
计算机架构笔记
一、冯诺依曼结构
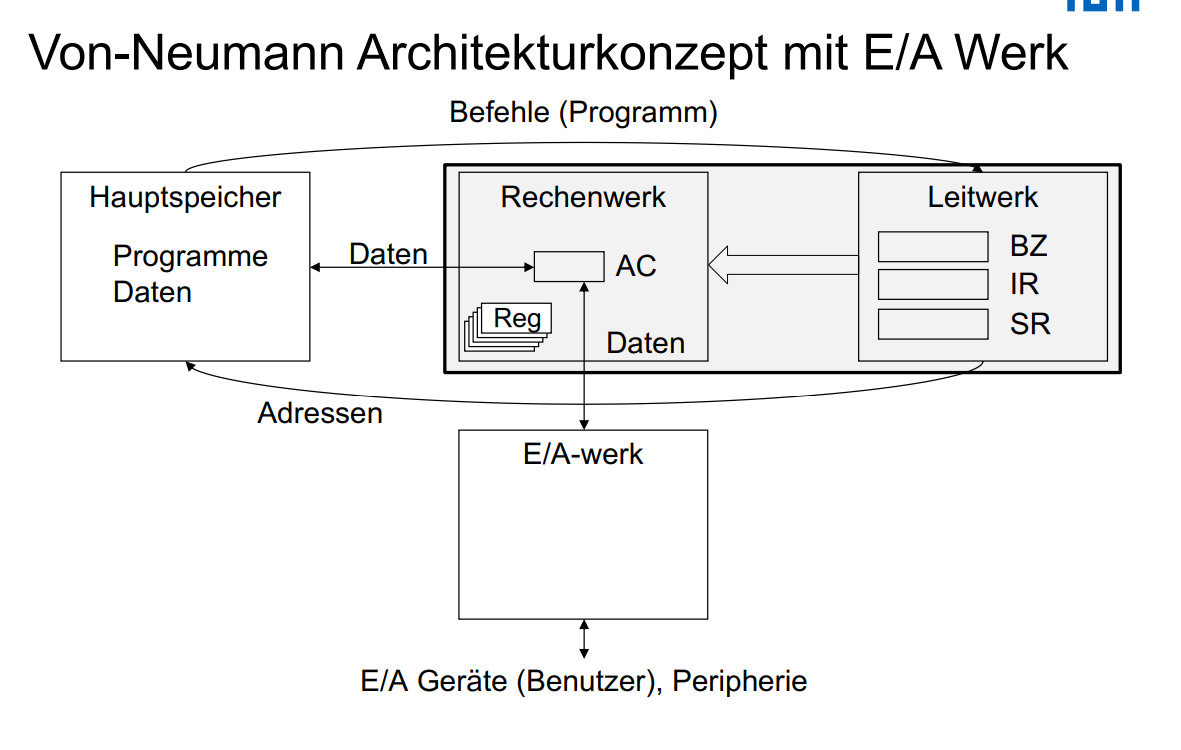
Von-Neumann 概念
- 计算机的结构与处理的问题无关
- 计算机由4个单元构成
- 主存储器里的格子是相同大小的,每个都有个地址
- 程序和数据放在相同的存储器里
- 使用二进制
- 程序由一系列命令构成
- 顺序可以通过跳转指令改变

Von-Neumann Architektur
RISC & CISC
CISC: Complex Instruction Set Computer
通过微程序实现
优点:易编程,少的存储需求
缺点:复杂的解码
RISC: Reduced Instruction Set Computer
- 通过固定接线(feste Verdrahtung)实现
- 优点:简单,高效的实施
- 缺点:难编程

Befehlsformat
Einadressform

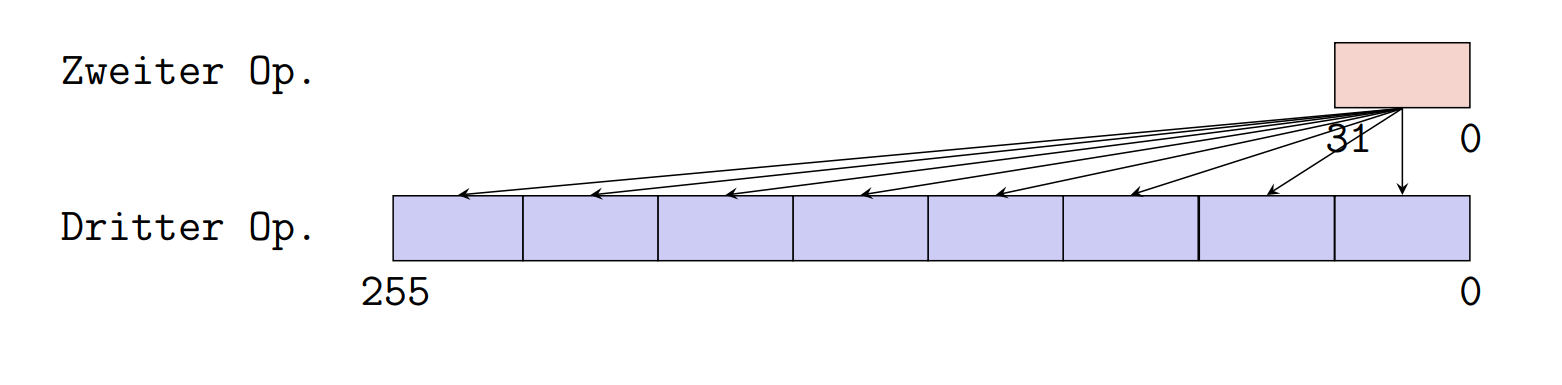
Zweiadressform(IA-32)
计算结果覆盖第一个操作数
只有一个操作数可以在主存储器里

Dreiadressform(CISC)
- 操作数和结果被准确寻址

Codierung


二、汇编/ISA
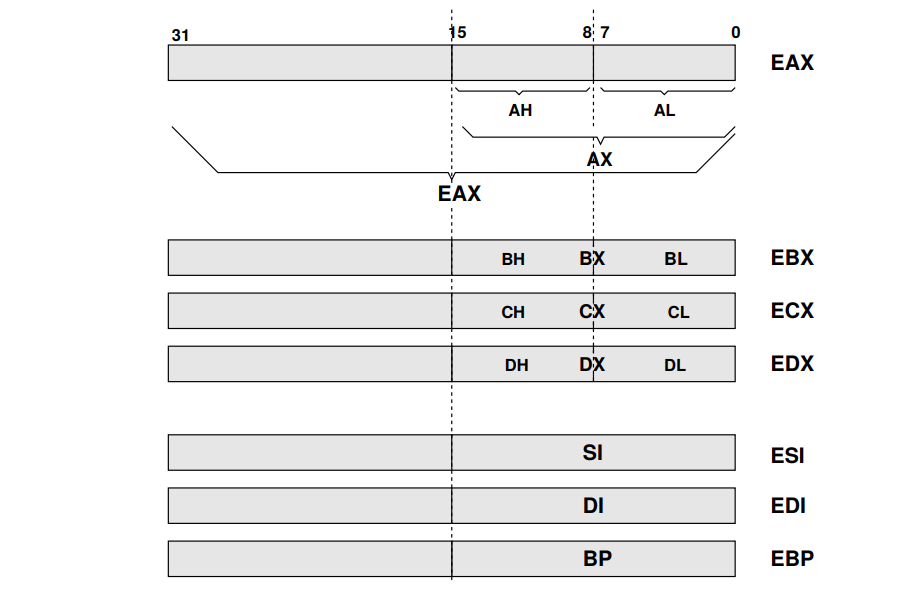
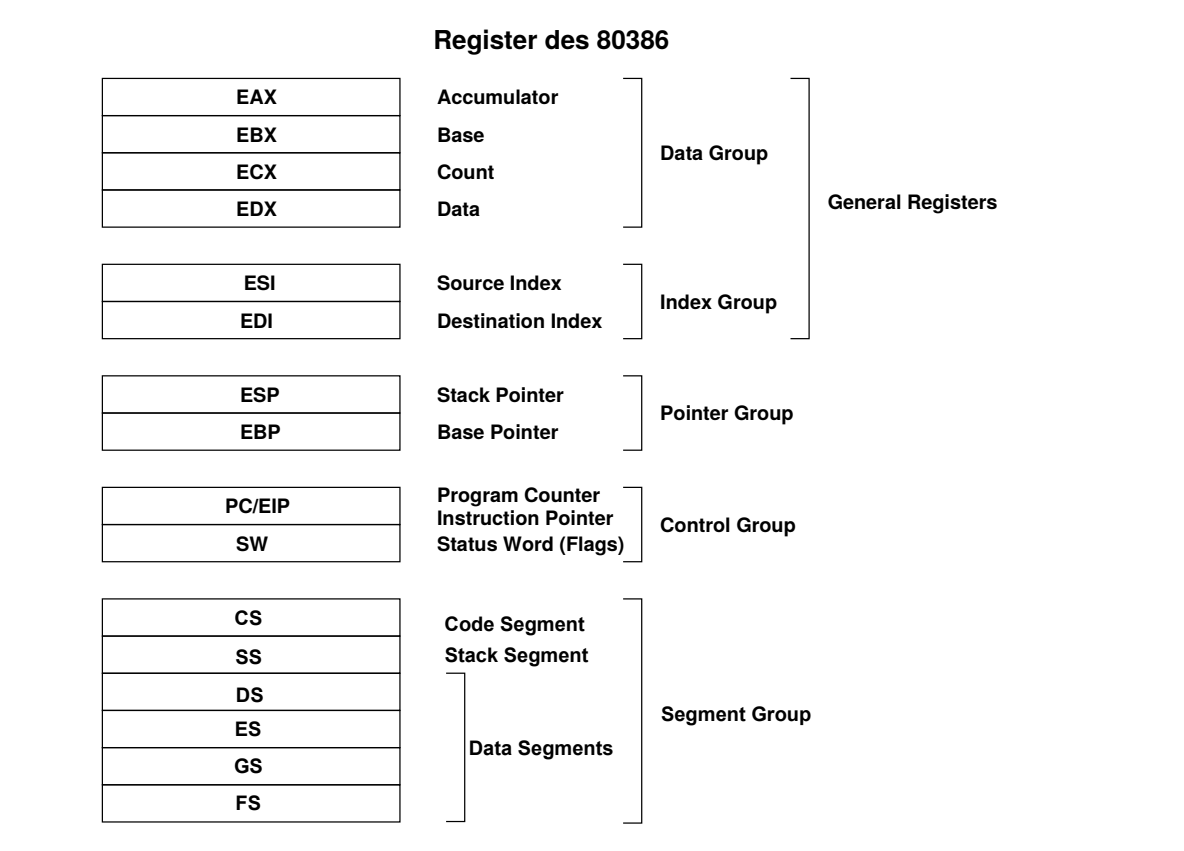
Register 寄存器
汇编指令
MOV
1 | mov ax, 10h |
ADD/SUB
1 | add eax, ebx ; eax := eax + ebx |
INC/DEC
1 | inc bl ; bl := bl + 1 |
NEG
1 | neg ecx ; ecx := -ecx |
MUL/IMUL
MUL是乘法,IMUL是带符号乘法
1 | mul ecx ; edx:eax := eax*ecx , 溢出部分存在edx里面 |
DIV
1 | div ebx ; eax := (edx:eax)/ebx , edx := 余数 |
JMP
1 | JMP 0x1234 ; EIP=0x1234 然后从0x1234继续执行 |
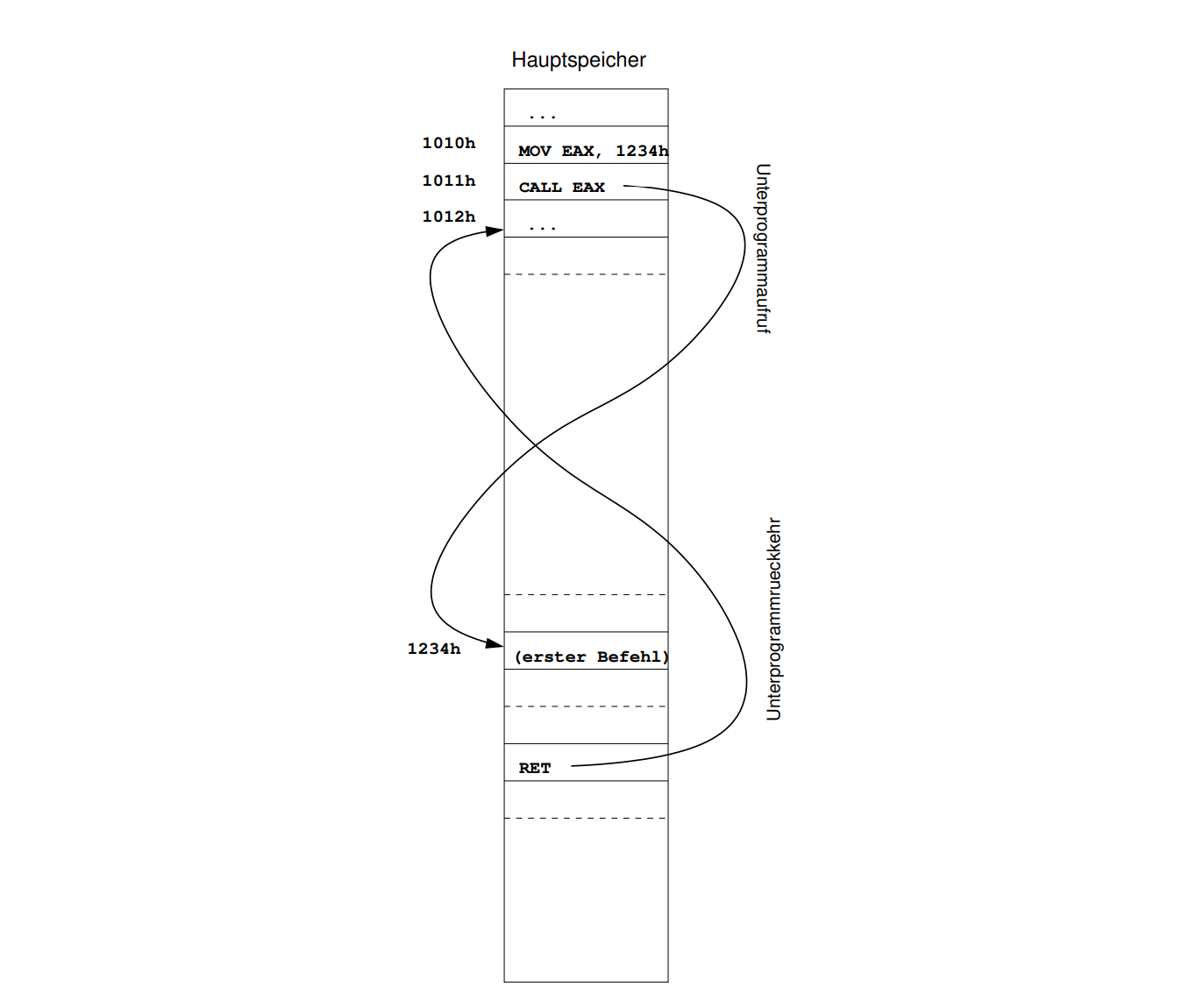
CALL/RET
调用子程序,CALL会额外执行PUSH EIP, RET额外执行POP EIP
汇编语法
EQ
1 | startwert: EQU 15 ; 定义startwert为15 |
SASM 特色语法
1 | PRINT_UDEC 2, dx |
例子
1 | %include "io.inc" |
