
计算机网络
层次模型
一共有7层
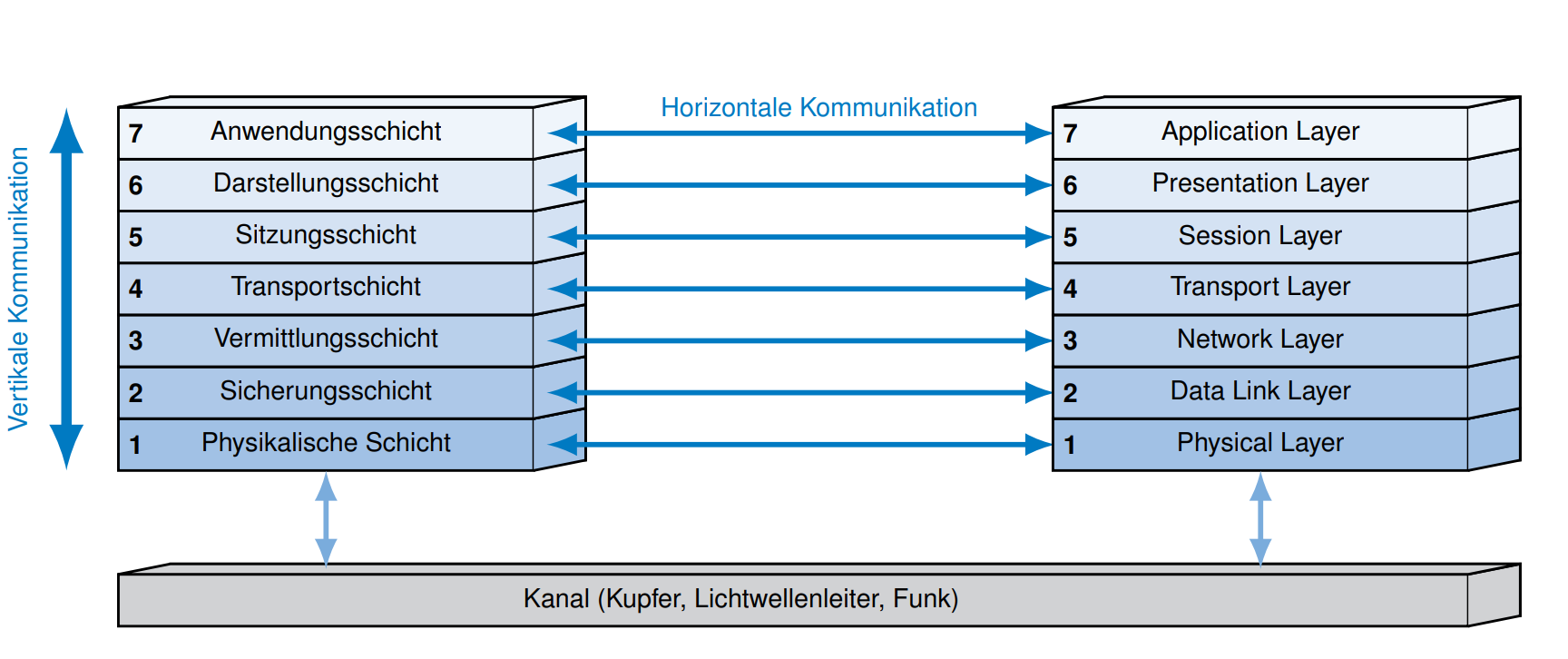
物理层
信号是随时间变换的,可物理测量的量。信号变化可以对于一个符号。这些符号就是信息。
信息含量(Informationsgehalt)是这个符号可以传递多少信息。
一个信息出现次数越少,它的信息含量越高
字符串的信息含量是所有字符信息含量的和
可预测的字符信息含量是0
信息的定义
信息存在于一个信号的变化预知的不确定性。一个字符 \(x \in X\) 的信息含量与它出现的概率 \(p(x)\) 有关。 \[ I(x)=-\log _{2} p(x) \quad \text { mit } \quad[I]= bit. \] 熵(Entropie)是一个信息源的信息含量 \[ H(X)=\sum_{x \in X } p(x) I(x)=-\sum_{x \in X } p(x) \log _{2}(p(x)) \] 其中的\(p(x)\) 也可以写成 \(Pr[X=x]\)
有条件的熵
有条件的熵(bedingte Entropie)指当X已知的时候Y的不确定性 \[ H(Y | X)=\sum_{x \in X } p(x) H(Y | X=x)=-\sum_{x \in X } p(x) \sum_{y \in Y } p(y | x) \log _{2} p(y | x) \]
组合熵
X,Y一起发生. \(p(x,y)\) 是Verbunddichte. \[ p(x, y)=\operatorname{Pr}[X=x | Y=y] \operatorname{Pr}[Y=y] \\ H(X, Y)=-\sum_{x \in X } \sum_{y \in Y } p(x, y) \log _{2} p(x, y) \] 组合熵和有条件熵的计算 \[ H(X, Y)=H(X)+H(Y | X) \\ H(Y | X)=-\sum_{x \in X } \sum_{y \in Y } p_{X Y}(X=x, Y=y) \log _{2}\left(p_{Y}(Y=y | X=x)\right) \]
传递信息
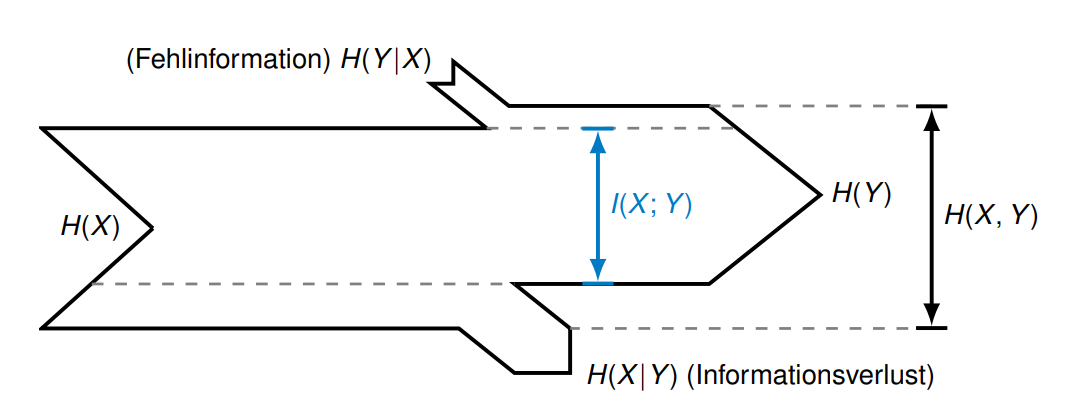
传递信息(Transinformation)是原来的信息减去失去的信息 \[ I(X ; Y)=H(X)-H(X | Y)=H(Y)-H(Y | X) \]
数据链路层 Sicherungsschicht
我们首先考虑直接连接的网络
- 所有节点可以直接到达
- 节点用简单地址表示
- 没有数据传递Vermittlung
- 可以简单继续传接(Bridging, Switching)
数据链路层的主要任务是
- 控制媒介寻址
- 检查携带的信息是否有错误
- 在直接连接的网络中寻址
网络的图表示
有向图
一个非对称asymmetrisch 的网络可以用图有向图\(\mathcal{G}=(\mathcal{N}, \mathcal{A})\) 表示
其中 \(\mathcal{N}\) 是点的集合, \(\mathcal{A}=\{(i,j)|i,j \in \mathcal{N} \}\) 是有向边的集合
无向图
一个对称的symmetrisch网络可以用无向图 \(\mathcal{G}=(\mathcal{N}, \mathcal{E})\) 表示
其中 \(\mathcal{N}\) 是点的集合, \(\mathcal{E}=\{\{i,j\}|i,j \in \mathcal{N} \}\) 是无向边的集合
路径Pfad
一个路径从 \(s\) 到 \(t\) 可以用集合表示: \[ \mathcal{P}_{s t}=\{(s, i),(i, j), \ldots,(k, l),(l, t)\} \] 路径的花费Pfadkosten是所有边花费的总和 \[ c\left(\mathcal{P}_{s t}\right)=\sum_{(i, j) \in \mathcal{P}_{s t}} c_{i j} \] 路径长度 Pfadlänge是所有边的数量,也叫 Hop Count \[ l\left(\mathcal{P}_{s t}\right)=\left|\mathcal{P}_{s t}\right| . \]
网络拓扑结构
Topologie 描述图的结构
- 物理结构
- 逻辑结构
重要的拓扑结构
点对点 Punkt-zu-Punkt

链 Kette
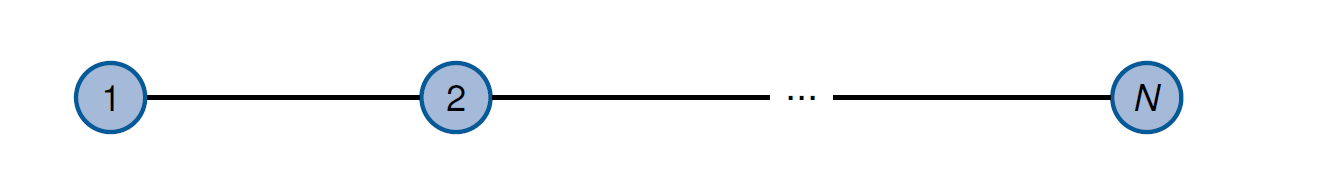
星星Stern
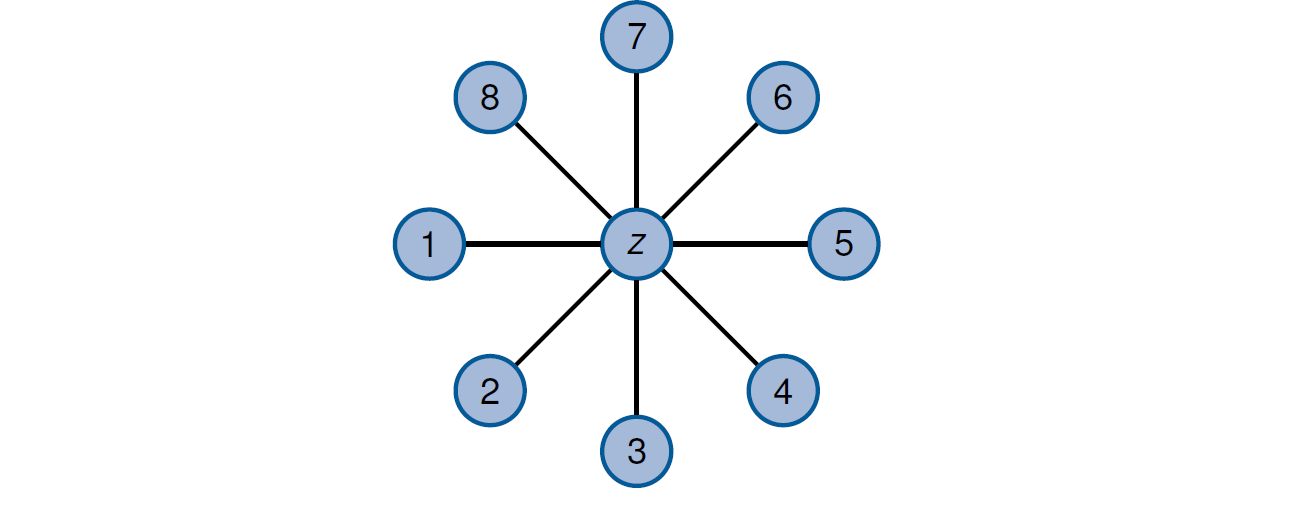
Vermaschung
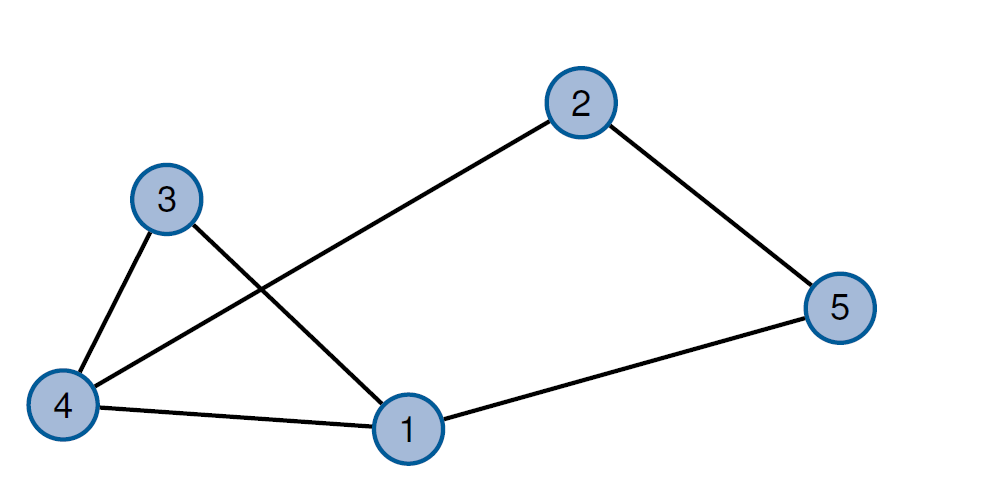
树 Baum

总线 Bus
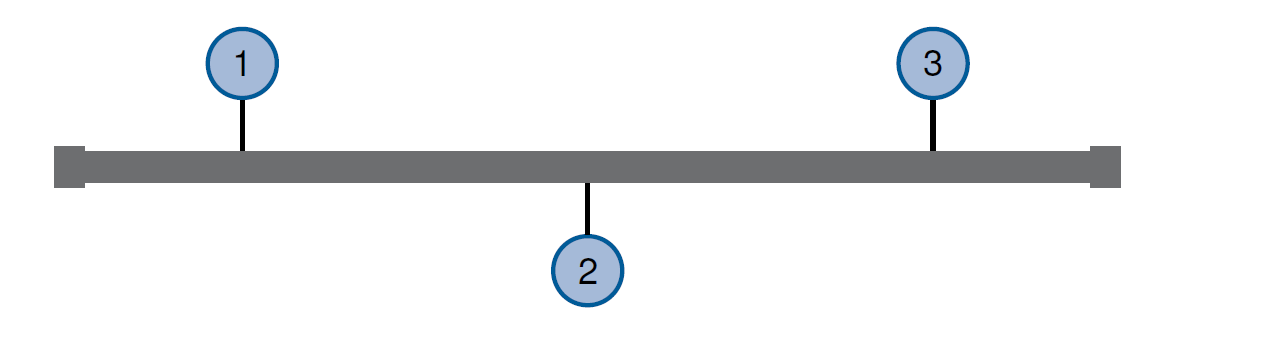
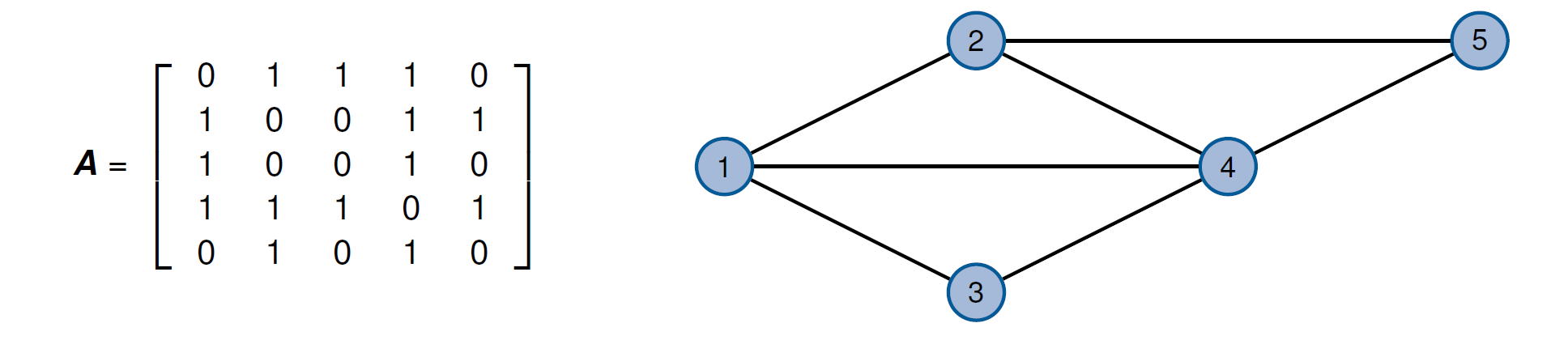
邻接矩阵和距离矩阵
邻接矩阵Adjazenzmatirx: \[
\boldsymbol{A}=(a)_{i j}=\left\{\begin{array}{ll}
1 & \exists(i, j) \in \mathcal{A} \\
0 & \text { sonst }
\end{array}, \forall i, j \in \mathcal{N}, \quad \boldsymbol{A}
\in\{0,1\}^{N \times N}\right.
