- 6.9:数组求和算法中没有竞态条件,因为每一步操作都是无冲突的。
- 6.10:基于CAS的无锁栈实现是线程安全的,不会出现竞态条件。
- 6.11:比较并交换的“比较-比较-交换”策略在某些情况下可能失败,导致锁机制不安全。
- 6.12:getValue()函数可能导致竞态条件,因为调用该函数和后续wait()之间可能有其他进程修改信号量。
- 6.13-6.14:Dekker算法和Eisenberg-McGuire算法都满足互斥、进展和有界等待的要求。
- 6.15:用户程序中禁用中断不可行,因为这会影响系统调度和中断处理。
- 6.16:使用CAS实现互斥锁的acquire和release函数。
- 6.17:多处理器系统中禁用中断不能实现同步,因为中断可能在其他处理器上发生。
- 6.18:为避免忙等待,应将等待进程放入等待队列,等待锁释放时被唤醒。
- 6.19-6.20:短时间持有锁适合使用自旋锁,长时间或可能睡眠时适合使用互斥锁;持有锁时间超过T时应使用互斥锁。
- 6.21:使用原子整数比使用互斥锁更高效,因为避免了上下文切换开销。
- 6.22:进程计数变量存在竞态条件,应使用互斥锁保护;可用原子整数替代。
- 6.23:使用信号量控制服务器并发连接数。
- 6.24:重复调用wait(mutex)导致死锁,属于活跃性失败。
- 6.25:管程和信号量在功能上等价,均可用于解决同步问题。
- 6.26:管程的signal操作仅唤醒一个等待进程,而信号量的signal操作增加计数。
- 6.27:若signal只能作为最后一个语句,可简化管程实现。
- 6.28-6.32:涉及使用管程实现资源分配、文件访问控制、闹钟机制、优先级反转问题等,需根据具体要求设计条件变量和同步逻辑。#### 编程问题
- 问题6.33描述了一个管理有限资源数量的程序段,其中存在竞态条件。
- 程序定义了最大资源数(MAX RESOURCES)和当前可用资源数(available_resources)。
- 当进程请求资源时,调用decrease_count()函数,若资源不足则返回-1。
- 当进程释放资源时,调用increase_count()函数,增加可用资源数。
- 问题指出该程序段存在竞态条件,并要求识别涉及竞态的数据、位置,并使用信号量或互斥锁修复。
- 问题6.34进一步要求使用监视器和条件变量重写资源管理代码,使decrease_count()函数可以阻塞进程直到资源足够。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.