Flags
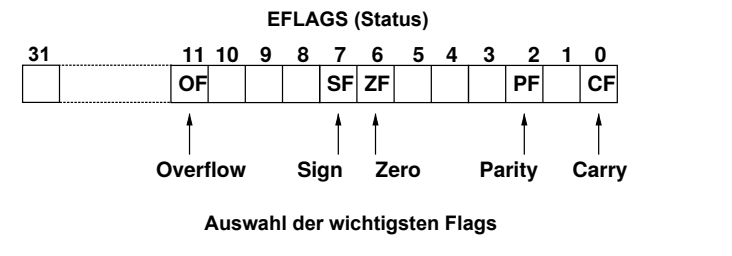
CF
carry flag,进位标志,最高位进位为1
1 | sub eax, ebx ; cf = 1 if eax < ebx |
SF
sign flag,符号标志,负号为1
OF
overflow flag,溢出标志,溢出为1
ZF
zero flag,结果为0标志,为零为1
跳转指令
1 | CMP EAX,5 |
逻辑运算
SAL/SAR 左移, 右移, 带符号 (最高位是1,位移补1)
SHL/SHR 左移右移,不带符号
ROL/ROR 带循环左移
RCL/RCR 带循环左移
1 | MOV AX,0x8421 ; 1000 0100 0010 0001 |
Virtuelle Speicherverwaltung
三、Mikroarchitektur
12.1 Schaltnetze(组合逻辑电路)
Schaltenetze是Mikroarchitektur里最小的组成元素,它是没有“思想”的。常见的有Multiplexer, Dekodierer, Tore, Addierer
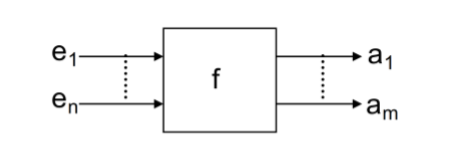
12.1.1 Multiplexer(MUX)(数据选择器)
Multiplexer是一个基本单元。它有n个输入信号,输出一个单独的信号。有一个控制型号会决定那哪个信号会输出
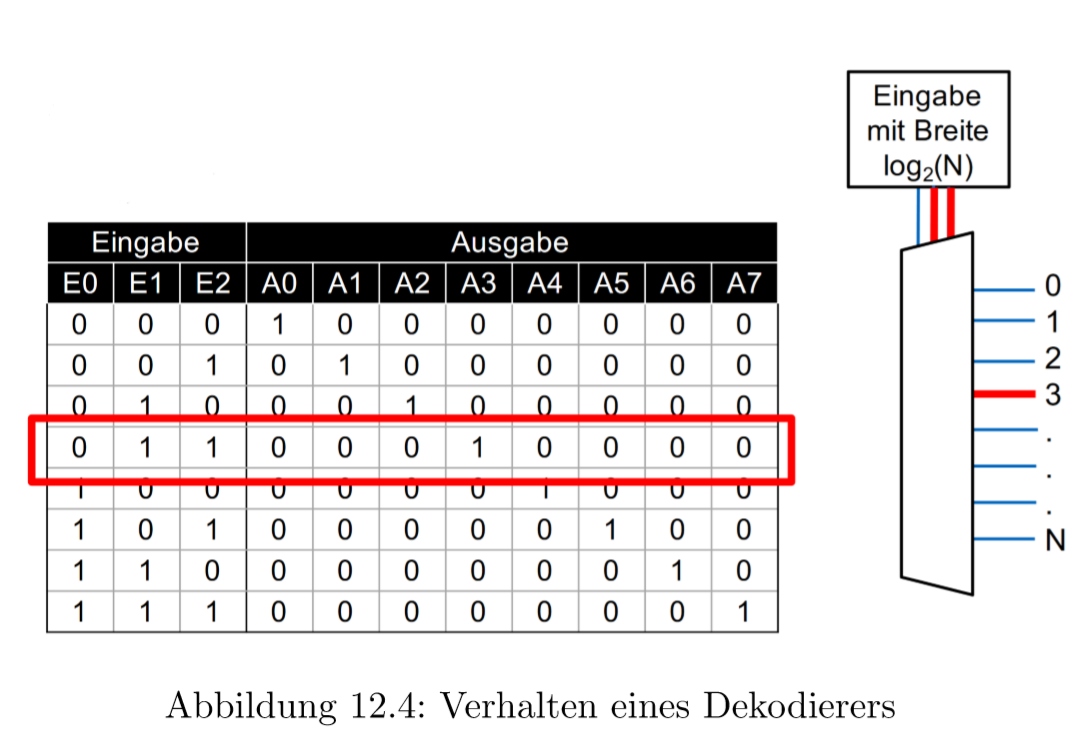
12.1.2 Dekodierer
Dekodierer会把一串输入的二进制码转换成单一的信号输出。输出的长度是\(N\)(1个是1,其余是0),输入的长度是\(logN\)
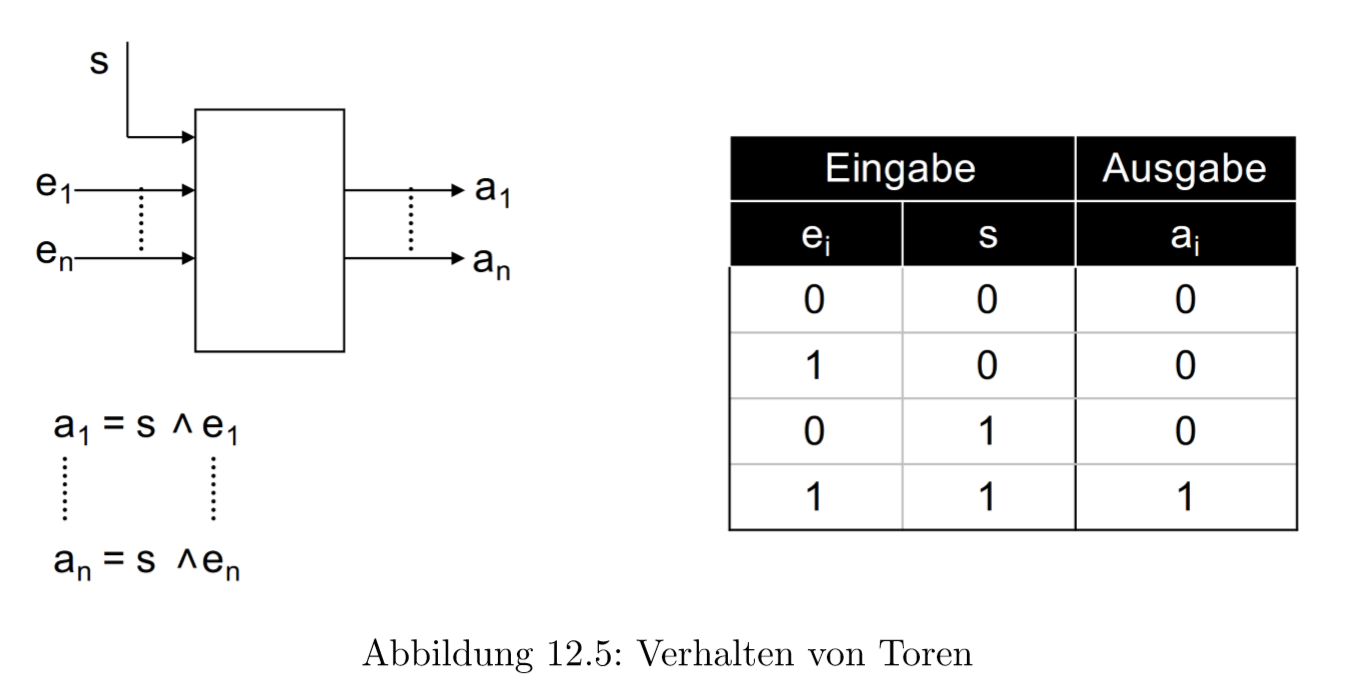
12.1.3 Tore
Tore 会把决定输入的信号是否继续传递。如果控制信号是1就继续传递,否则就终止继续传递。
12.2 Schaltwerke(时序逻辑电路)
Schaltwerke 和 Schaltnetze相反,它是有“思想”的。因为它有一个传入的函数。比如寄存器(Register)和存储器(Speicher)是Schaltwerke的种类。每个Schaltwerk是和Signalleitungen相关联。下面左边是Schaltnetzen右边是Schaltwerke
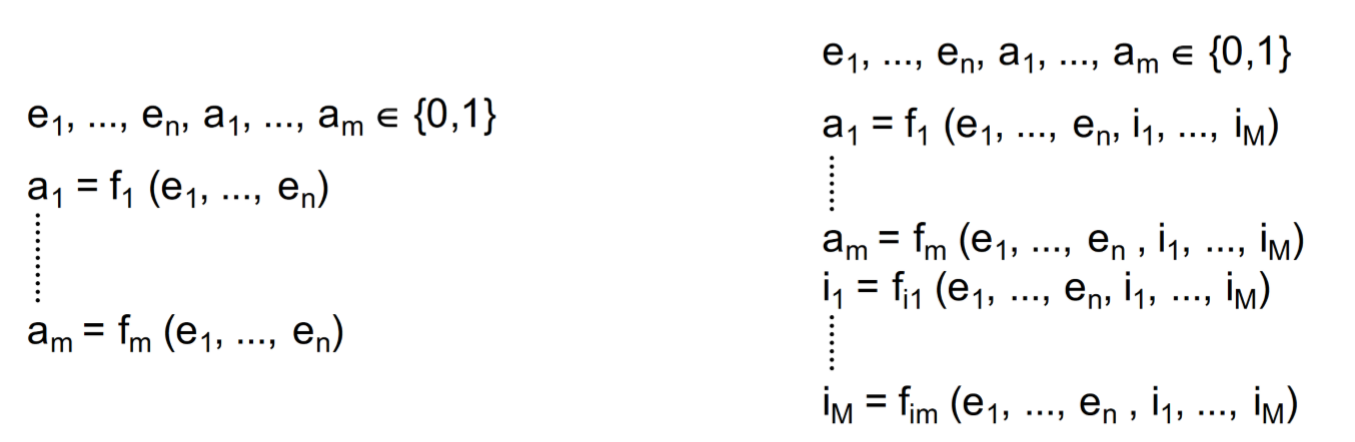
12.3 Implementierungsoptinoen 实现选项