\] 
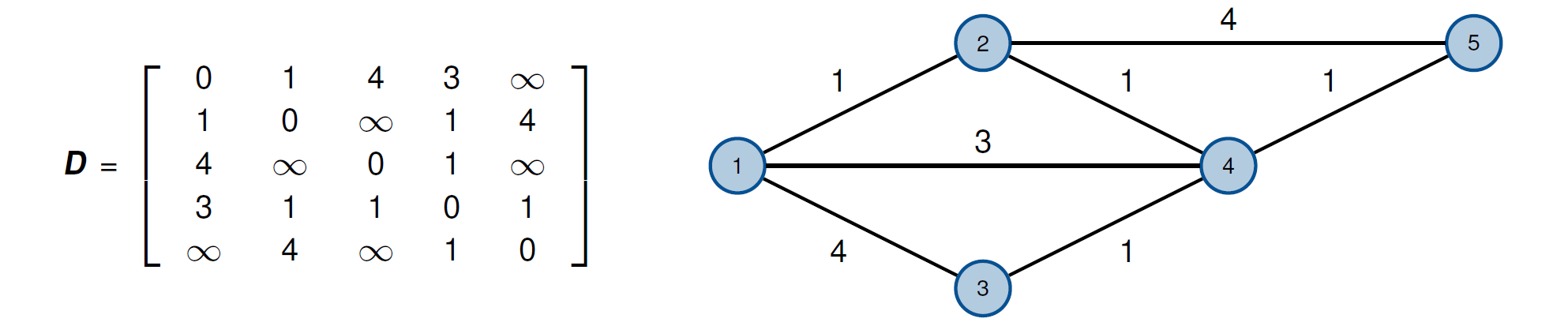
距离矩阵Distanzmatrix: \[
\boldsymbol{D}=(d)_{i j}=\left\{\begin{array}{ll}
c_{i j} & \exists(i, j) \in \mathcal{A} \\
0 & \text { wenn } i=j, \quad \forall i, j \in \mathcal{N}, \quad
\boldsymbol{D} \in \mathbb{R}_{0+}^{N \times N} \\
\infty & \text { sonst }
\end{array}\right.
\] 
生成树结构
- 最短路径树(Shortest Path Tree)
- 最小生成树(Minimum Spanning Tree)
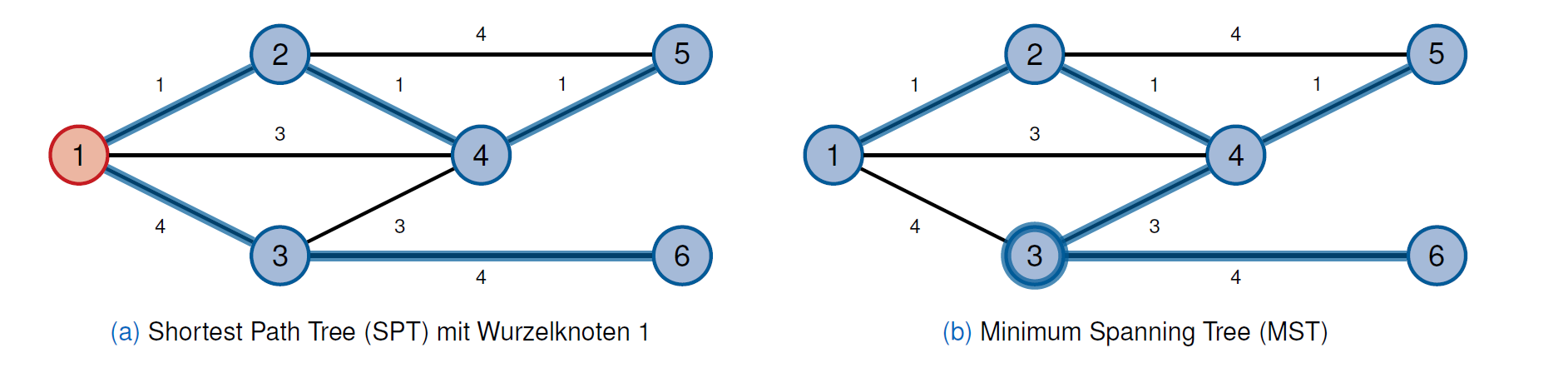
连接特征
- 传递率 Übertragungsrate
- 传递延迟Übertragungsverzögerung
- 传递方向Übertragungsrichtung
- 多次访问Mehrfachzugriff
我们首先讨论点对点的连接
传递率
传递率 \(r\) (bit/s) 决定传递 \(L\) 的数据块所需要的时间,这个时间称为序列化时间 Serialisierungszeit \[ t_{s}=\frac{L}{r} \]
Ausbreitungsgeschwindigkeit
是一个距离 \(d\)
Ausarbeitungsverzögerung传递延迟
\[ t_{p}=\frac{d}{\nu c_{0}} . \]
其中 \(d\) 是传输距离,\(c_0\) 是光速,\(\nu\) 是介质的传输倍率(relative Ausbreitungsgeschwindigkeit in einem Medium)
传输时间Übertragungszeit
\[ t_{d}=t_{s}+t_{p}=\frac{L}{r}+\frac{d}{\nu c_{0}} \]
Bandbreitenverzögerungsprodukt
同一时间传输的bit数 \[ C=t_{p} r=\frac{d}{\nu c_{0}} r \]
Multiplex
ALOHA
假设有很多节点 \(N>15\) , 每个结点有相同且独立的发送概率,发送的信息大小相同(发送时间$ T$ )
每个节点发送到中心,如果两个节点同时发送数据就会产生冲突collision
可以用伯努利实验来建模,因为有许多节点,所以它是二项分布的。当 \(N\) 很大的时候,可以用泊松分布近似
\(Np=\lambda\) 是泊松分布的参数
事件 \(X_t\) 是在区间 \([t,t+T)\) 中发送数据的节点数量 \[ \operatorname{Pr}\left[X_{t}=k\right]=\frac{\lambda^{k} e^{-\lambda}}{k !} \] 假设一个节点在 \(t_0\) 的时候发送了数据
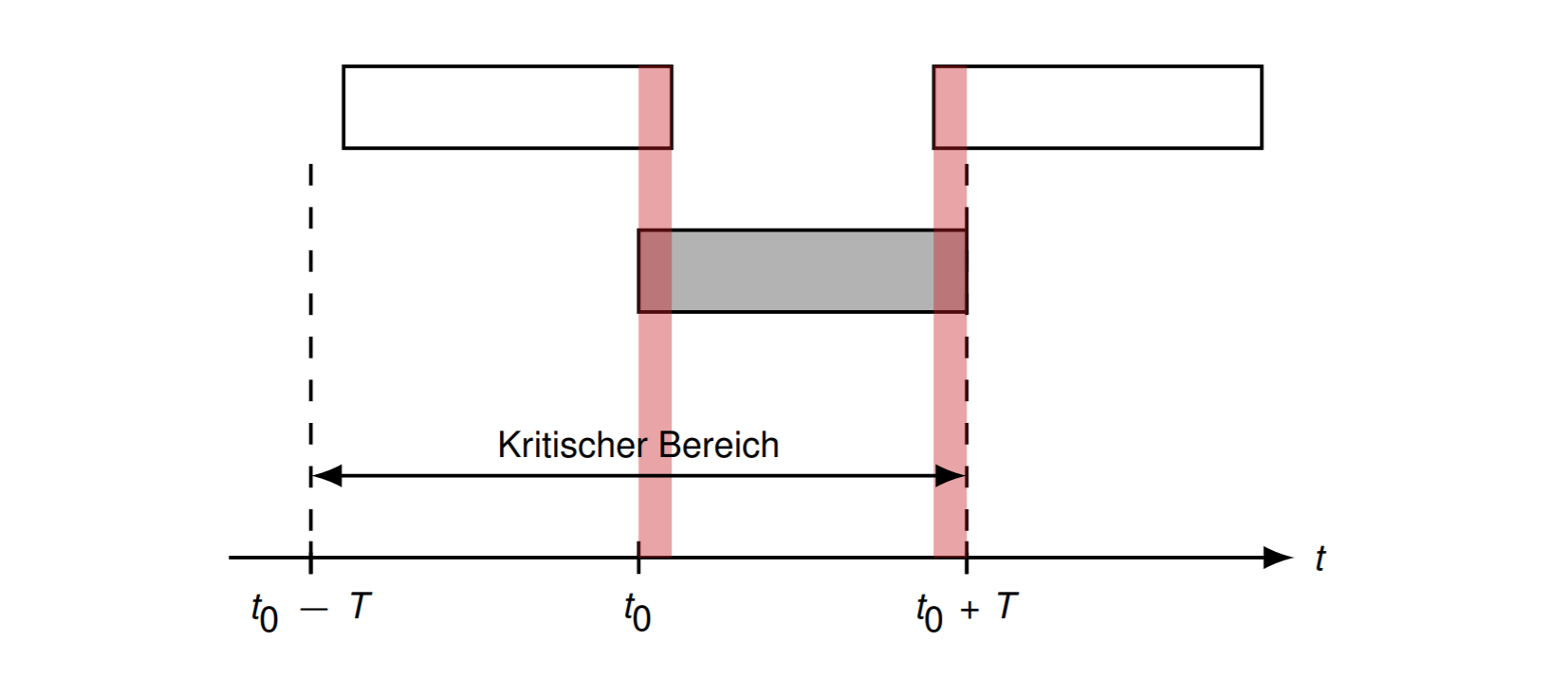
那么在 \([t_0-T,t_0+T]\) 的时间里都不能有其他节点发送数据 \[ p_{0}=\operatorname{Pr}\left[X_{t_{0}-T}=0\right] \operatorname{Pr}\left[X_{t_{0}}=1\right]=\mathrm{e}^{-\lambda} \lambda \mathrm{e}^{-\lambda}=\lambda \mathrm{e}^{-2 \lambda} \] 那么 \(p_0\) 就是不发生冲突的概率
Slotted ALOHA
节点不会在任意一个时间点发送,而是在离散的点发送 \(t = nT, n=0,1,2,...\) \[ S=\lambda \cdot e^{-\lambda} . \] 现在Kritischer Bereich就变小了,不发生冲突的概率就增大了为 \(S\)
Carrier Sense Multiple Access (CSMA)
CSMA 一个队 slotted aloha 的优化: „Listen Before Talk“在说之前听
它监听,只在空闲的时候发送
它还有不同的种类
\(1\)-persistentes CSMA
当没有媒体的时候,开始发送
如果有媒体,那么等到它结束了再发送
\(p\)-persistentes CSMA
当没有媒体的时候,有 \(p\) 的概率开始发送。\(1-p\) 的概率等待一会,然后重新判断
当有媒体,那么等到结束之后再重新判断
nicht-persistentes CSMA
当没有媒体的时候,开始发送
如果有媒体,随机等待一个时间段然后再判断
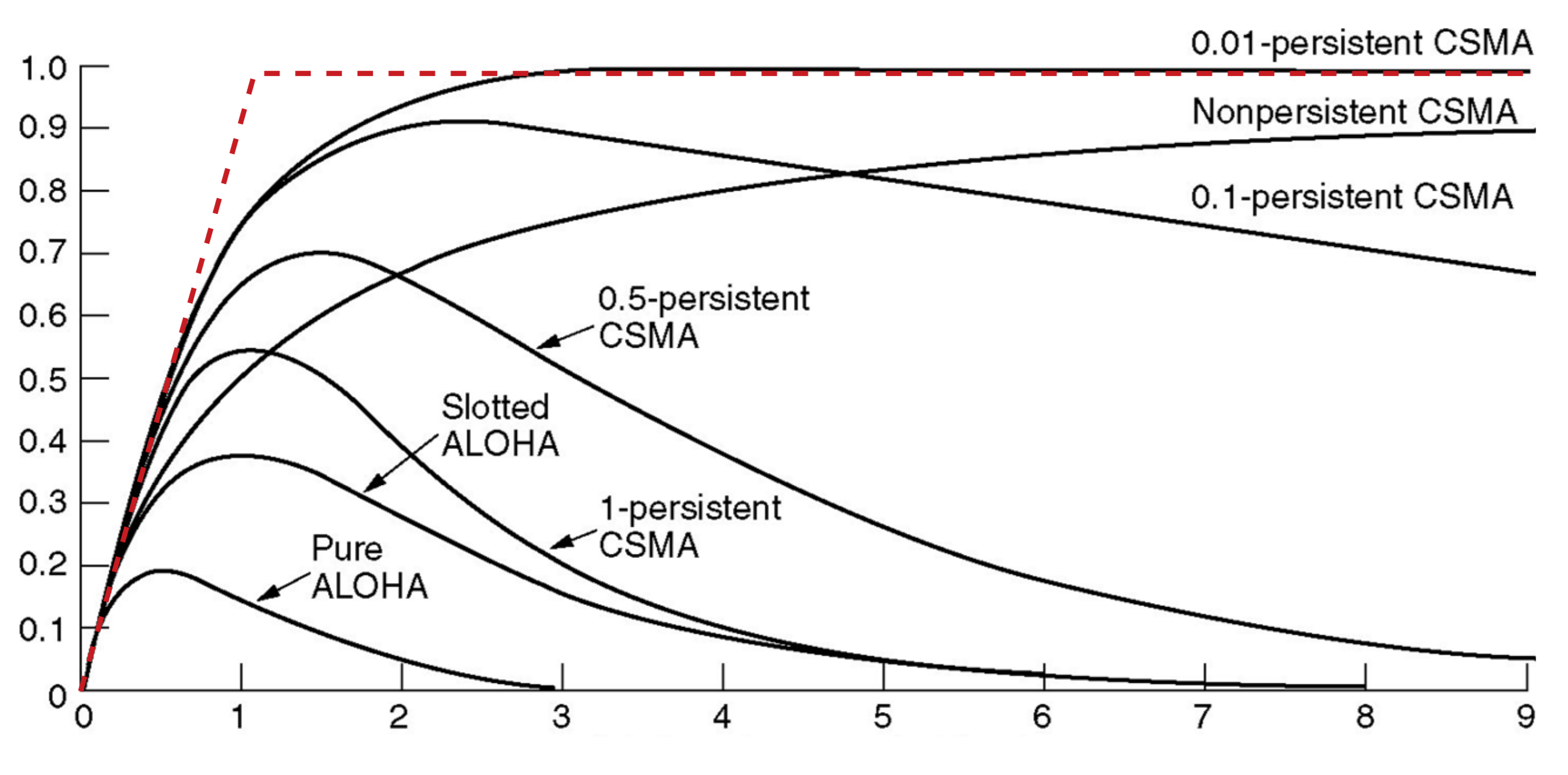
这个是目前所有时间的比较
CSMA/CD (Collision Detection)
检查到冲突的时候,重新发送
如果没有冲突那么就发送
- 发送端要能在发送的同时检测冲突
要检测冲突,那么对发送数据的长度也有要求
发送数据的最短长度是 \(L_{min}\)
\[
L_{\min }=\frac{2 d}{\nu c_ {0}} r
\] 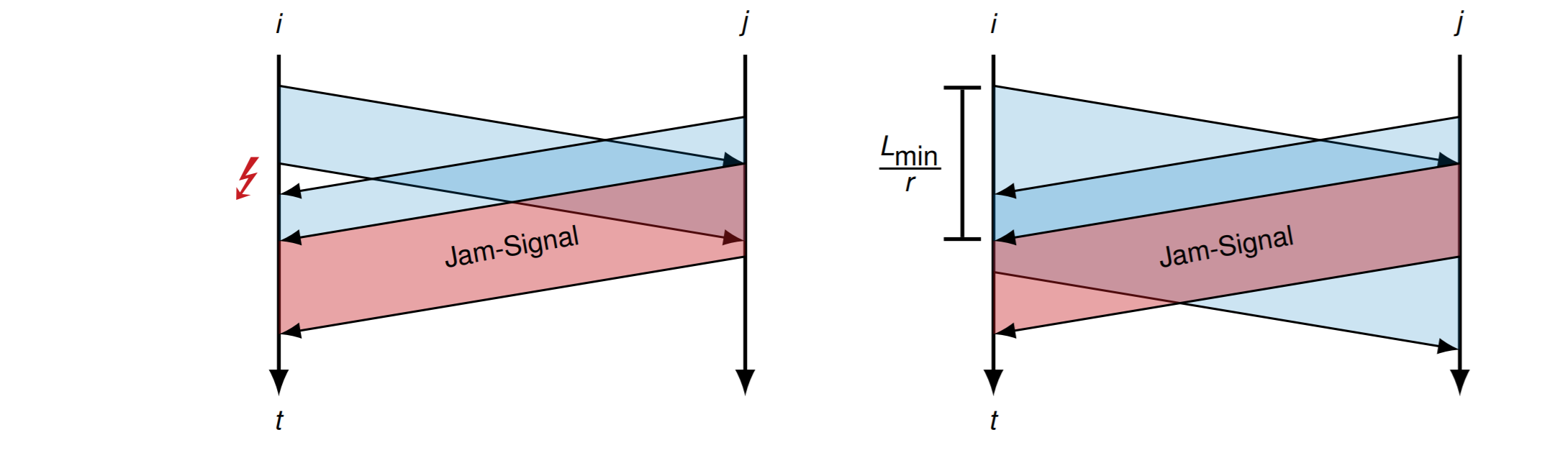
否则 \(i\) 识别不出冲突
如果用 \(1\)-persistentes CSMA 会有问题
- 冲突会影响两个发送站
- 至少1个发送站要发送 Jam-Signal
- 等待过后又会有冲突
解决方案:
在第 \(k\) 次等待的时候,等待如下的时间 \[ n \in\left\{0, \ldots, \min \left\{2^{k-1}-1,1023\right\}\right\} \]
这样就会减小重复发送的时间
CSMA/CA (Collision Avoidance)
如果是一个WIFI的无限网络,那么就很难检测冲突。因为 \(i\) 对于 \(j\) 是隐藏的站点 „Hidden Station“
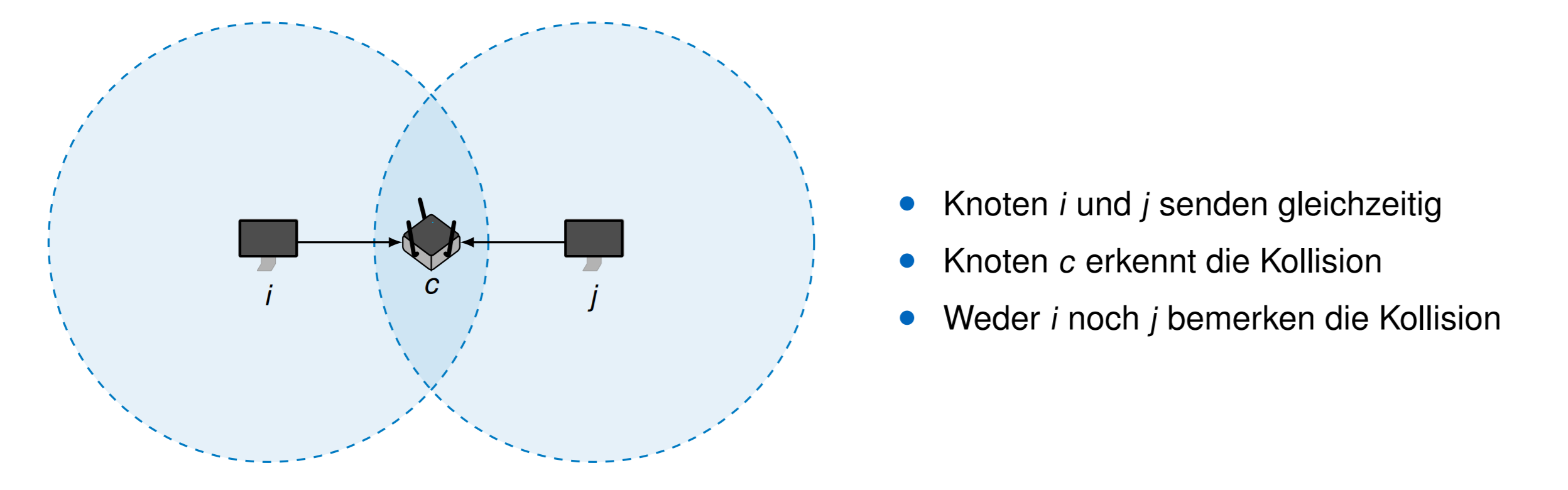
这个时候用 \(p\)-persistentes CSMA
RTS/CTS是这个方法的一个拓展
有一个控制中心,站点发送数据前先向数据中心发送请求 RTS(Request to send). 数据中心再发送 CTS(Clear to send) 回复。站点被允许发送的时候就可以发送,否则就继续等待一个CTS里要求的时间
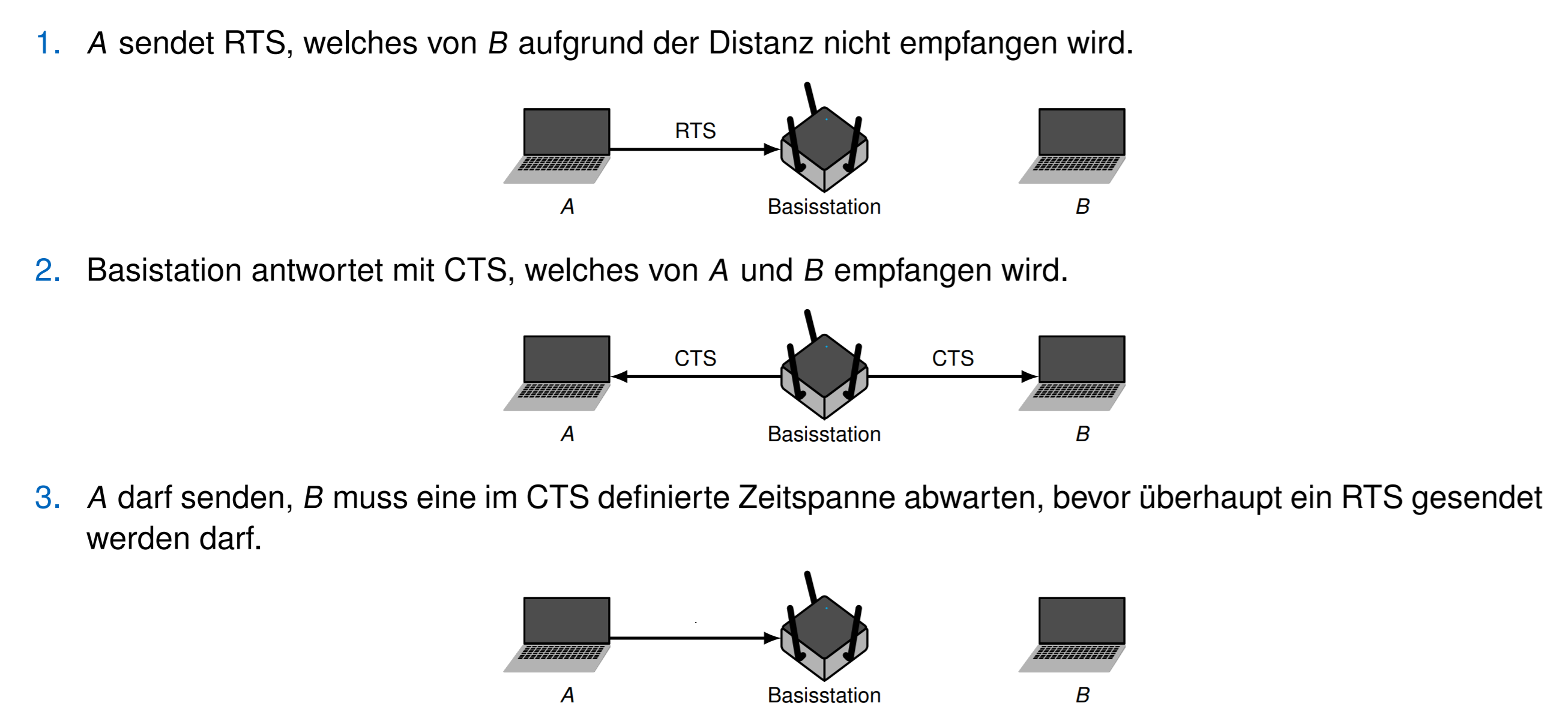