Mikroarchitektur 的任务是在作为指令循环(Befehlszyklus),独立数据转换(individuelle Datentransfers),操作逻辑块(Blöcke für Operationslogik)来实现ISA层。
- "Fest verdrahtete" Architekturen,固定的结构
- Programmierbare Architekturen,可编程的结构
12.3.1 "Fest verdrahtete" Architekturen
它有一系列的开关(Schaltungen)组成,也就是无论指令还是信号控制都会被直接实施。它直接对于了Gatter层
优点:高表现 höhere Performanz
缺点:
- 开发成本高 Zeitaufwändige Entwicklung
- 易受错误影响 Fehleranfällig
- 难移植 Schwer anpassbar
12.3.2 Programmierbare Architekturen
所有的ISA指令编码(Opcodes)会在控制单元(Steuerwerk)解码。每个指令编码会执行在微程序存储器(Mikroprogrammspeicher)里存储的子程序。每一个ISA 指令都有一个微程序。它的执行由Leitwerk来做。
优点:
- 设计简单
- 指令的分解
- 控制的时钟控制 Kontrollierte Taktsteuerung
- 易改变
- 易改错
缺点:速度慢
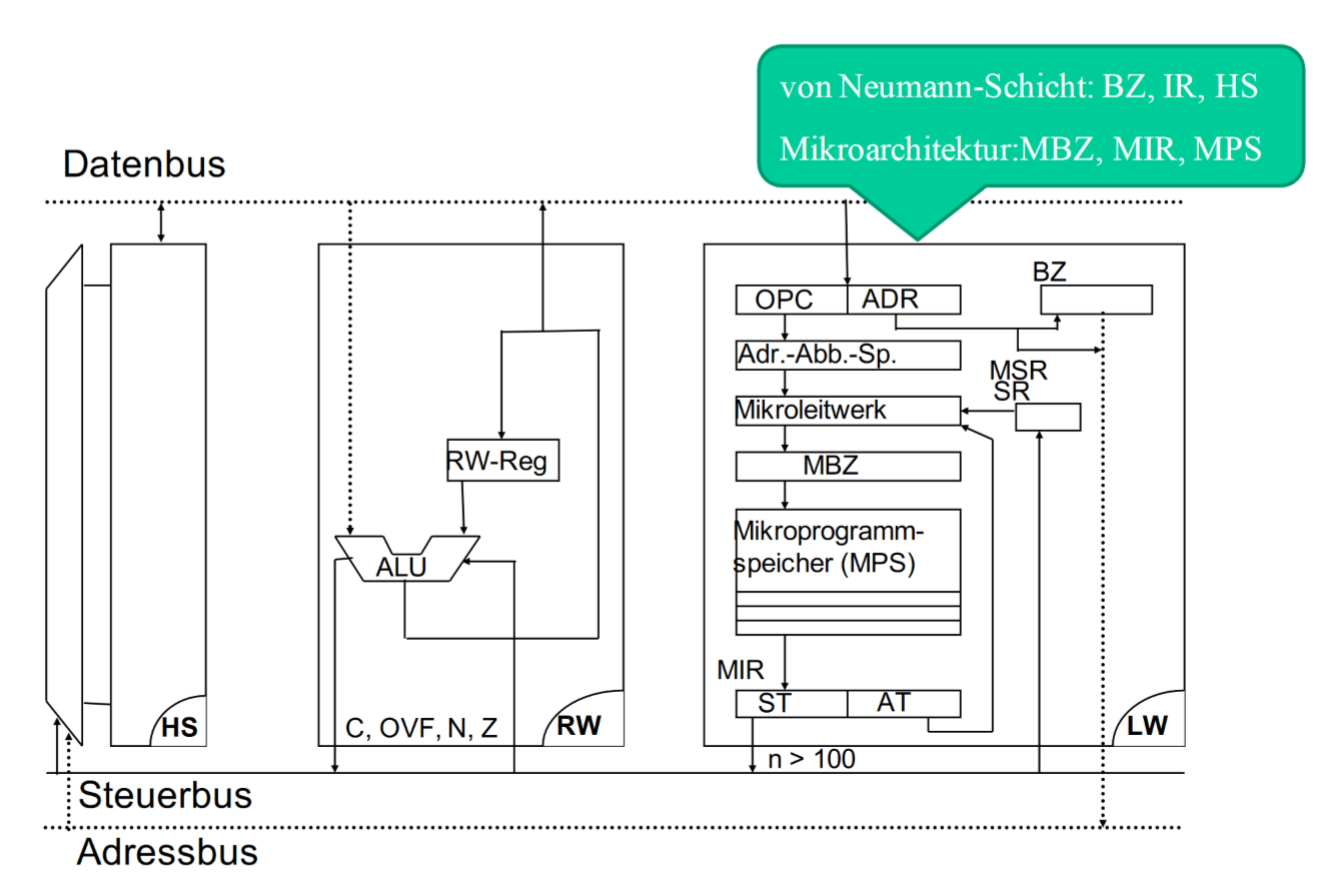
12.3.3 Mikroprogrammzyklus
每一个微程序有一个执行的过程
1、确定下一个微指令的地址(IFETCH)
2、从Mikroprogrammspeicher里读取指令
3、把指令放入微指令寄存器(Mikroinstruktionsregister)简写(MIR),它是信号缓冲器,它控制整个系统的信号
4、控制信号执行所有单元里的操作(Rechenwerk, Busse, Leitwerk)
这个微程序的执行是时间脉冲控制的(taktgetrieben)。就是说有个外部的时间脉冲Takt,它控制这个控制信号什么时候和多长时间是有效的。在时间脉冲里只有0和1的互换。这两个值代表一个给定的时间点。一个时间脉冲循环对应了2个“上升边”中间的时间。从0变成1是“上升边”,从1变成0是“下降边”。人们使用时间脉冲,因为Schaltnetze 和 Schaltwerke需要一定时间来把生成所有信号。让这些信号传递需要其他的Schaltnetze/werke。
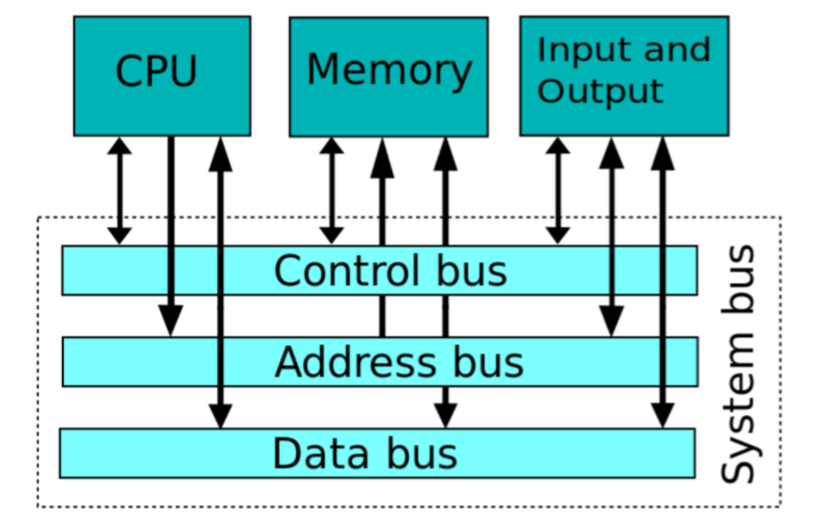
12.3.5 Daten- und Adressbus