优点:Longest Prefix Matching
- 避免隐藏站点来减少冲突,但是不能完全避免
- 减少冲突
缺点:
- 如果 B 不接受 CTS的话就会发生冲突
- RTS/CTS 减少最大可以达到的传递率Datenrate
Token Passing
所有站点连成一个环,然后传递一个Token,只有当拿到Token的时候才可以发送,发送完之后,要将Token传递给下一个站点
会有一个站点Monitor-Station来监督,如果 Token丢失了,那么会重新生成一个
优点:
- 高效,没有冲突
- 保证最大延迟
缺点:
- 需要监督站点
- 一个站点出错会影响其他站点
- 发送延迟会更高,因为要等待Token
- 把站点连成环的代价高
源数据,寻址,识别错误
识别数据
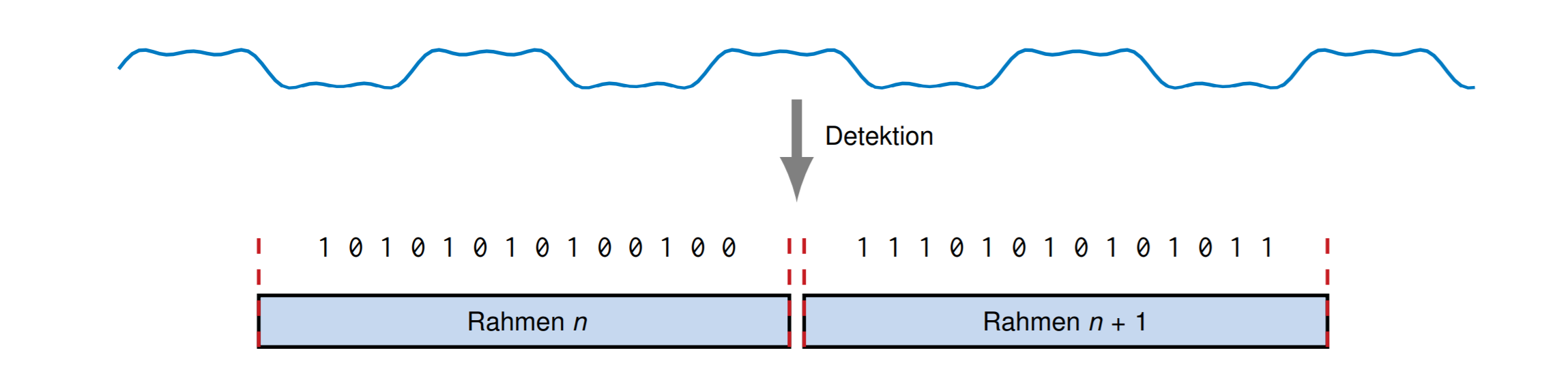
如何在一串数据流中识别两个不同的数据。
Längenangabe der Nutzdaten
在数据的开始标明长度

但是怎么知道一个数据从哪里开始:
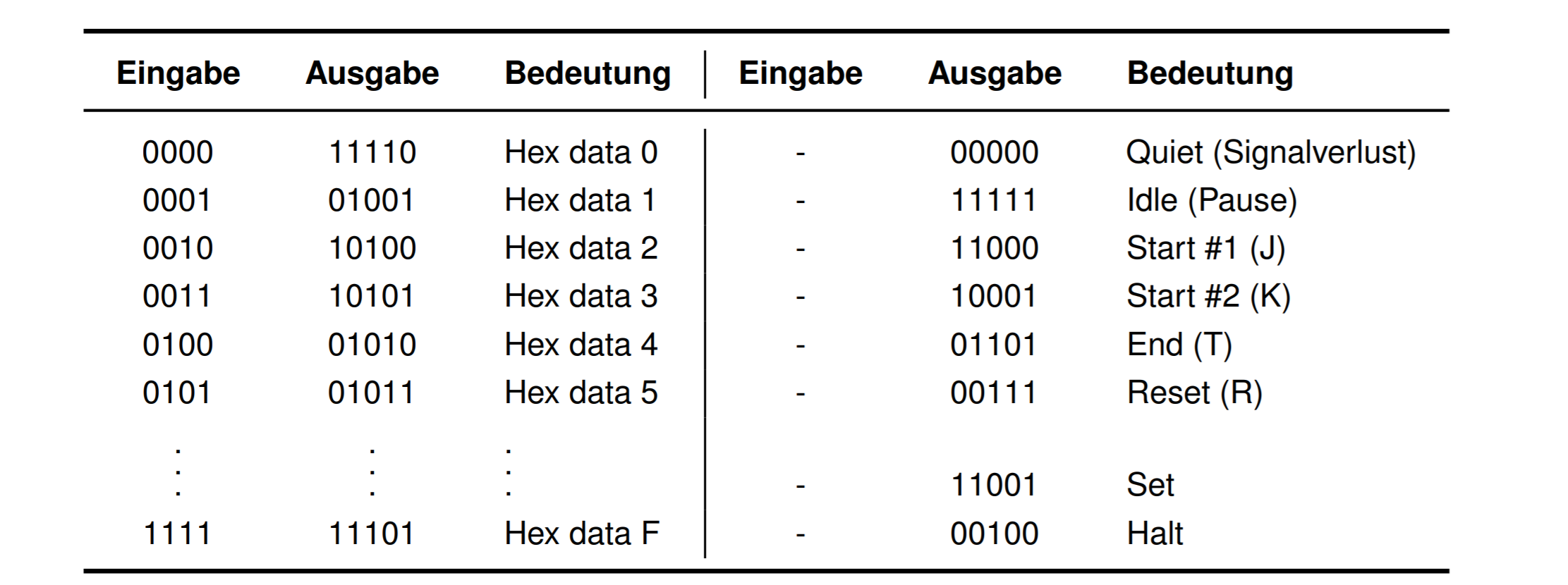
通过控制字符Steuerzeichen
每个 4bit 的数据会被唯一的映射到 5bit的数据里
通过 J/K 控制开始,T/R 控制结束
通过分隔符Begrenzungsfelder und Bit-Stopfen
用一定的bit序列来标注开始和结束,然后再源数据中不会出现这些符号
比如开始结束用 01111110
然后数据是 1100101111110111111 ,在每5个1后加入一个0
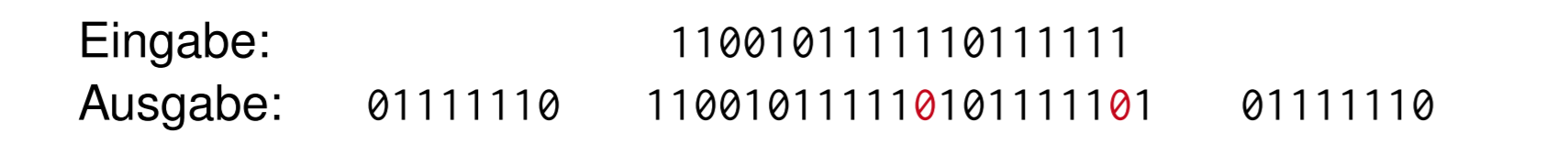
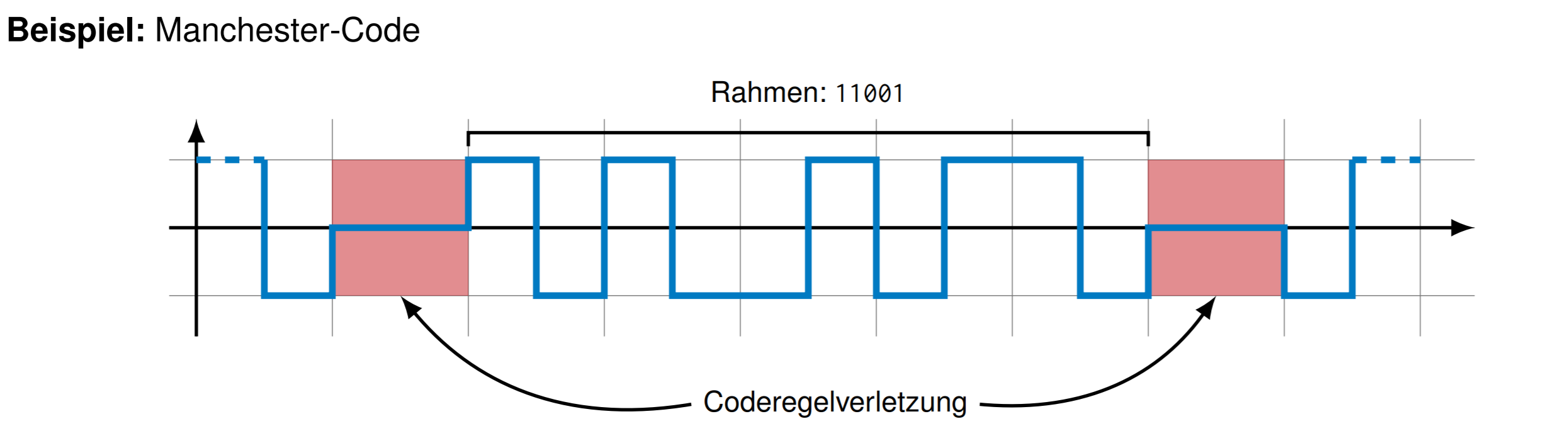
Coderegelverletzung
通过特定的信号控制来识别
寻址Adressierung
在直接连接的网络中,节点之间是直接连接的,不需要路由Vermittlung (engl. Routing)。我们需要唯一确定在网络中的每一个节点。
在Schicht2中的的地址是 MAC地址(Media Access Control)

在IEEE 802-Standards标准下的MAC地址是有如下的结构
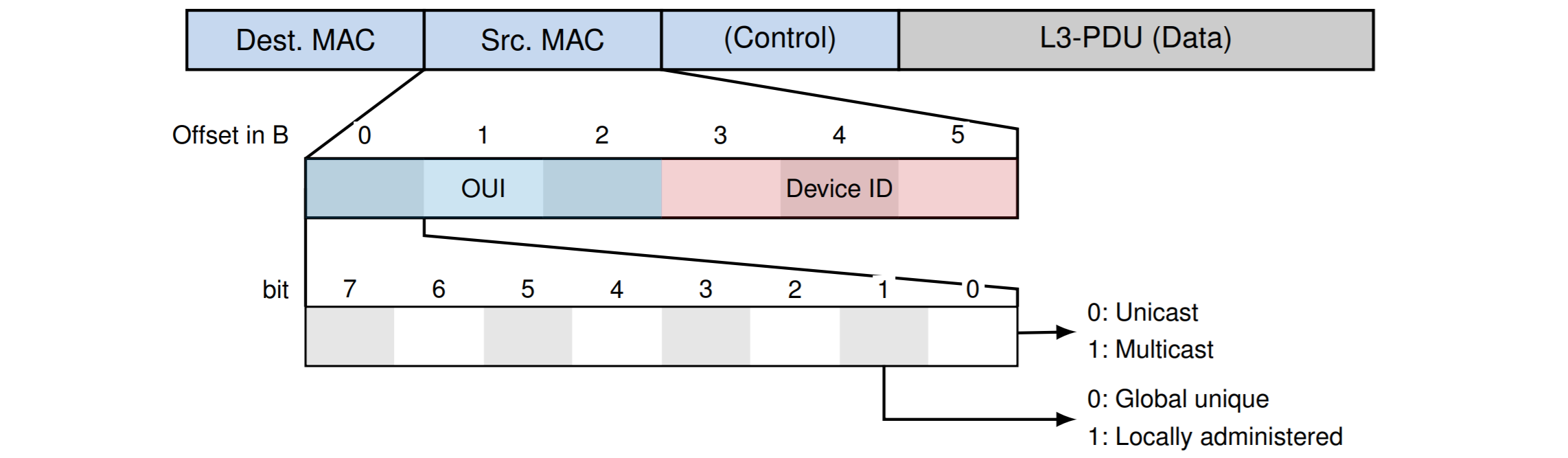
网卡在工作后会在 RAM里留下MAC地址
在制造网卡的时候MAC地址是唯一的,
制造商可以通过MAC地址确定他们的设备,比如苹果的是
7c:6d:62
如果是广播的话,MAC地址都是1:ff:ff:ff:ff:ff:ff
识别错误
在传播数据的时候,会产生错误。为了减少错误就需要可以识别错误的编码fehlererkennende Codes
Cyclic Redundancy Check (CRC) 是一个识别错误的编码族群
长度为 \(n\)
的数据串可以表示成一个多项式 \[
a(x)=\sum_{i=0}^{n-1} a_{i} x^{i} \text { mit } a_{i} \in \mathbb{F}_{2}
\text { mit } \mathbb{F}_{2}=\{0,1\}
\] 设 \(F_q[x]\)
是表示所有长度为 \(n\)
的数据的集合,\(q=2^n\) \[
F_{q}[x]=\left\{a \mid a(x)=\sum_{i=0}^{n-1} a_{i} x^{i}, a_{i} \in
\mathbb{F}_{2}\right\}
\] 我们可以定义加法和乘法 \[
c(x)=a(x)+b(x)=\sum_{i=0}^{n-1}\left(a_{i}+b_{i}\right) x^{i}
\] 这里相加是 XOR 运算 \[
d(x)=(a(x) \cdot b(x)) \bmod r(x)
\] 计算乘法的时候,我们选取一个Reduktionspolynom \(r(x)\), 这里 \(r(x)\) 必须满足 irreduzibel 且 如果 \(a(x),b(x)\) 的最高位是 \(n-1\), 那么 \(r(x)\) 的最高位是\(n\)
也就是 \(r(x)\) 不能表示为两个 \(n-1\) 集合中多项式相乘的结果

对于CRC策略,它选取 \(r(x)=p(x)(x+1)\)
若信息是 \(m(x)\)
- 首先在结尾加上 \(n\) 个 \(0\), 即\(m^{\prime}(x)=m(x) \cdot x^{n}\)
- 然后求余数 \(c(x)=m'(x) \bmod r(x)\)
- 最后发送 \(s(x) = m'(x) +c(x)\)
对于接受方而言,收到的信息是 \(s^{\prime}(x)=s(x)+e(x)\)
如果满足 \[ c^{\prime}(x)=s^{\prime}(x) \bmod r(x)=(s(x)+e(x)) \bmod r(x) \] 若 \(c'(x)=0\) 那么大概率是没有错误的
否则就有错误
CRC能纠错的类型
- 所有 1 bit-Fehler
- 隔离的 2bit-Fehler ,就是两个 \(i,j\) 距离 \(i-j>n\)
- 一些长度大于 \(n\) 的 Burst-Fehler
1层和2层的连接方式
Hub, Bridges und Switches
Hub:
A 发送到 D点, Hub通过总线连接所有节点。发送的信息所有节点都能收到。每次只能1个节点发送,否则会产生冲突
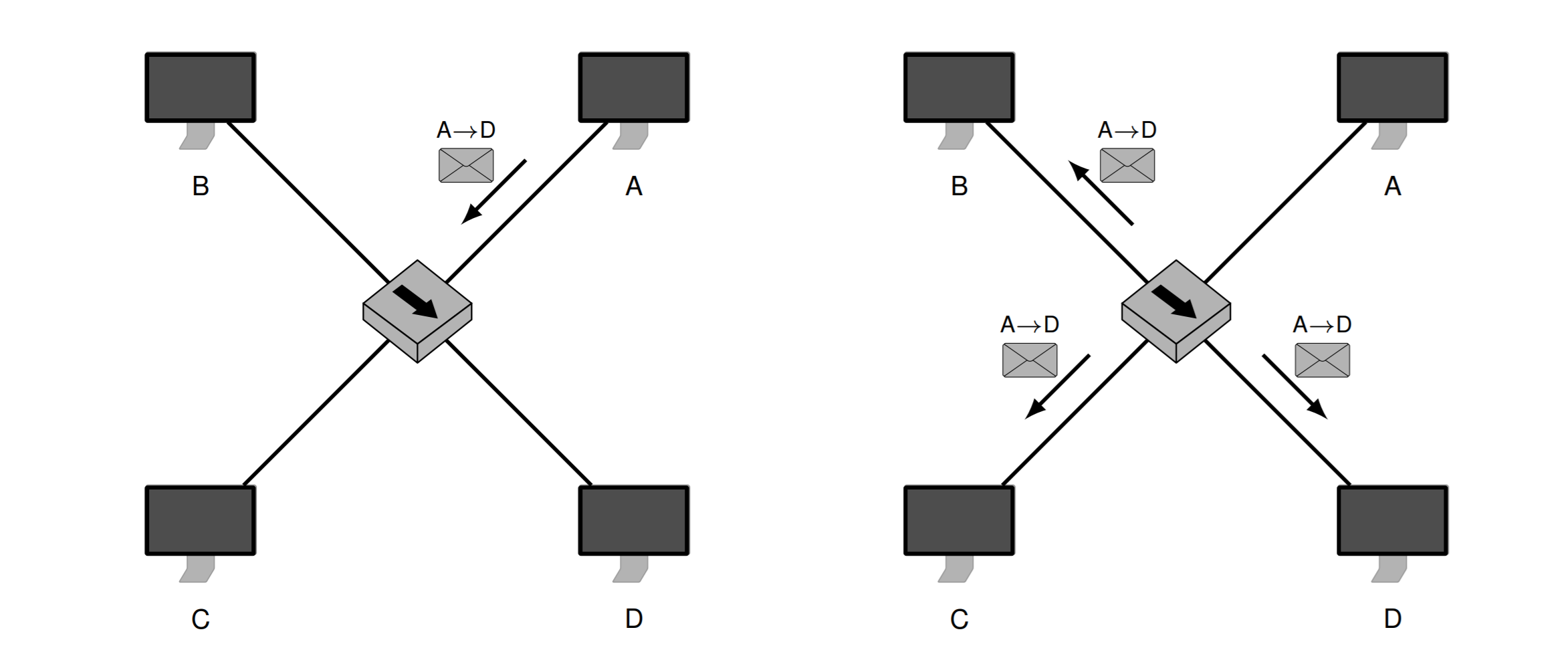
Aktive Hubs (Repeater): 增强物理信号后转发
Passive Hubs: 只是转发
Switch交换机
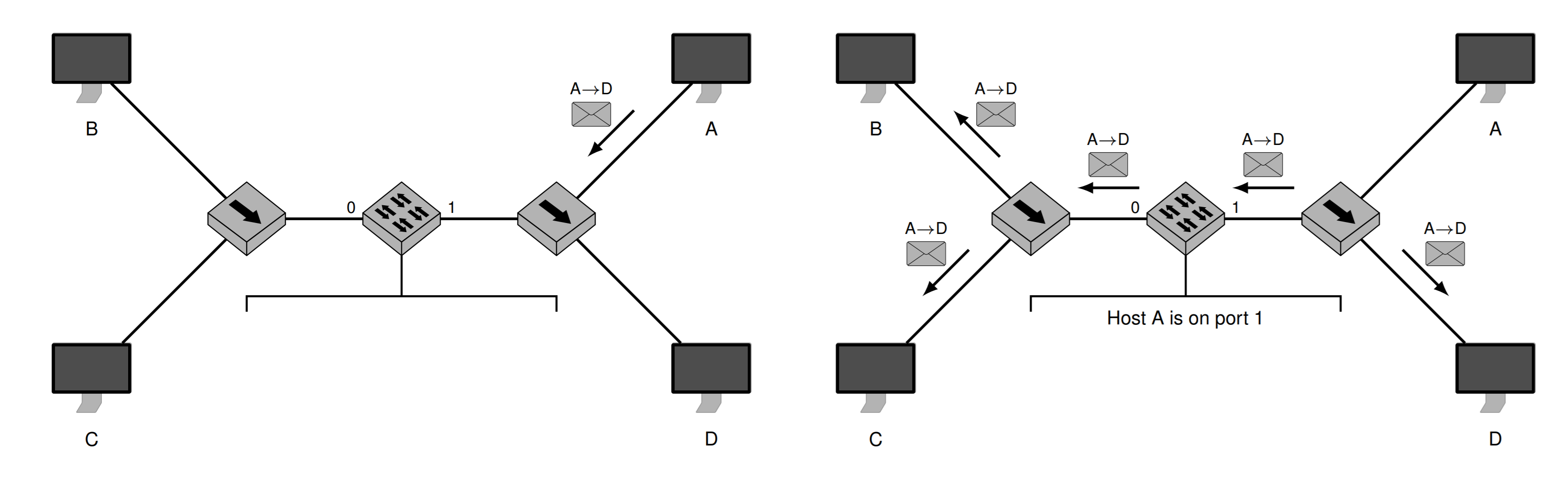
两组通过Hub连接的主机,再连上了交换机。交换机相当于有2个端口的Hub,它知道数据从哪个端口传输过来。只街上2个的交换机也叫做桥 Bridge
如果发送的信息有Eintrag登记,那么只会发送到登记的那个端口。
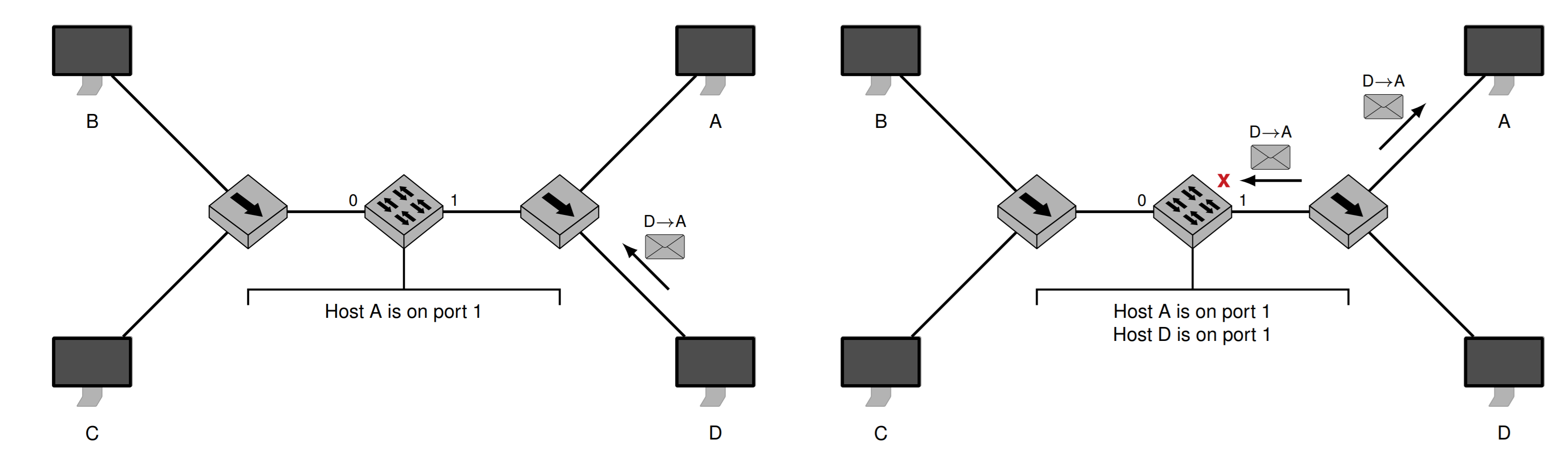
交换机可以划分冲突区域(Kollisionsdomänen,Segmentierung),不同区域的可以同时发送信息
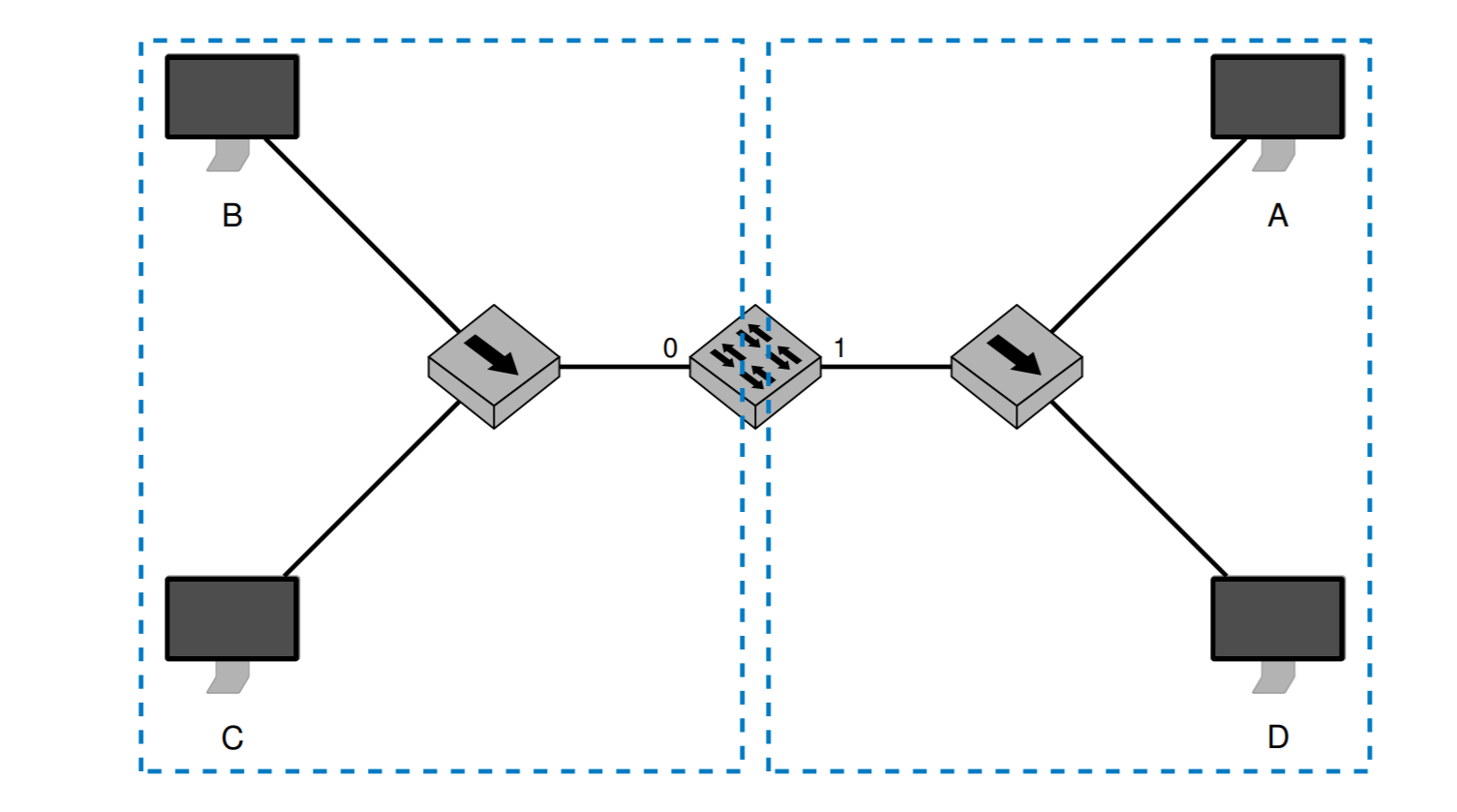
如果每个区域只有一个主机,那么称为(Microsegmentation,vollständig geswitchtem Netz)
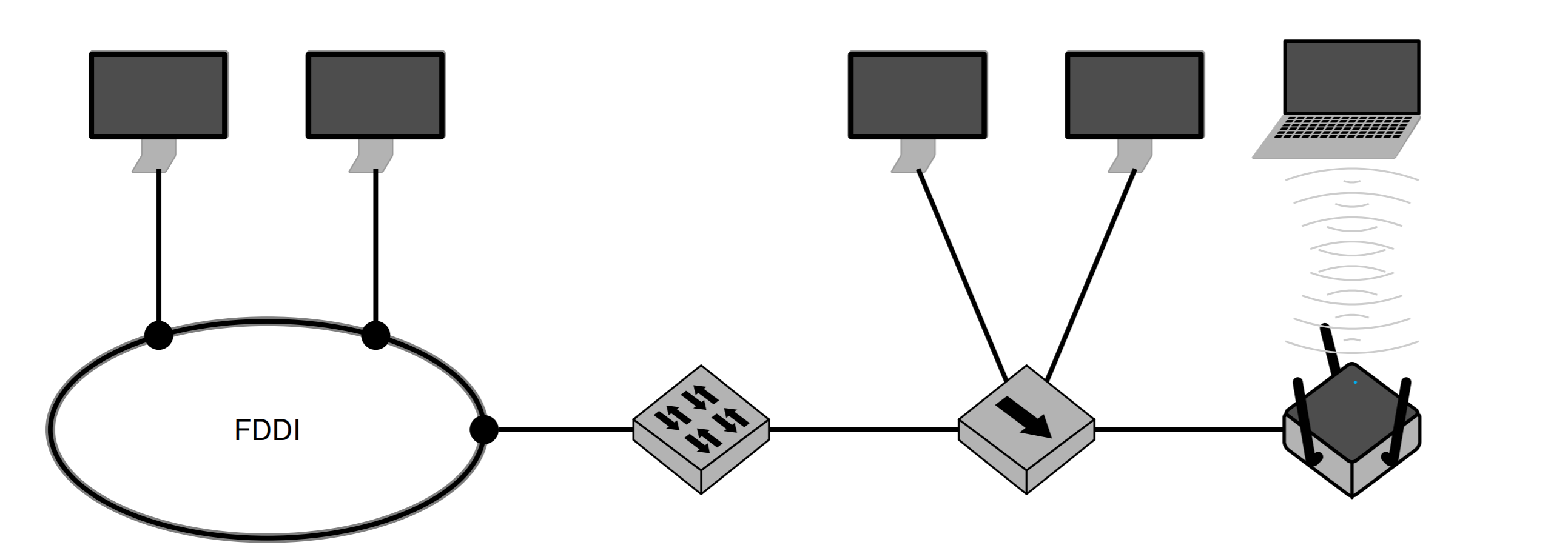