下面介绍数据总线和地址总线。在计算机里有很多数据和地址线路。他们和Leitwerk, Steuerwerk, E/Awerk, Speicher相连接。对于大量原件来说,点对点的连接是不实际的。所有就有了总线。在一个总线里,许多原件可以“挂”在上面读取信息。通常情况下,总线会有数据线路(Datenpfaden),地址线路(Adressenpfade)和控制线路(Kontrollpfade)。除了这种读取,还有存取控制(Zugriffkontrolle),它为了知道谁被允许进行读写操作。从而避免冲突。
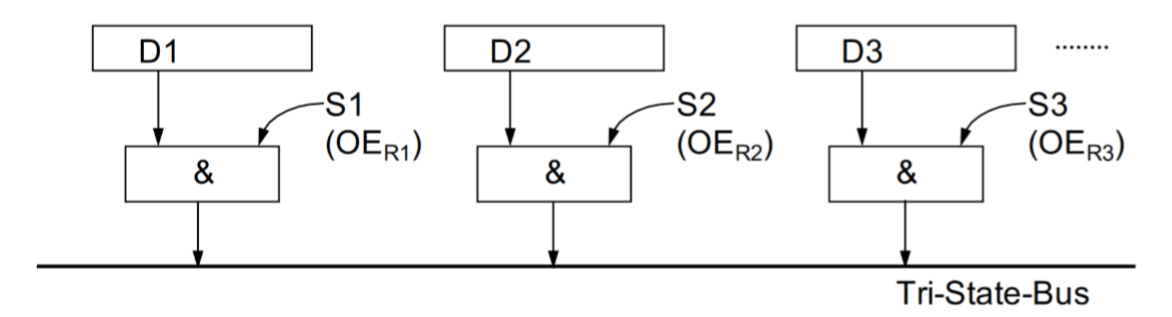
Tri-State Bus
Tri-State Bus是可以多重使用的管道。我们使用Multiplexer来实现它。\(S_{i}\)是控制信号,\(D_{i}\)是数据,\(OE\)是Output Enable,表示可以被输出,它由控制信号来控制。在同一时间只有一个数据在Bus上
12.3.6 Mikroinstruktionen
为了实现微指令,我们需要微指令寄存器(Mikroinstruktionsregister)他是一个很长的为1Bit信号控制,多Bit信号控制,和Immediates而造的Bit数组。

- 1 Bit Signal 它是比如Kontroll-Bus-Signale (R/W), 单个门的输出,Tri-State Bus控制
- Mehrbitsignale 通常是Dekodierer和Multiplexer的输入
- Immediates 这是微程序的地址,或者常数
对此有个编码的对微指令的展示,它不是控制单个信号,而是控制信号组。优点是对存储空间的减少和编程友好性的提升,缺点是解码会耗时间,对硬件的要求高。
Mikroinstruktionsformat
微指令格式可以分为3个种类。水平(Horizontal)(不加密),垂直(Vertikal)(严格编码)和,类水平(Quasihorizontal)(最优编码)。
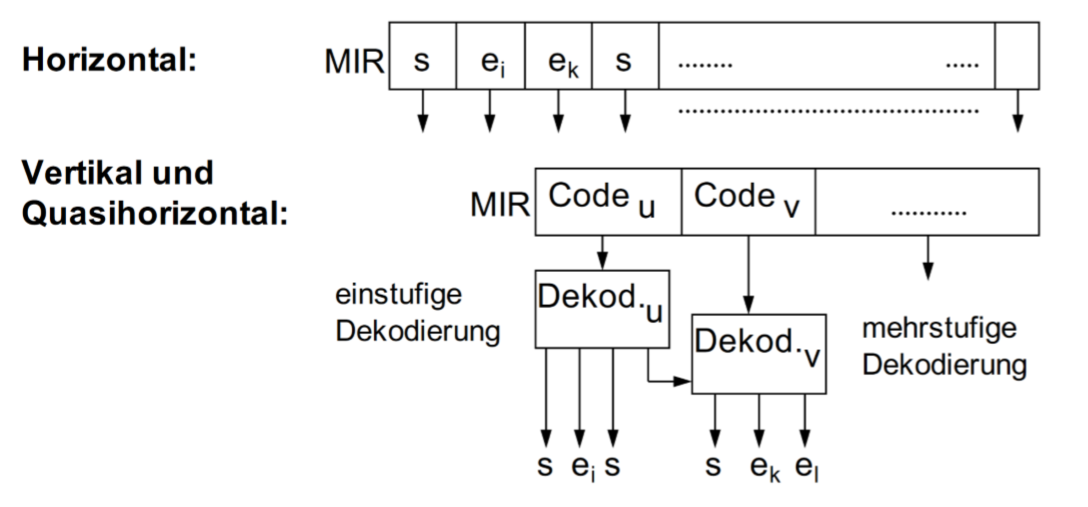
其他形式的图:
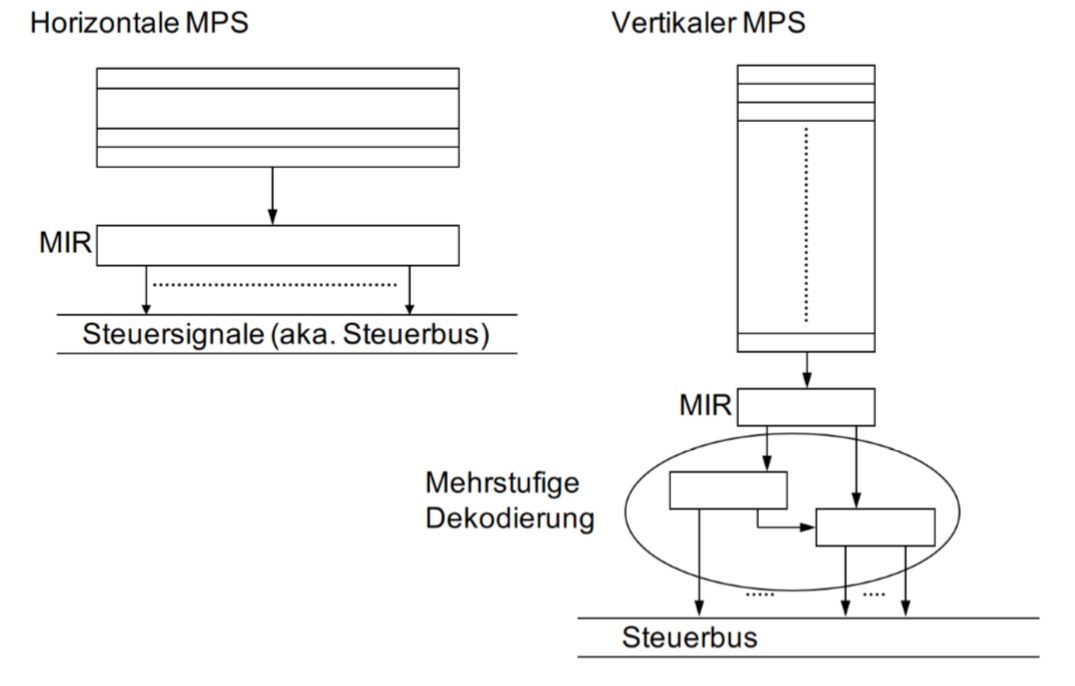
Mikroprogrammspeicher(MPS)
微程序被作为微代码(Mikrocode)放在微程序存储器中。在我们的例子里,它在Leitwerk中。
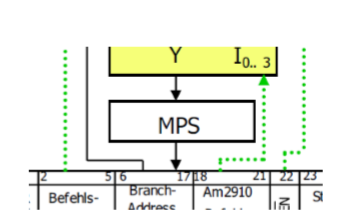
为了微指令可以被调用,需要可访问(adressierbar)的MPS。它只有相对少的地址,但空间却很宽(这里是80Bit)。它有不同的实现方式:
- ROM(Read-Only Memory) 固定的程序
- PROM(Programmable Read-Only Memory)可以重写写入的ROM
- RAM(Random Access Memory) 在程序开始的时候重新写入
- Hybirdoptionen 这里放着ROM的基础程序,开始的时候会被复制入RAM
Mikroinstruktionswort
之前提到过微指令的字宽是80Bit。它对应了MPS的一行。Bit数组的每个元素是对架构中的每个元素的直接控制信号。

- Bit 0 是控制 Hauptspeicher
- Bit 1 是控制Instruktionsregister的读取
- Bit 2 - 5 是控制ISA中Befehlszähler的输出和增加
- Bit 6-17 和 Bit 58-73 是Leit 和Steuerwerk的常数
- Bit 18-21 和 Bit 49-57 是对AM2910(Leitwerk)和AM2901(Rechenwerk)的指令控制,他们含有编码过的指令
- Bit 22 和 Bit 37-48 是Datenpfaden的控制
- Bit 23-36 是AM2904(Steuerwerk)的信号控制
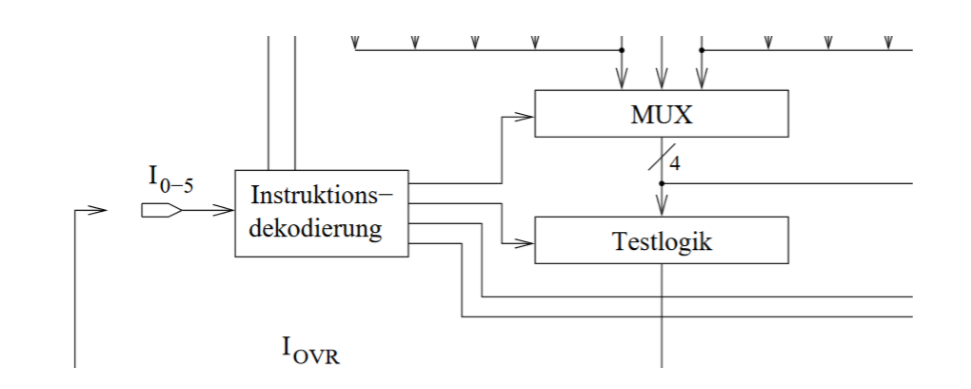
12.4 Mikroleitwerk
下图是Mikroleitwerk的位置
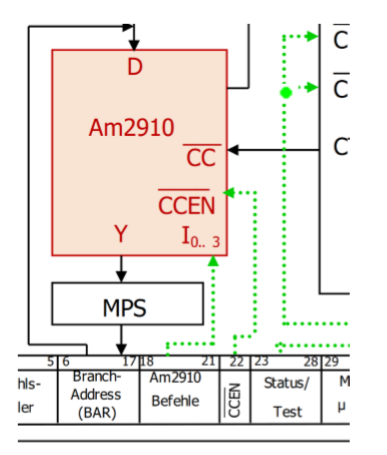
Mikroleitwerk的任务是拿出下一条微指令。微指令计数器(Mikrobefehlszähler)会计算出下一个值。它会放在Mikroinstruktionsregister里。下一条指令的选择和控制语句Steuerungsbefehl和控制信号Steuersignalen(条件)有关。控制信号放在MIR的Bit 18-21 里因为有4Bit的空间,可以放16种指令。它决定了下一条指令在哪
12.4.1 Mikroprogrammierung 的想法
微编程实现了ISA中的每个单个指令。每个ISA指令都有一个编码(Opcode),它把指令的功能和操作数都编码进去了。那么这个Opcode就必须导致Mikroprogramm的运行。那么就存在一个在宏编程(Makroprogrammierung)和微编程(Mikroprogrammierung)之间的接口。宏编码(Makro Opcode)接管了Leitwerk的控制。为了知道这个编码在哪,需要宏指令寄存器(Makro Instruktionsregister)。它也是微编程的一部分
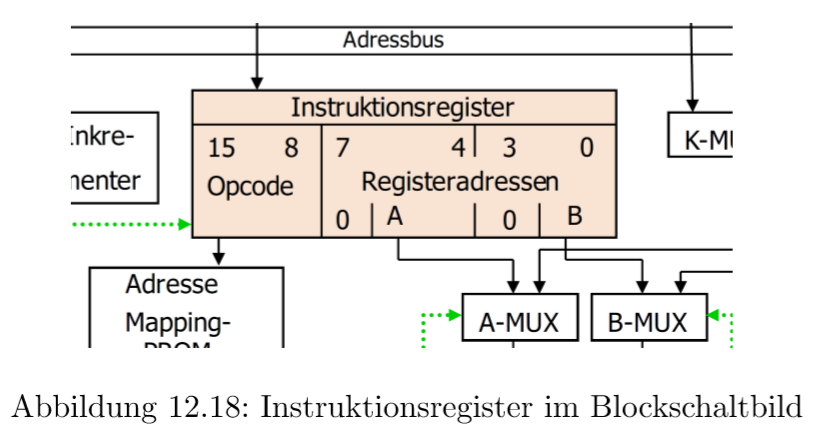