交换机可以连接不同通讯协议(Zugriffsverfahren)的网络段, 这种连接是 transparent 的。节点不知道是否使用了交换机。
WLAN Access Points
WLAN Access Point是连接有线和无限传递(Funkübertragung)的桥梁, 在有线连接是 RJ45-Interface, 在无线方向是Wireless Transceiver。
与交换机不同的是,对于WLAN的客户端来说是nicht transparent 的
如果PC1给NB2发送信息,首先确定Source Address (SA) und Destination Address (DA)
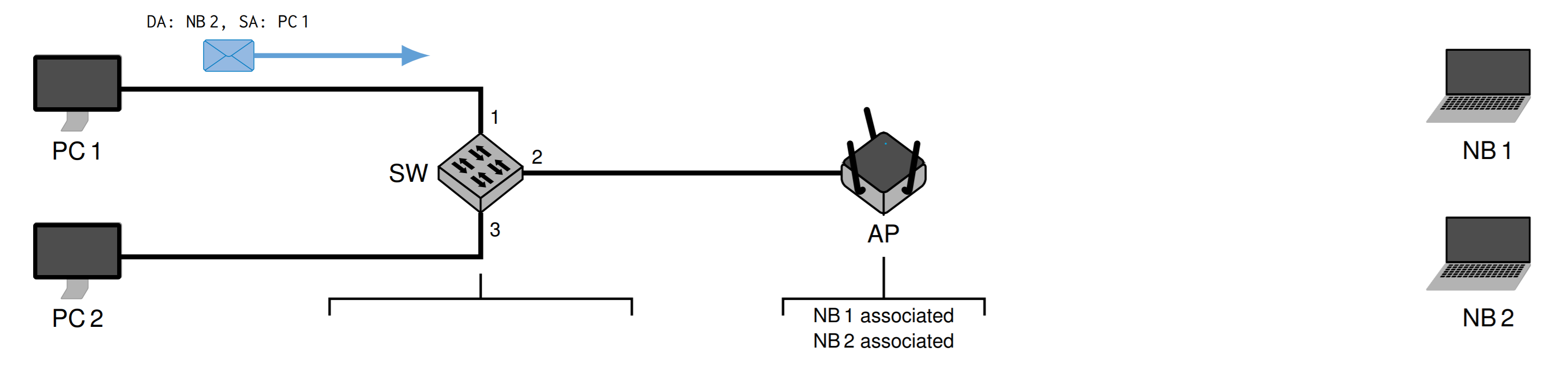
然后经过交换机,因为交换机不知道 NB2,所以会发送给除了发送者的所有人
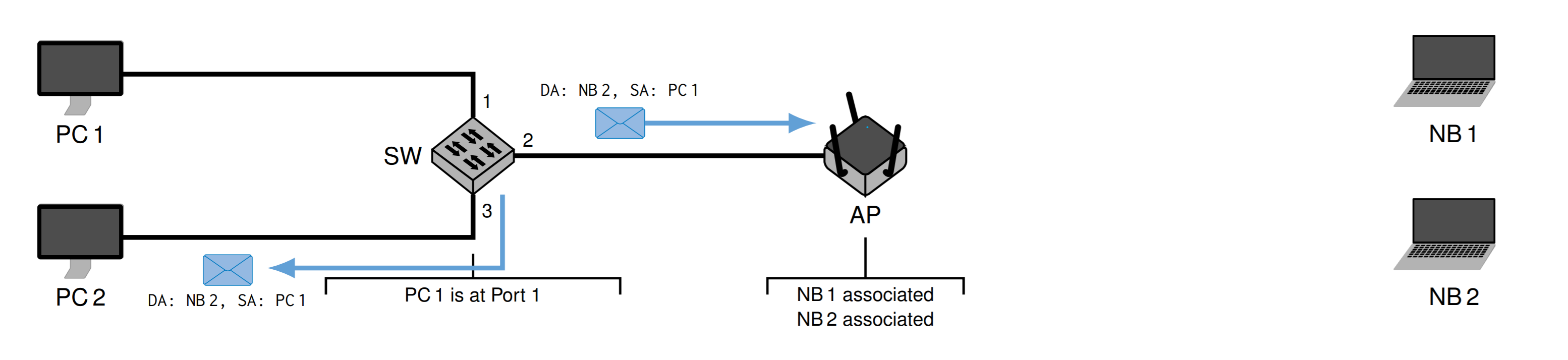
然后AP知道NB2的地址,发送给NB2,Transmitter Address (TA)就是AP的地址,然后NB1会忽略这个信息
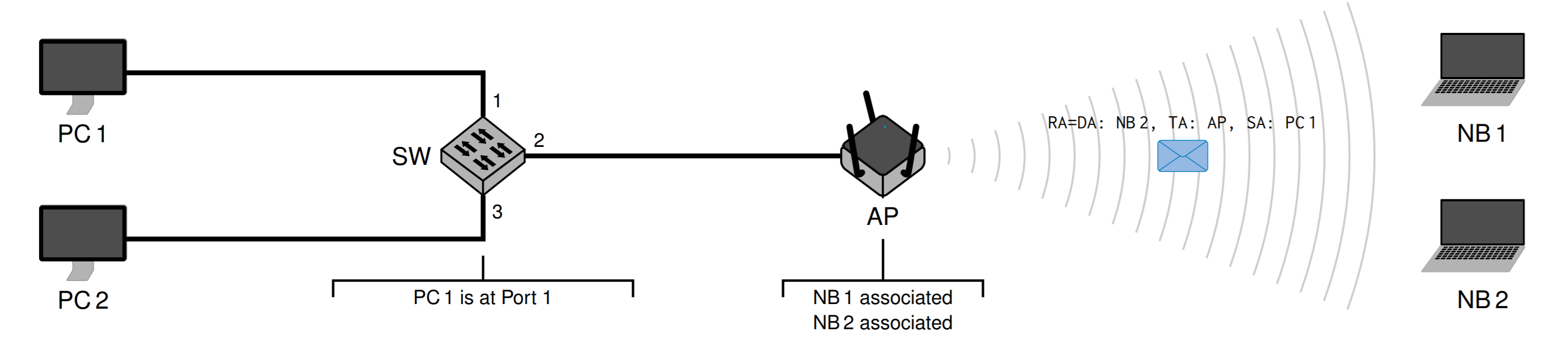
然后NB2再发送回来
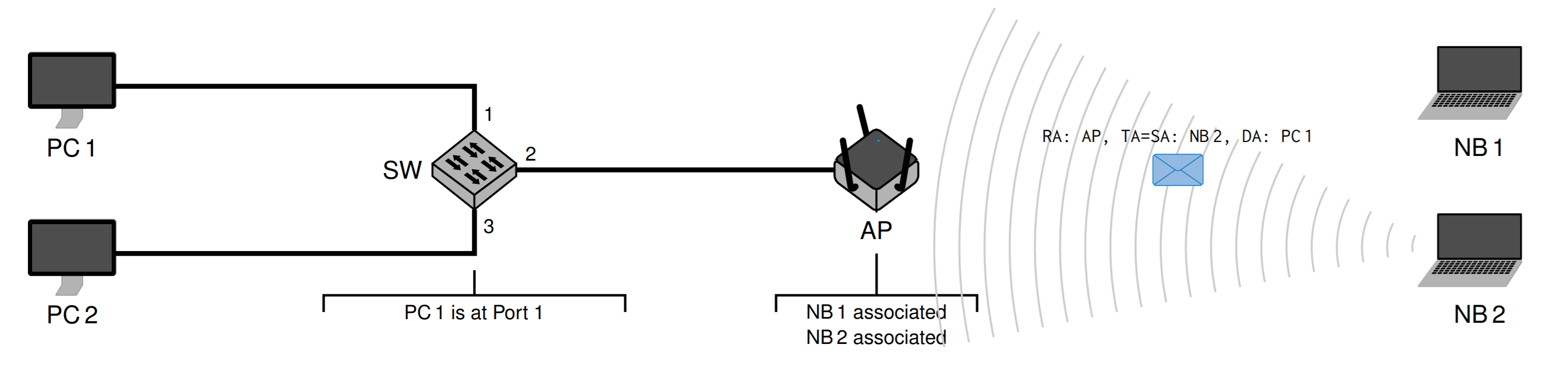
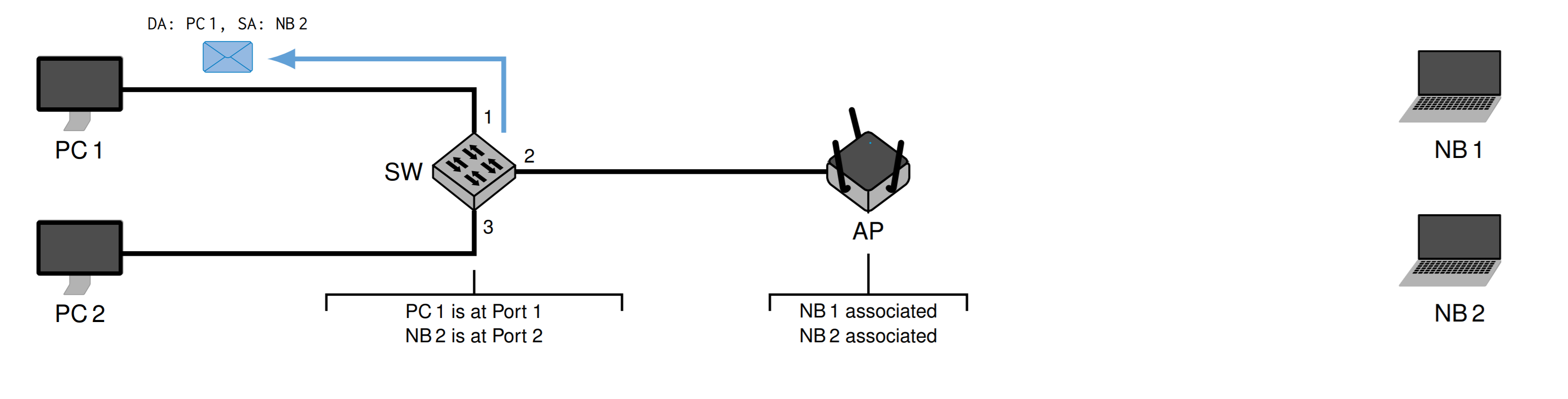
再发给交换机
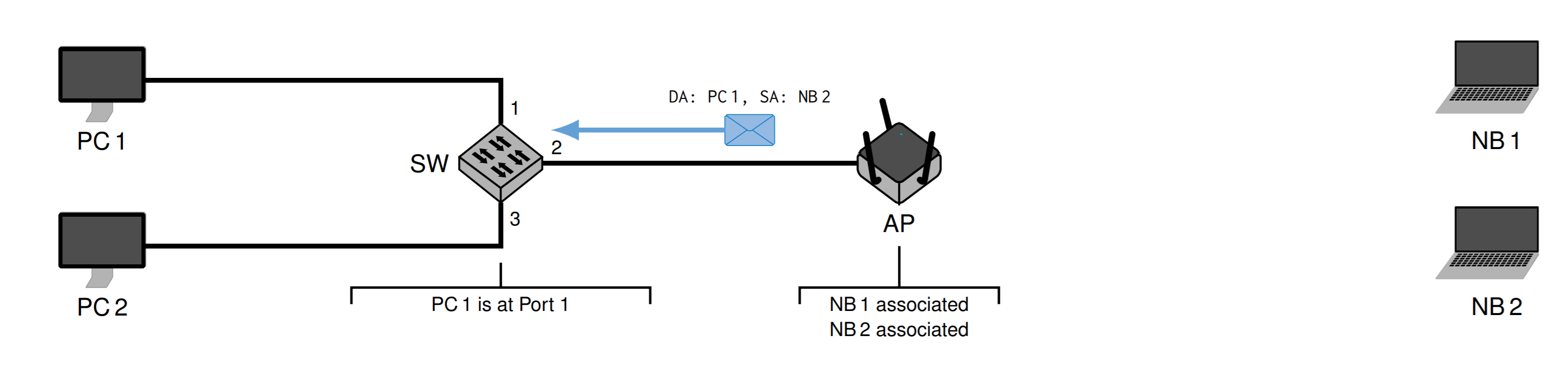
交换机知道PC1,所以只发个PC1
网络层Vermittlungsschicht
中转的类型Vermittlungsarten:
- Leitungsvermittlung
- Nachrichtenvermittlung
- Paketvermittlung
Leitungsvermittlung电路交换
有3步
- 建立连接Verbindungsaufbau
- 交换数据Datenaustausch
- 断开连接Verbindungsabbau
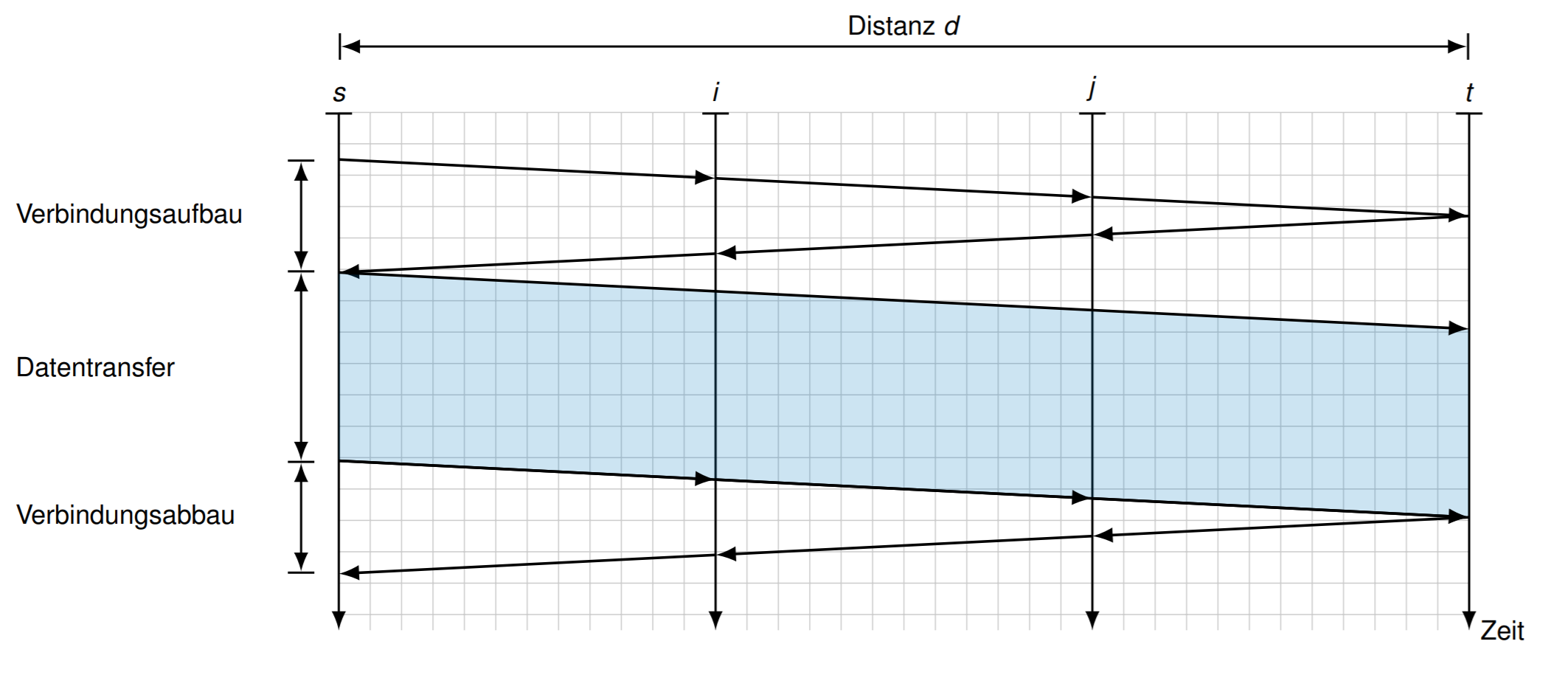
计算传输时间: \[ T_{L V}=2 t_{p}+t_{s}+2 t_{p}=t_{s}+4 t_{p}=\frac{L}{r}+\frac{4 d}{\nu c_{0}} \] 优点:
传输质量稳定,传递快速,不需要其他传递
缺点:
如果不一直用的话,会浪费资源。建立连接复杂。建立物理连接花费高
报文交换
长度为 \(L\) 的信息会加入长度为 \(L_H\) 的头

头包含发送者,接收者地址,中站站以及一些信息。然后头和信息一起传输
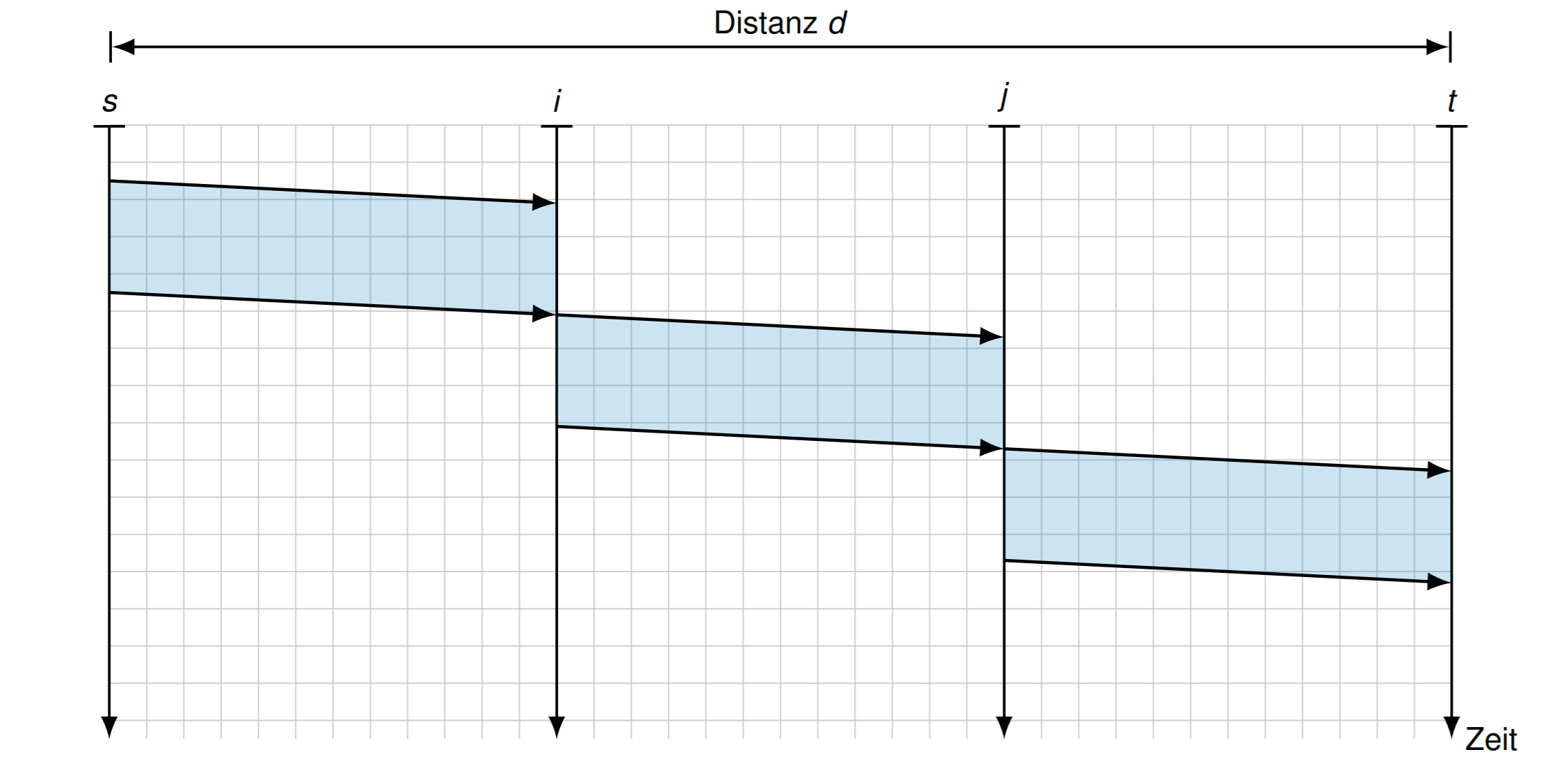
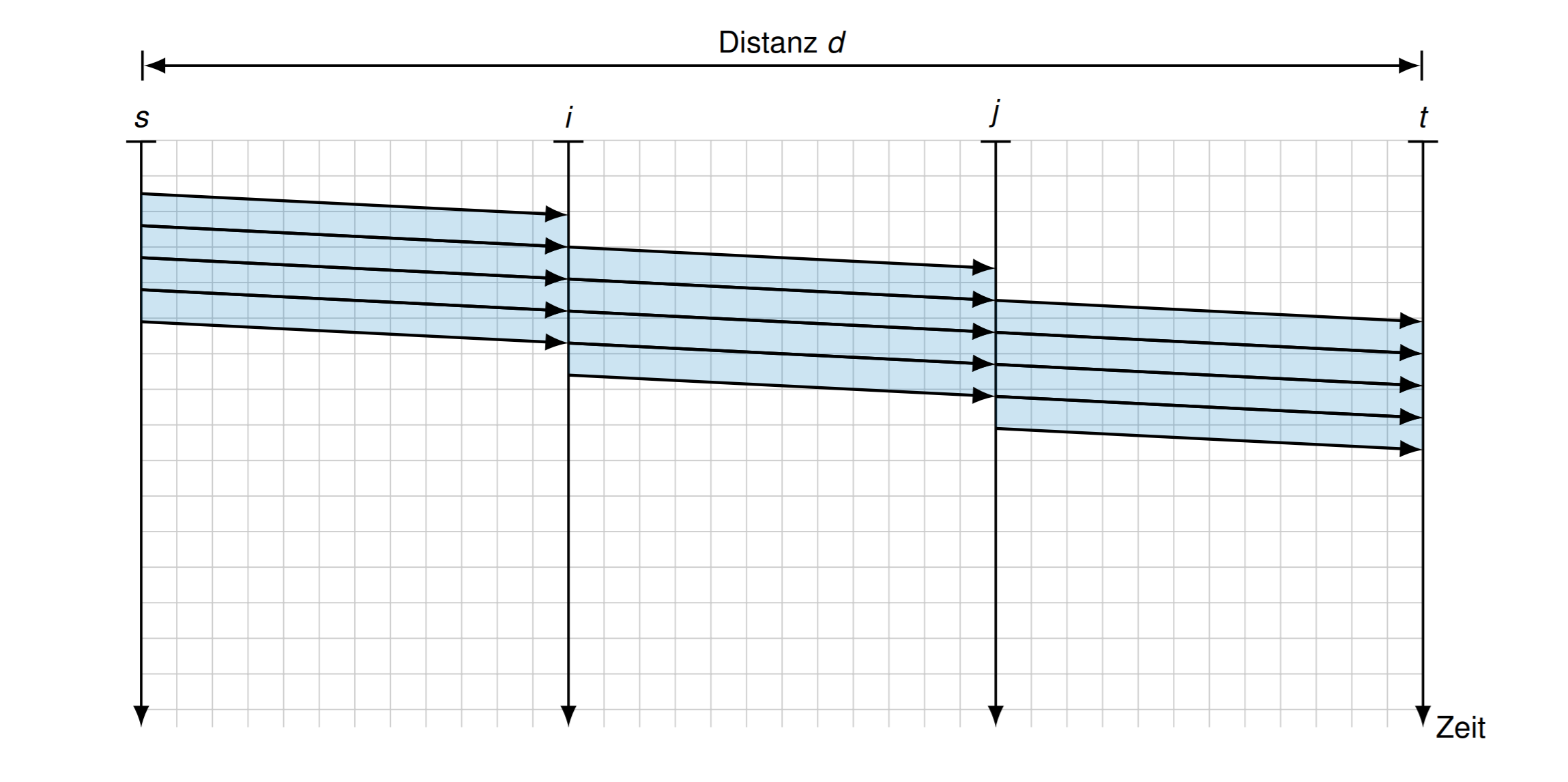
如果有2个中转站: \[ T_{N V}=(n+1) \cdot t_{s}+t_{p}=(n+1) \cdot \frac{L_{H}+L}{r}+\frac{d}{\nu c_{0}} \] \(t_s\) 是序列化时间,\(t_p\) 是总共传输时间
Multiplexing的情况:
如果是多个在一起的话,可以重复使用某个路段,称为(Zeitmultiplex) (Time Division Multiplex, TDM)
优点:
Flexibles Zeitmultiplex von Nachrichten
节约资源,开始没有建立连接的延迟
缺点:
如果 \(i,j\) 在使用中,那么信息传输会被缓存Pufferung
如果 Puffer 有限,那么会丢失信息
同一个信息会有多次序列化时间
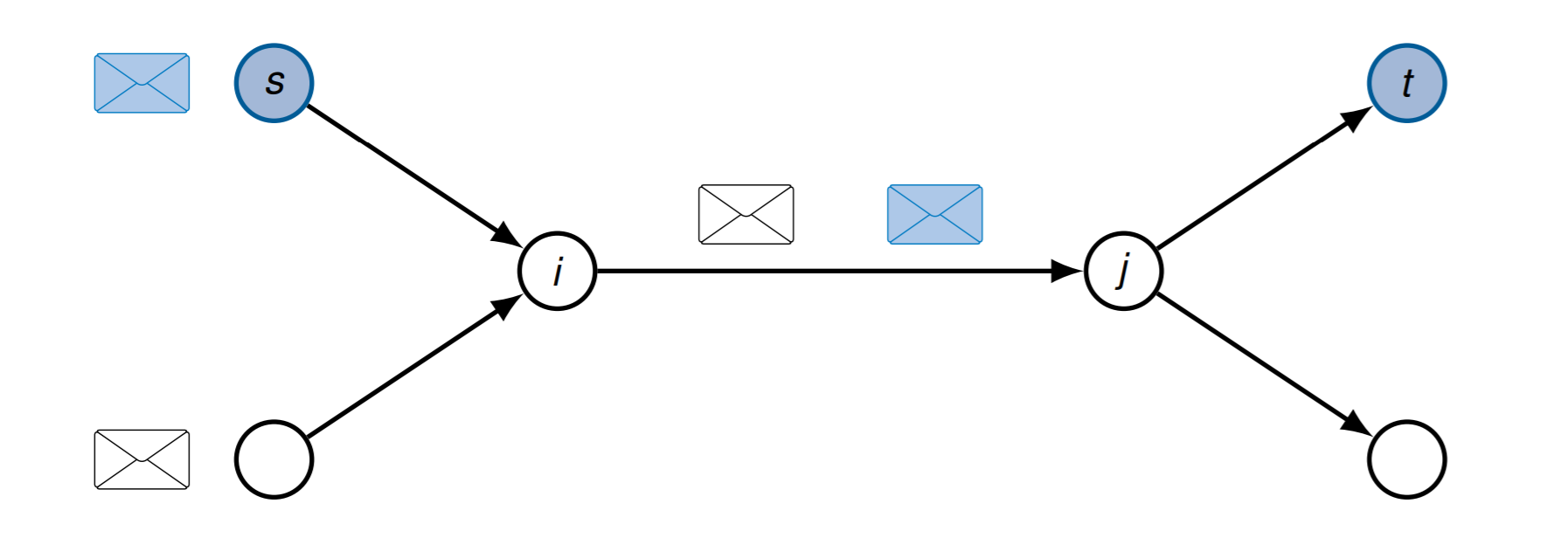
分组交换
信息被分成若干个小单元,分次发送

每个小单元会有自己的头
每个小单元不一定是相同长度的,但是有一个长度的上限\(p_{max}\)
此时的传输时间是: \[ T_{P V}=\frac{1}{r}\left(\left[\frac{L}{p_{\max }}\right] \cdot L_{h}+L\right)+\frac{d}{\nu c_{0}}+n \cdot \frac{L_{h}+p_{\max }}{r} \] 如果是多个传输的话
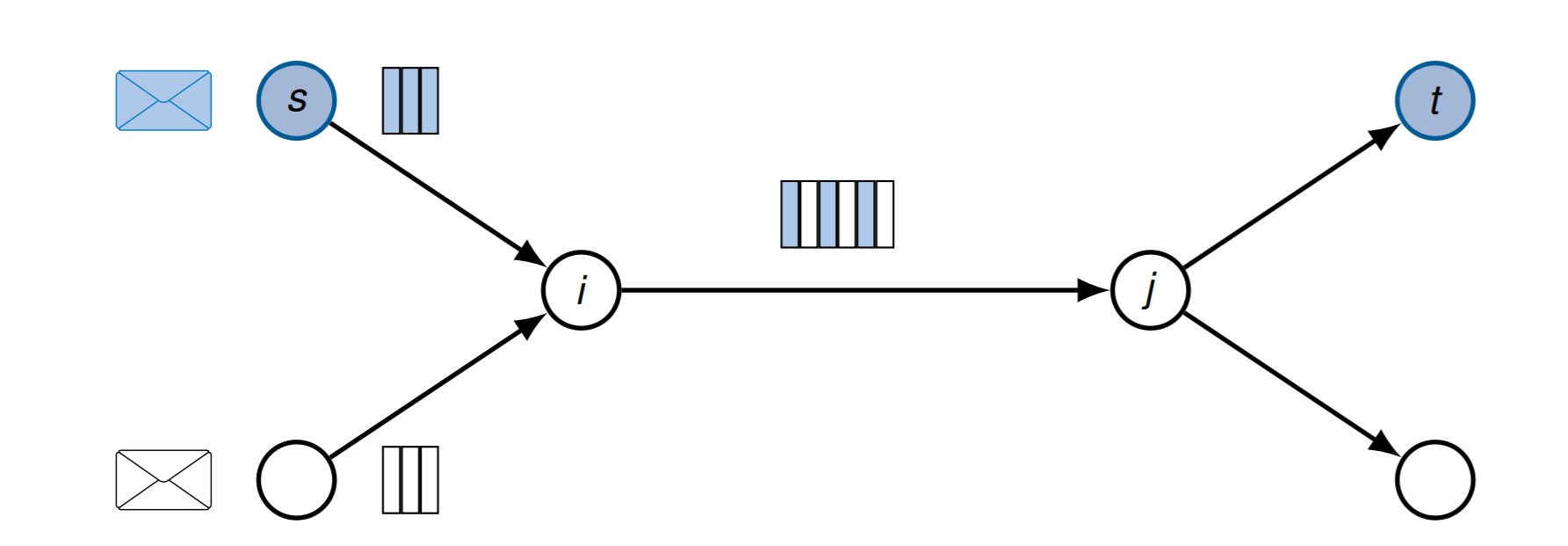
如果丢失包了,只需要重新发送一小段
优点:
Flexibles Zeitmultiplex einzelner Pakete
只需要缓冲小的数据包
缺点:
可能会丢失数据包,每个数据包必须有头,接收者要重新组合数据包
网络中的地址
IPv4 (Internet Protocol v4)
我们考虑一个路由器的网络
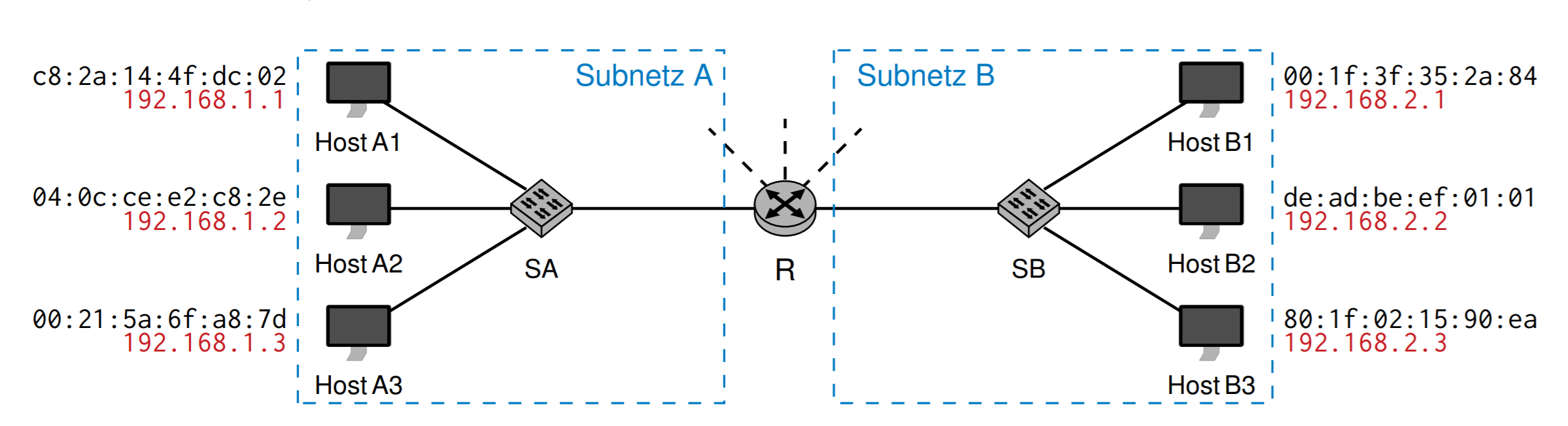
每个主机有一个IP地址,每个IP地址是四组数字用点分隔
每个发送包要有发送者的IP和接收者的IP

IPv4-Header

Version是IP地址的版本,可能的值是 4 和
6
IHL (IP Header Length)
是IP头长度,长度一般是32bit 的倍数
TOS (Type of Service)区分服务,
Total Length
- 这个IP包裹的长度(Header+Daten)
- 最长的是
65535 B
标志Flag:
- DF(Don't Fragment) 不能分片
- MF(More Fragment) 后面还有分片(=1), 后面没有分片(=0)
Fragment Offset片偏移:
该分片在原来数据中的位置
生存时间TTL(Time To Live):
表示这个数据的再网络中的寿命,转发一次就减1,0就丢弃
协议Protocol 如 TCP,UDP
首部检验和Header Checksum 只检验数据报的首部,只检查,不修改
源地址Source Address 发送者的IP地址
目的地址Destination Address 接受者的IP地址
可变部分Options / Padding IP支持的选项可以填在这里,如果不足4B的倍数可以在这里填充
在发送之前要把 Host Byte Order (Little Endian bei x86) 转成 Network Byte Order (Big Endian)
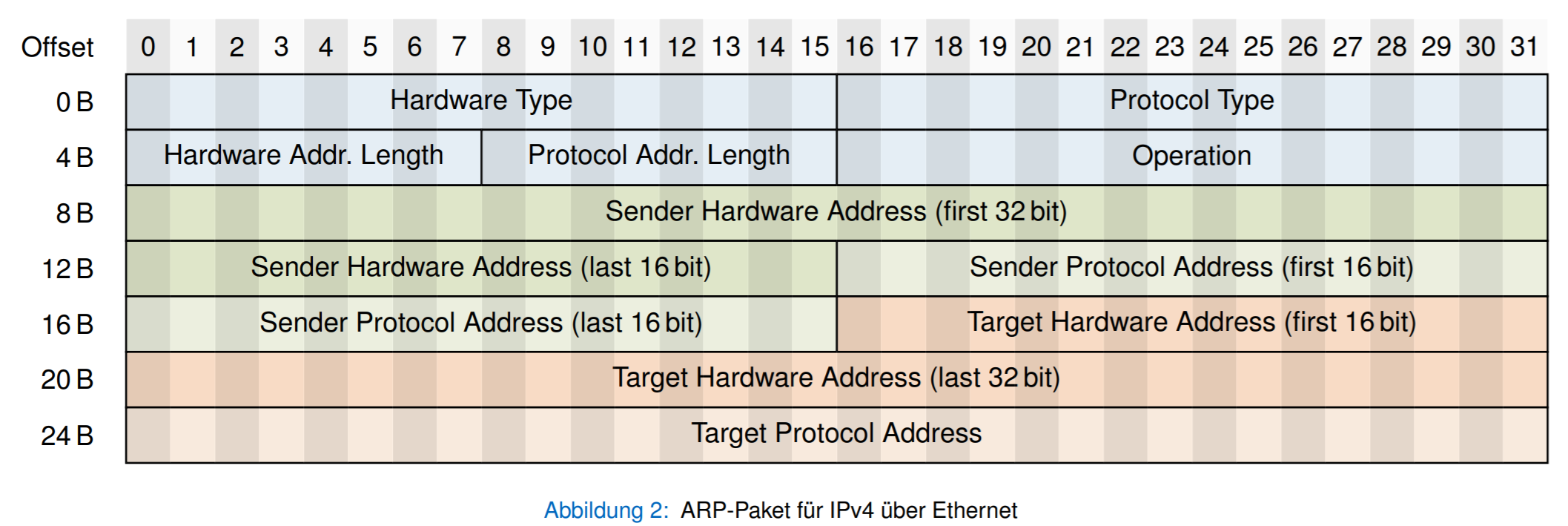
ARP请求
主机1知道主机2的IP地址,但不知道它的MAC地址。所以主机1发送一个ARP请求,询问主机2的MAC地址。然后主机2发送ARP回复,回复它的MAC地址
ICMP协议
IP协议支持发送数据包到目的主机,但是可能会发生问题:包陷入死循环,不能找到目标主机,不能解析MAC地址...