通过这个接口,微架构就确定了ISA,然而只是基本指令格式,却和ISA有紧密联系。在我们的例子中只用了8Bit的指令,当然有更长的可能性。
12.4.2 Makro-Mikro Opcode Abbildungsspeicher(宏编码和微编码映射存储器)
每个ISA指令表达了一个微程序。当然,可能有不止一条指令。所以1对1的映射是没有意义的。映射存储器把一个ISA Opcode 映射到微程序地址上。它由此定义了每个ISA指令,所以映射存储器是ISA的中心定义。
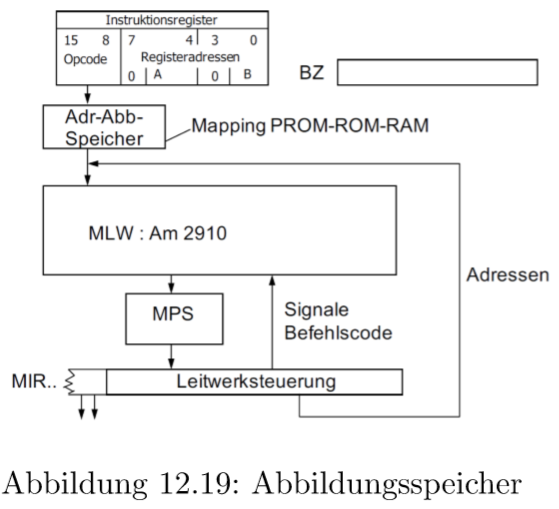
我们可以这样想象这个过程。首先在Instruktionsregister里有个ISA指令。它的Opcode传入映射存储器,传出一个地址,然后传入Leitwerk。于是我们就可以读取下一条微指令。更准确的,JAMP指令是管理这个映射的。

12.4.3 Mikroleitwerk的结构
先上总图
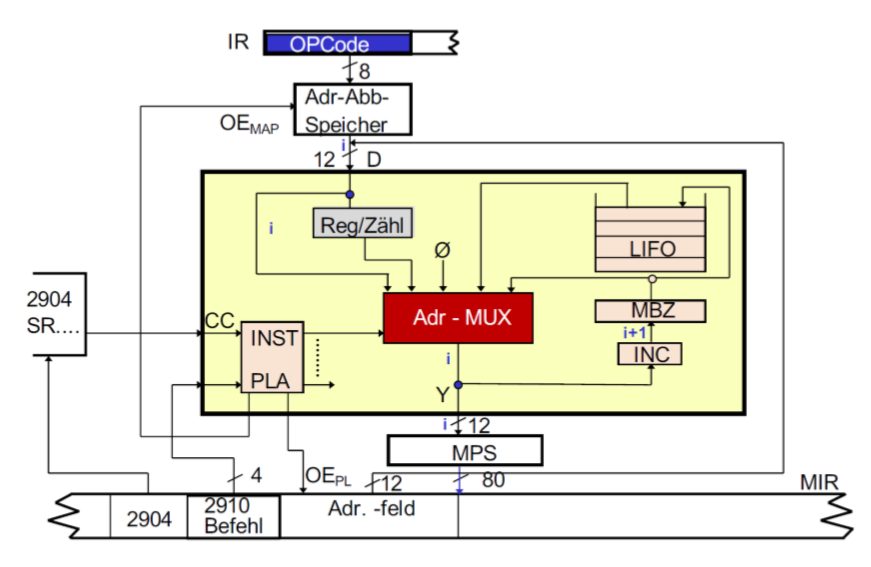
栈
LIFO栈是一个专门放Mikrobefehlszähler的栈。它实现了内部子程序的调用。它与普通栈有些区别:
- 固定深度(5)
- 没有参数
- 没有局部变量
它导致了不能使用广义的子程序。
Addressen Multiplexer
它的任务是找出下一个微指令的地址。它被INST PLA控制(Instruktion Programmable Logic Array)。地址有5个来源:
- 空常数 Null Konstante ,它跳转到MPS的开始位置
- 外部地址 Externe Adresse 它可能是映射存储器传出的ISA Opcode的地址,还可能是MIR的常数
- 微指令计数器的地址+1
- 计数器寄存器 (不相关)
- 上层栈元素 (调用子程序)
INST PLA
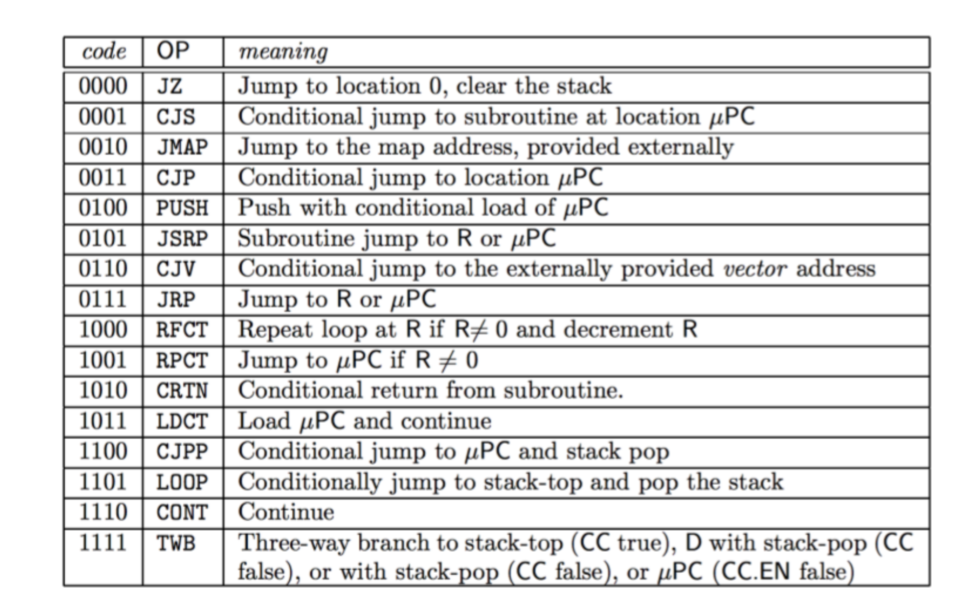
它是一个Schaltnetz,它定义了Leitwerk的功能。它的输入由4 Bit的从MIR来的指令和一个Flag(CCEN Conditon Code Enable),它决定条件比特位JKonditionsbit(CC Conditon Code)是否被阅读,构成。它的输出是对Multiplexer,栈或者计数器的控制信号。当然外部控制信号是可能的。下表是PLA的指令表。
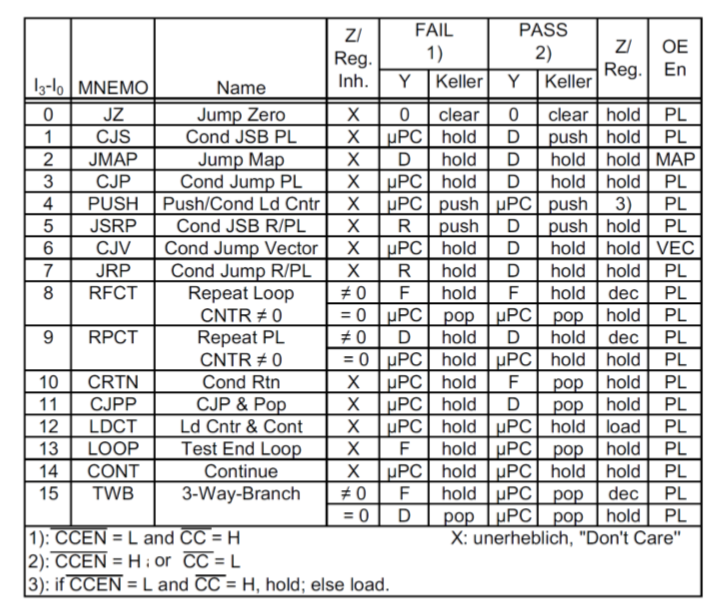
有些指令我们深入讨论。
12.4.4 PLA中重要指令的实现
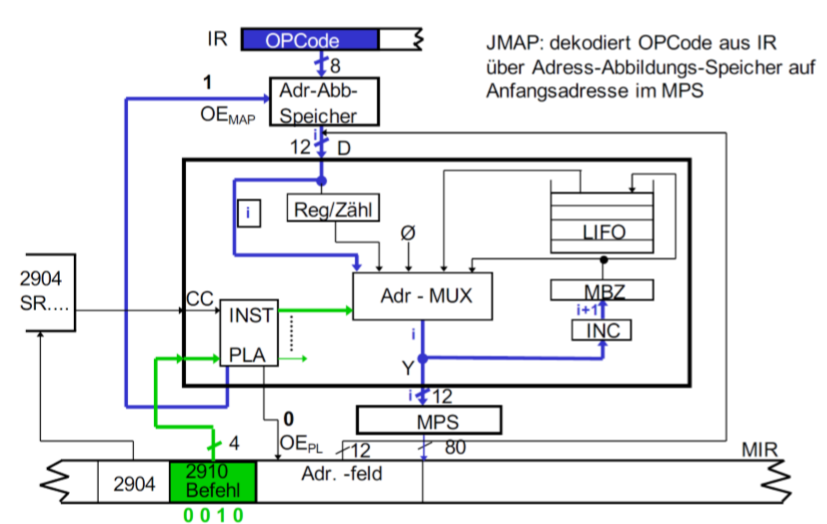