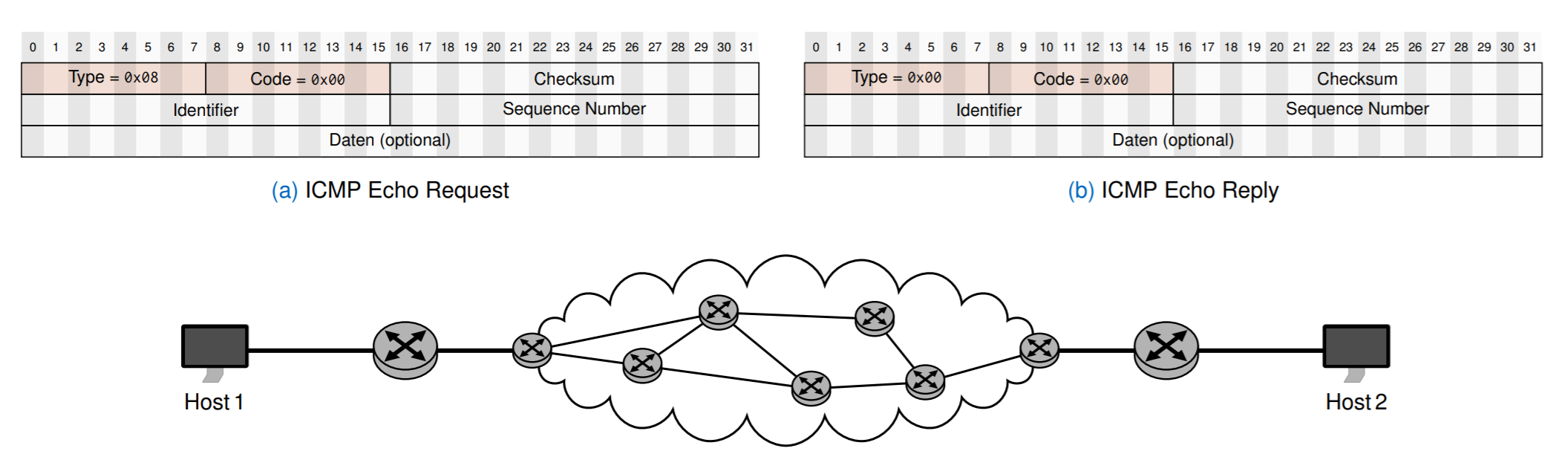
ICMP可以告知发生的错误类型和支持其他操作,如Ping,Redirect

从主机1 Ping 主机2
首先主机1选择一个随机的Identifier(16bit), Echo Request像IP包那样传递。如果主机2拿到了 Echo Request,那么它会回复 Echo Reply。如果出错了,ICMP互发回一个错误码
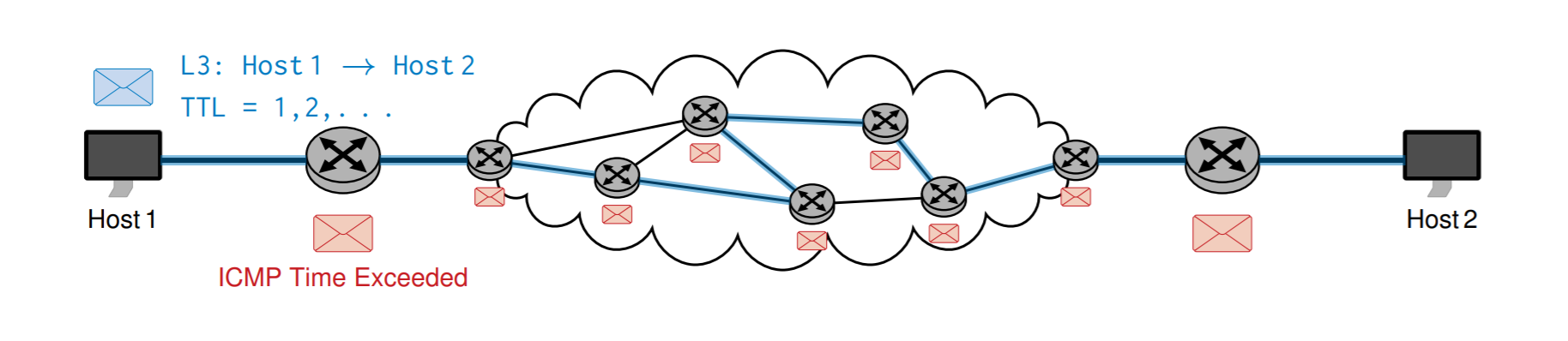
如果包的TTL变成0了,那么会返回超时的错误
ICMP还可以Traceroute,跟踪数据包经过的节点
它发送若干个数据包,第一次发送一个 TTL=1的,第二次TTL=2的,然后就能知道经过哪些节点了
Dynamic Host Configuration Protocol (DHCP)
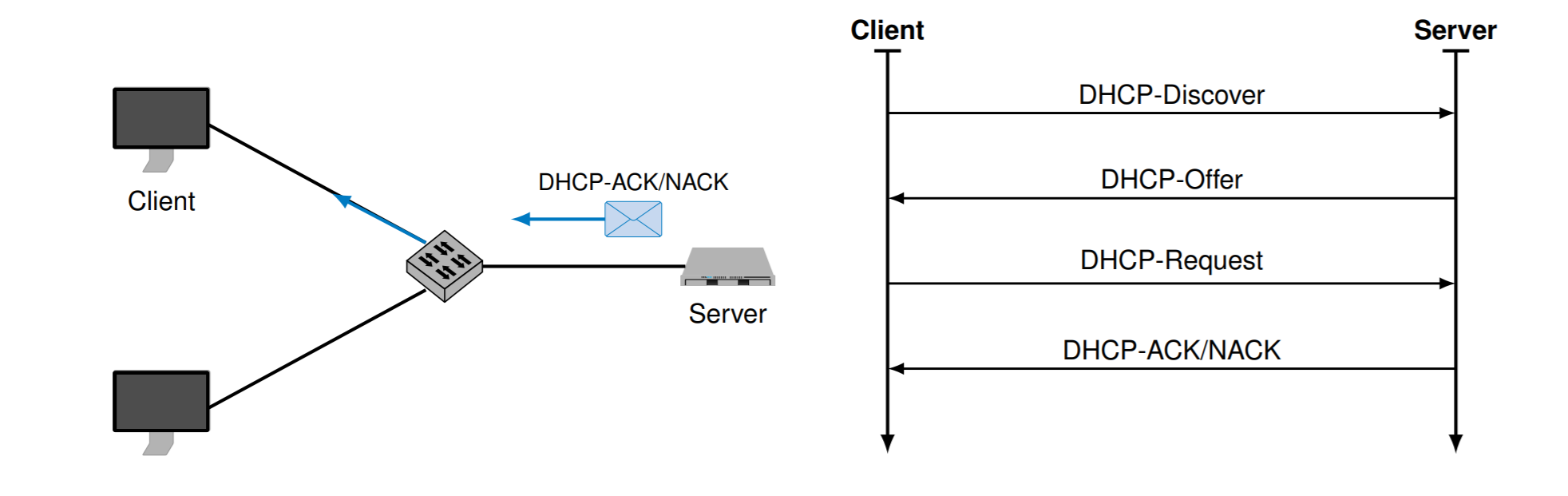
主机如何获得IP地址:自动分配(通过DHCP服务器)和手动分配
首先客户端发送DHCP-Discover(广播),DHCP服务器回复DHCP-Offer里面有分配的IP地址。
客户端回复DHCP-Request 表示确定要这个地址,然后DHCP服务器回复DHCP-ACK或者 DHCP-NACK表示接受或者拒绝。
IP地址的类型分成5类

因为后来IP地址不够用了,于是就引入了子网的概念Subnetze
网络接口除了IP地址外,还有32bit的子网掩码Subnetzmaske
子网掩码把IP地址分为网络部分Netzanteil和主机部分Hostanteil
1表示Netzanteil,0表示Hostanteil
IP地址和子网掩码共同组成网络地址Netzadresse

IPv6
它与IPv4的变化主要是:增大了IP地址到128bit,简化了头,改变了IP-Fragmentierung..
IPv6地址和IPv4地址类似,但是分成了16组
 \[
2001:0db8:0000:0000:0001:0000:0000:0001
\] 对于这个地址
\[
2001:0db8:0000:0000:0001:0000:0000:0001
\] 对于这个地址
多个0可以用1个0表示: \[ 2001:db8:0:0:1:0:0:1 \] 最前面的最长的连续0可以省略 \[ 2001:db8::1:0:0:1 \]
IPv6头
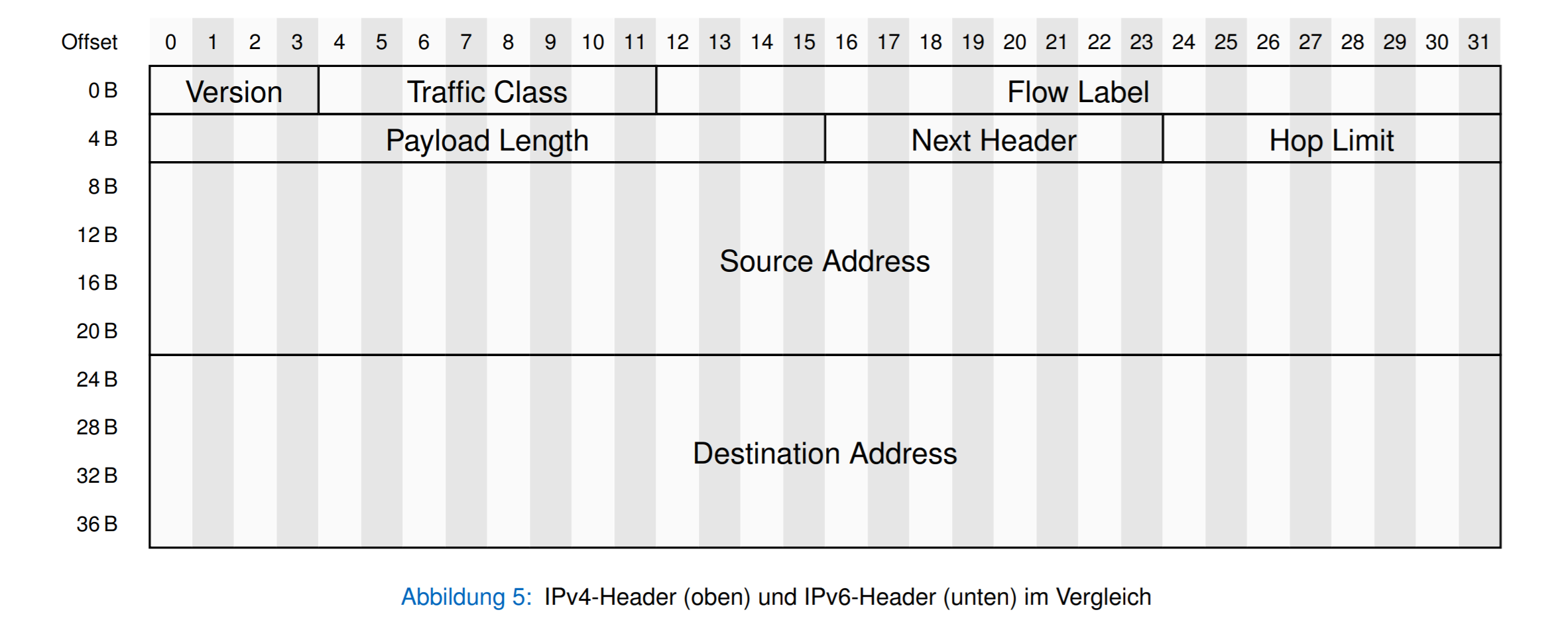
Traffic Class:和IPv4的TOS类似
Flow Label:用于识别哪些数据包是在一起的
Payload Length: 后面数据的长度
Next Header: 下一个头的类型(如TCP,UDP)
Hop Limit : 对于Ipv4 的 TTL
扩展的IPv6协议支持把 Layer 3的信息也一起打包
特殊的IPv6地址
::1/128 Localhost
::/128 未指定的地址
fe80:: / 10 – Link-Local Adressen
fc00: / 7 Unique-Local Unicast-Adressen
ff00:: / 8 Multicast-Adressen
Multicast
ff02::1 – All Nodes
ff02::2 – All Routers
ff02::1:2 – All DHCP-Agents
ff02::1:ff00:0/104 – Solicited-Node Address
从 IPv6地址映射到MAC地址 \[ f f 02:: 1: f f c 6: 938 b \quad \mapsto \quad 33: 33: f f: c 6: 93: 8 b \]
SLAAC
IPv6允许在子网里自动配置主机

前缀是 fe80::/10
Subnet Identifier 是 0
ICMPv6

Neighbor Discovery Protocol (NDP)
路由Wegwahl(Routing)
静态路由Statisches Routing
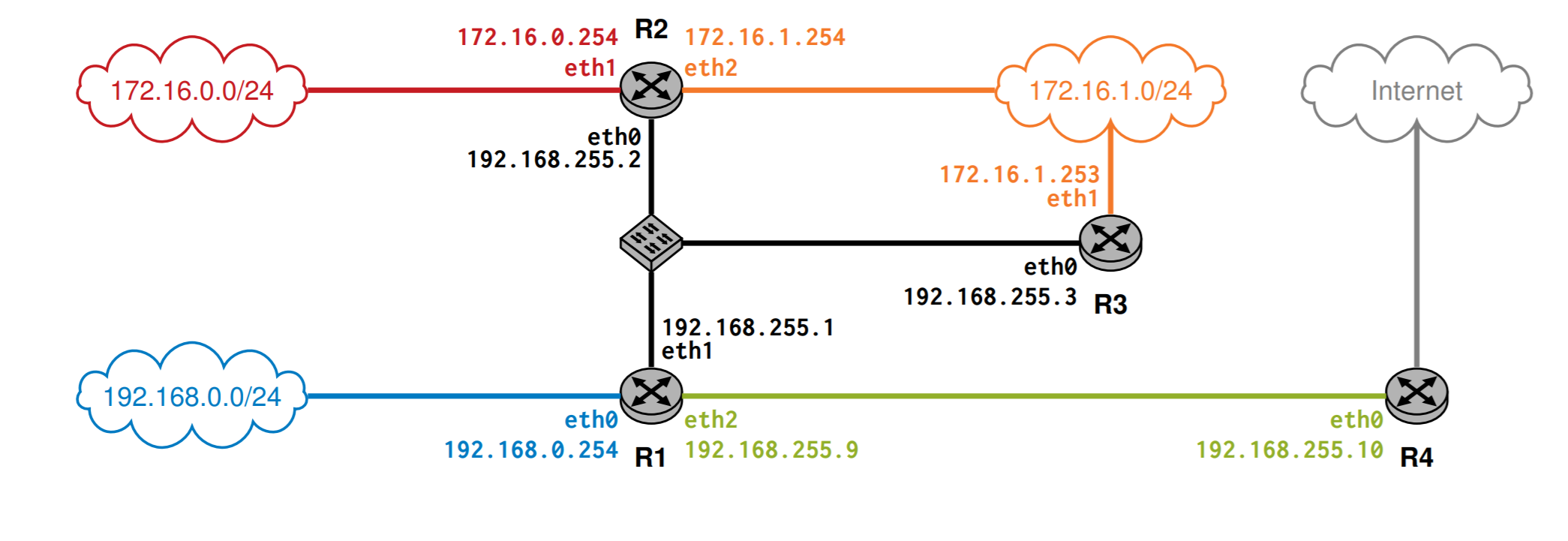
R1 如何确定数据包该往哪里走
Routing Table
在路由表里有
- 目标地址
- 前缀长度
- 下一个Next-Top(网关)
- 可以到大Next-Top的接口
- 达到目标的花费
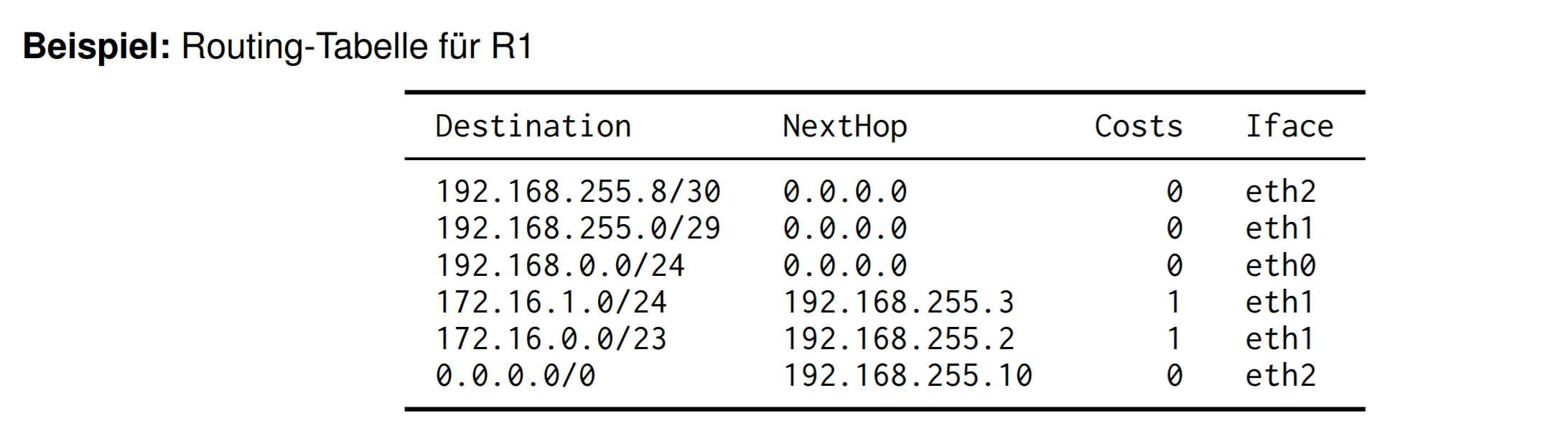
匹配最长前缀Longest Prefix Matching
动态路由
bellmanford算法,dijkstra算法
运输层
UDP
TCP
Sitzungsschicht
应用层Anwendungsschicht
网络安全
网络分析工具
Wireshark
1 | sudo pacman -S wireshark-qt |
用 sudo wireshark 来启动,这样才能读取到网卡信息
ARP协议
Socket抽象层是应用层和传输层直接的软件抽象层。它把TCP/IP协议封装成一个借口给程序员使用。
- 流套接字 TCP
- 数据表套接字 UDP
- 原始套接字 可以发送从应用层到链路层的数据。
VPN
VPN(Virtual Private Network) 是利用开放的公众IP网络建立专用数据传输通道,将远程的分之机构、移动办公人员连接起来。
按隧道网络
第二层隧道网络:L2TP,PPTP,L2F。
原始数据包 -> PPP封装-> L2TP封装 - > 新增ip头+L2TP头+PPP头+原始数据包
第三层隧道协议:如IPSec
SSTap-beta
 wechat
wechat alipay
alipay