JAMP

它从MIR中出来,加载到PLA上(绿线),它决定了从映射存储器中来的指令。从IR里来的Opcode通过映射存储器的解码,再经过地址选择器Adr- MUX放在MPS的开始地址上。同时微指令计数器MBZ会增加(蓝线)
CONT(Continue)
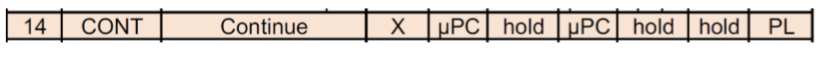
它会把MBZ+1,最终也就是+2
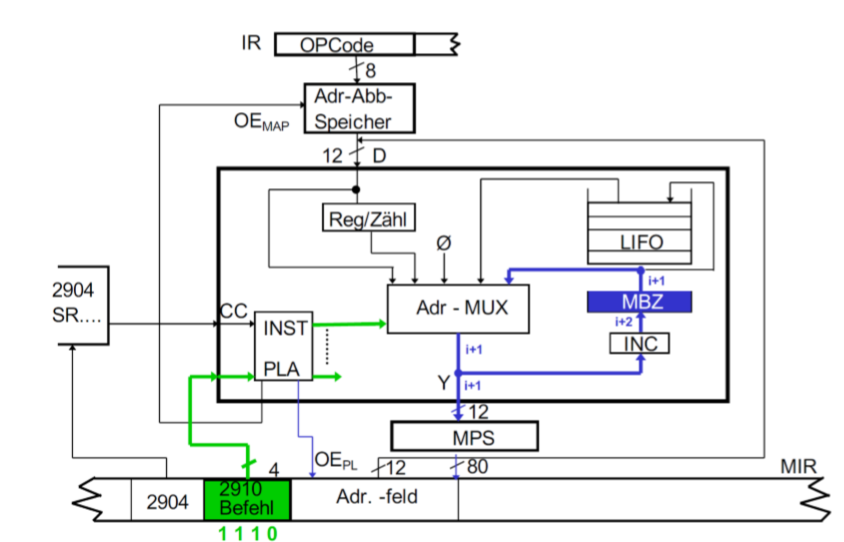
JZ(Jump Zero)
它跳转到地址0处,并把栈删除。
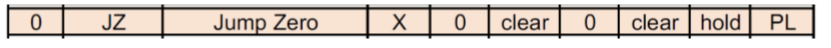
我们可以这样想象,它从MIR出来到PLA里。传入MUX的值是NULL,然后从MUX里出来的值会变成0。以至于到MPS里的地址也会是0。
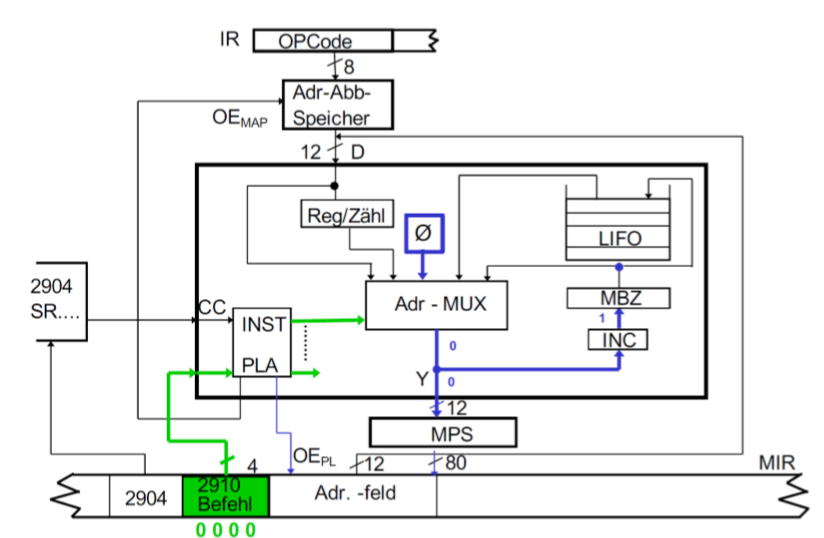
CJP(Conditional Jump)
它会跳转到一个地址,如果再CC里的条件成立。
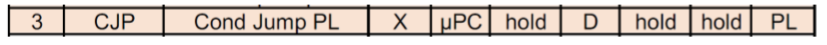
它从MIR中读取指令到PLA。如果CC=1(失败),那么值从MBZ里来,相当于CONT。如果CC=0,那么还有个决定。它取决于OE En的值。如果它是“PL”,那么下个值从MIR的地址区域来。如果是“MAP”那么从映射存储器里来。最终加载到MUX再到MPS。
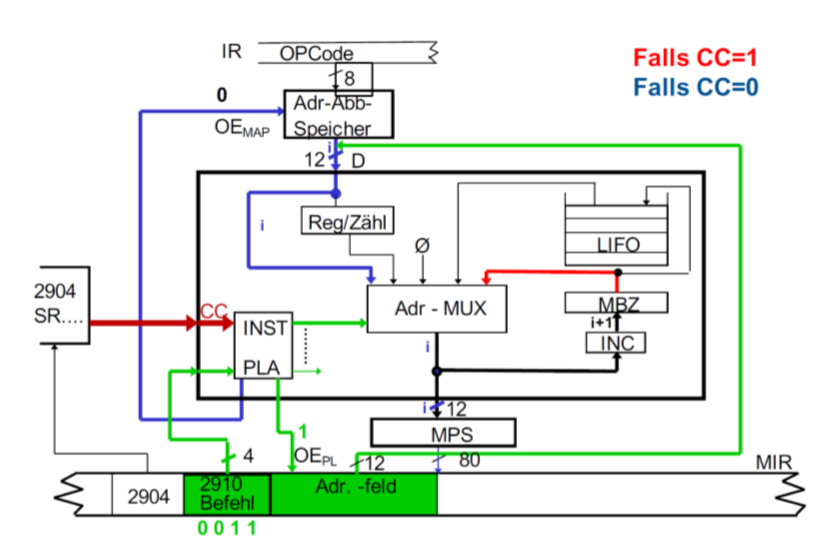
CJS
它根据条件调用子程序

如果CC=1,那么CONT。如果CC=0,把下一个地址存再LIFO栈里。然后看OE En。如果是“PL”,读取MIR的地址区域的值。如果是“MAP”,读取映射存储器的值。
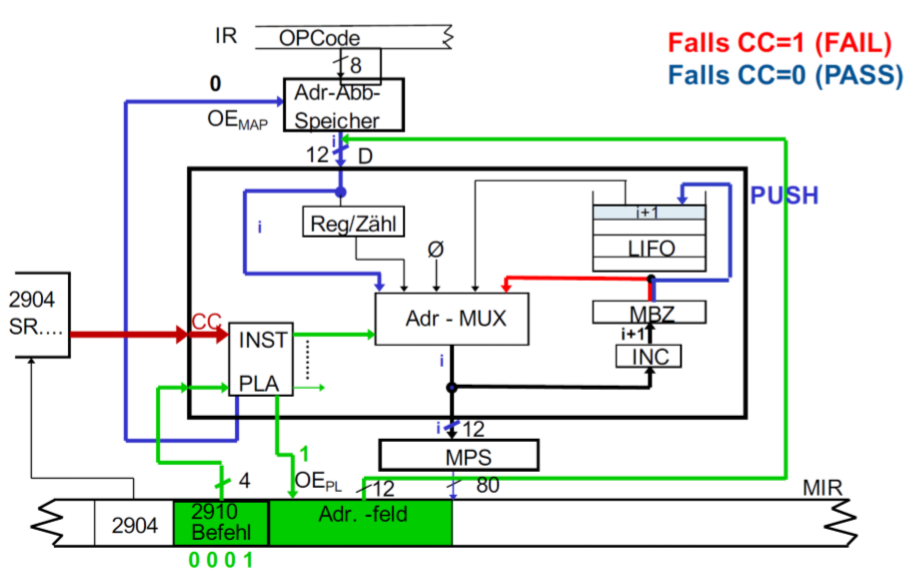
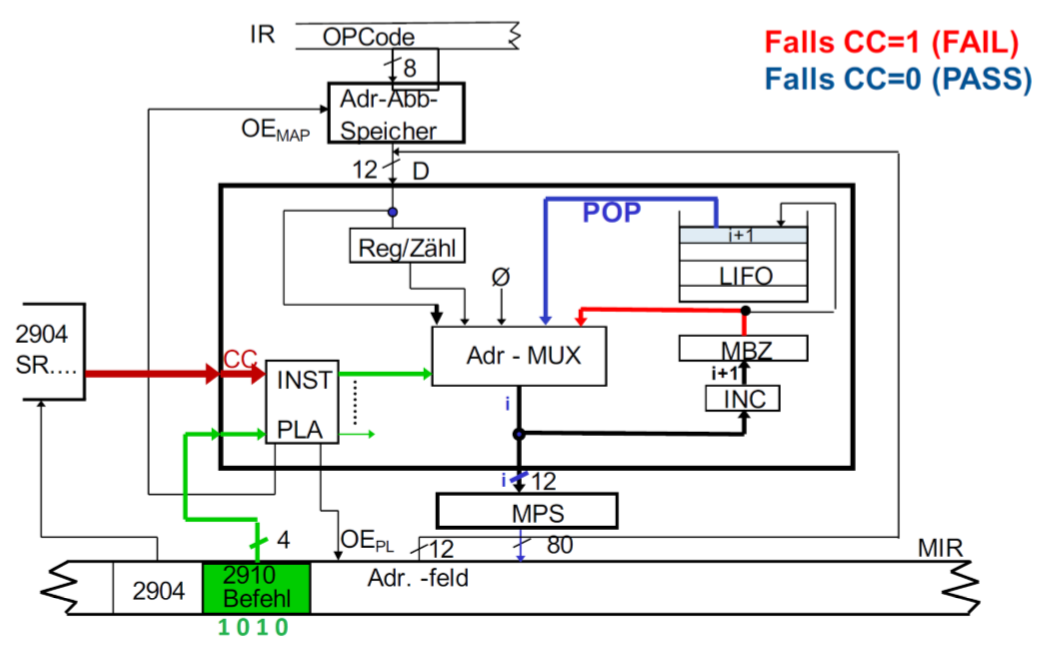
CRTN(Conditional return from subroutine)
根据条件从子程序返回。

如果CC(Condition Code - Flag)=1,那么CONT。如果CC=0, 那么读取LIFO栈的最后一个值(POP),然后通过MUX加载到MPS里。
12.4.5 Leitwerk的实现
我们由一个5个输入源的地址选择器(Adressen Multiplexer),还有个INST PLA,它告诉MUX地址从哪里来。
- PLA是Schaltnetz,通常由一个列表实现
- 输入时2910指令(CC从2904来),输出时一个MUX控制信号,OE Enable 和一个栈控制
此外还有Schaltwerke给寄存器(MBZ,栈,栈指针)和栈控制
12.4.6 Makro/ISA 指令读取
读取ISA指令用到JAMP指令,它通过从IR读取的Opcode的选择调用了一个子程序。那么有个问题:下一条指令怎么被加载?为了实现它,宏指令计数器(Makro Befehlszähler)会放在地址总线上。地址总线包含下一条指令的地址,它是从数据总线的存储器中被读取的。为了实现它,存储器必须允许”读取“操作。最后,IR才能从地址总线读取值。
12.4.7 存储器和指令计数器控制
为了把正确的值放在地址总线上,指令计数器必须自增。也即是说,我们必须控制BZ和Speicher。为此工作的是MIR的Bit 0-5。
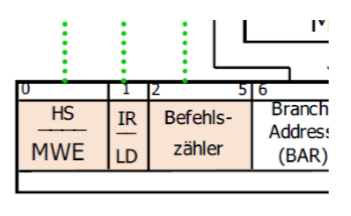
这些Bit控制宏指令计数器,IR和存储器
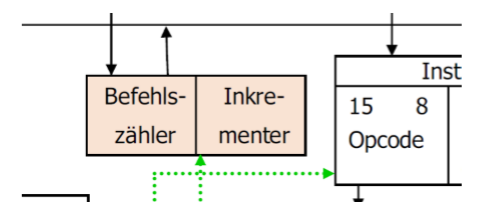
存取信号(Zugriffssignale)(存储器和BZ)
MIR的前6Bit是给存储器和Makro BZ的存取信号。具体值在下表
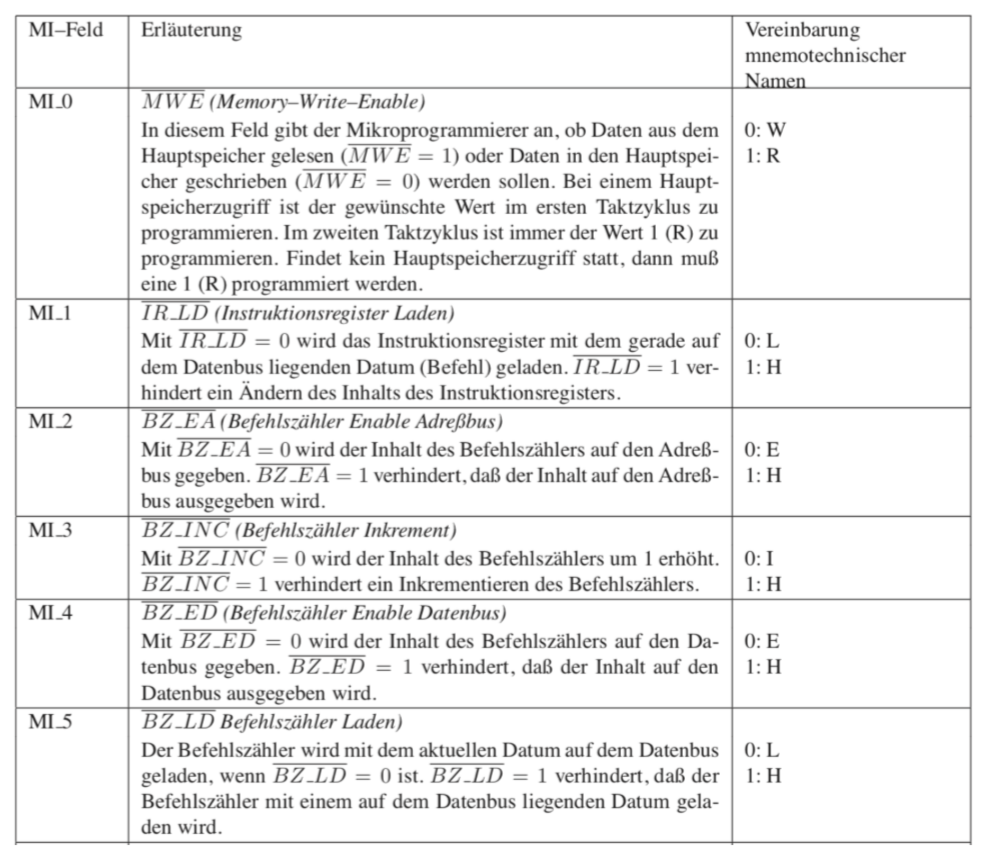
IFETCH
读取下个指令的具体流程是IFETCH规定的。它是一个特定的微程序,它一直在地址0处。这个指令包含了3个地址
- 地址0:读取主存储器(Hauptspeicher)(MWE = R),BZ会被加载到地址总线上(BZ_EA = E), 执行CONT
- 地址1:读取数据总线的值(IR_LD = L),执行CONT
- 地址2:执行JAMP
在每个地址最后“无其他影响”会被设置。每个子程序执行它的指令,并且之后跳回地址0
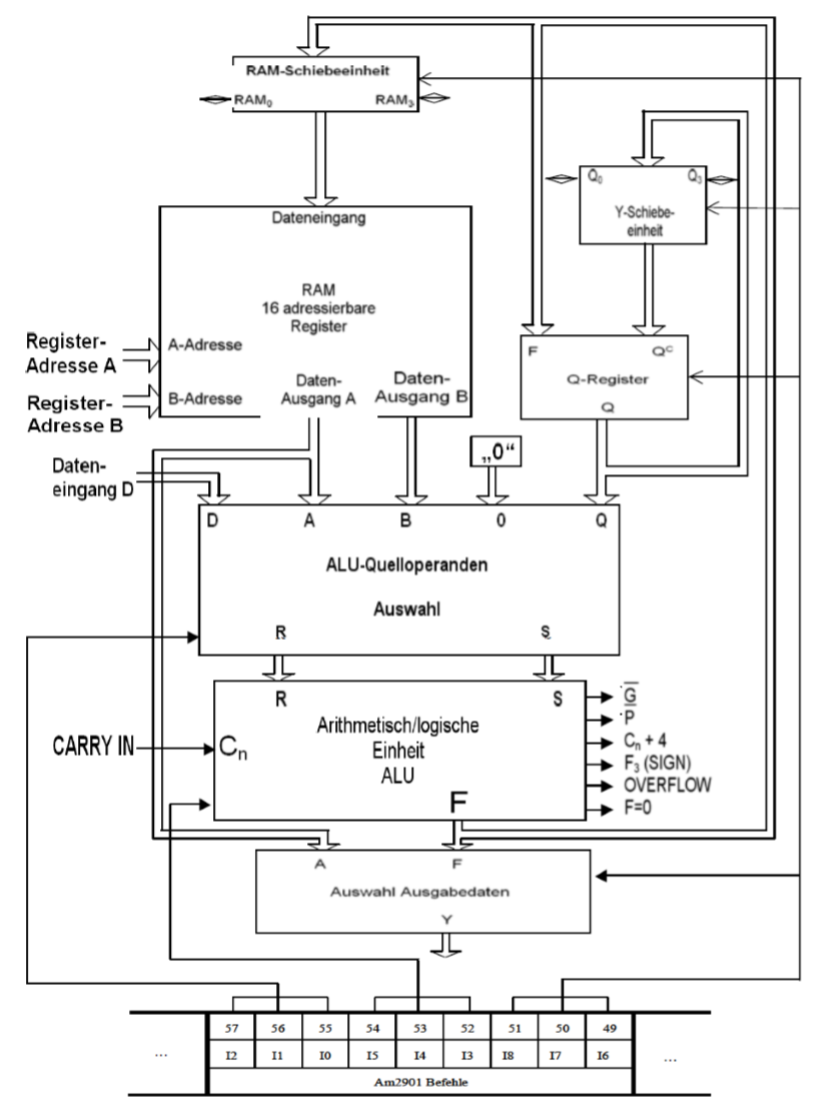
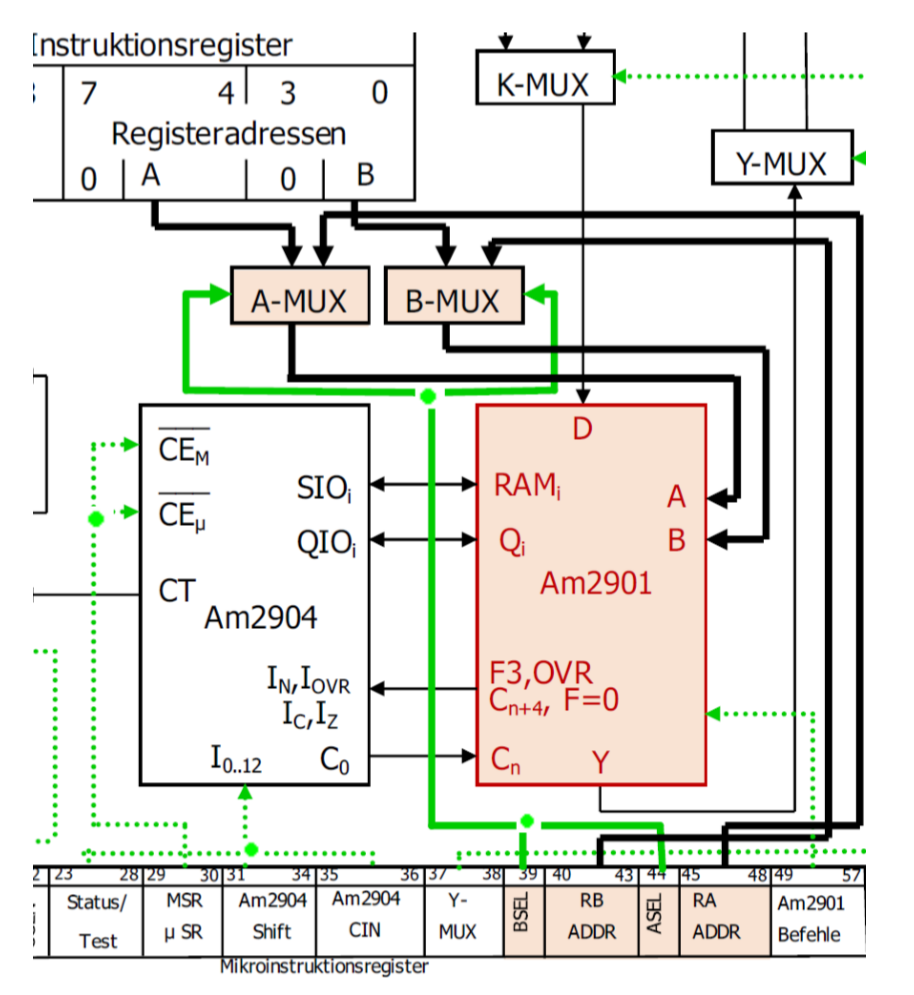
12.5 Mikrorechenwerk(微计算单元)
微计算单元的任务是代数和逻辑运算。下面是微计算单元的位置:
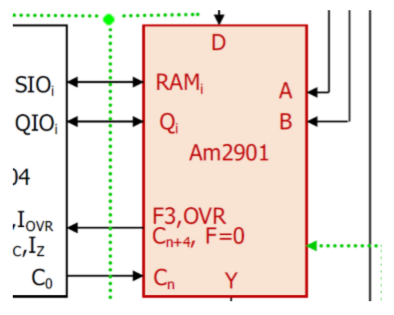
Am2901在我们的例子里是一个4Bit的计算单元。由一下部件组成:
- 位移单位(Schiebeeinheiten)
- 16个寄存器
- 8个指令(3 Bit 编码)
- +/- 和逻辑操作
这种单个的计算单元可以继承成任意位宽的计算单元。下面是4个计算单元的集成,每次会把溢出传递过去。
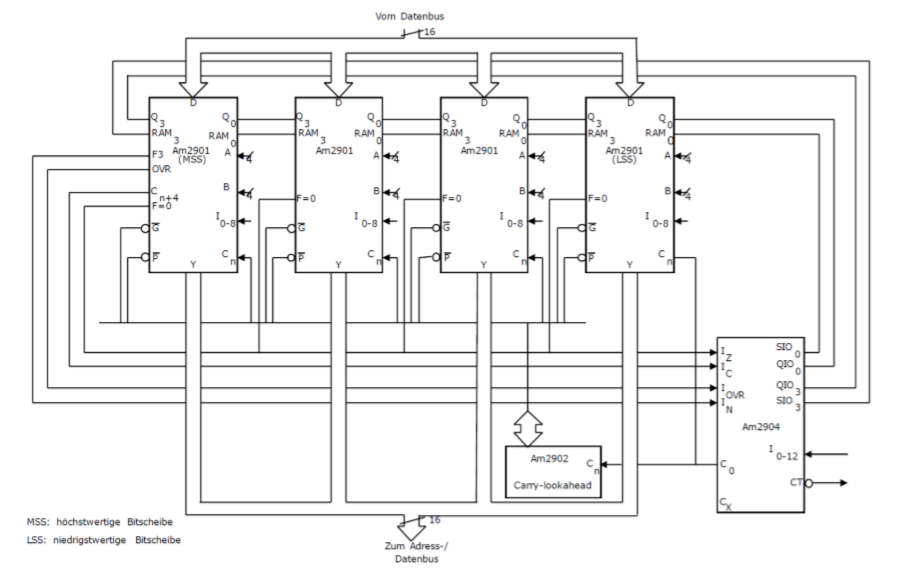
为了仔细介绍其中的原件,我们将使用下图:
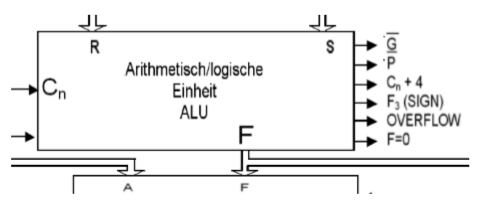
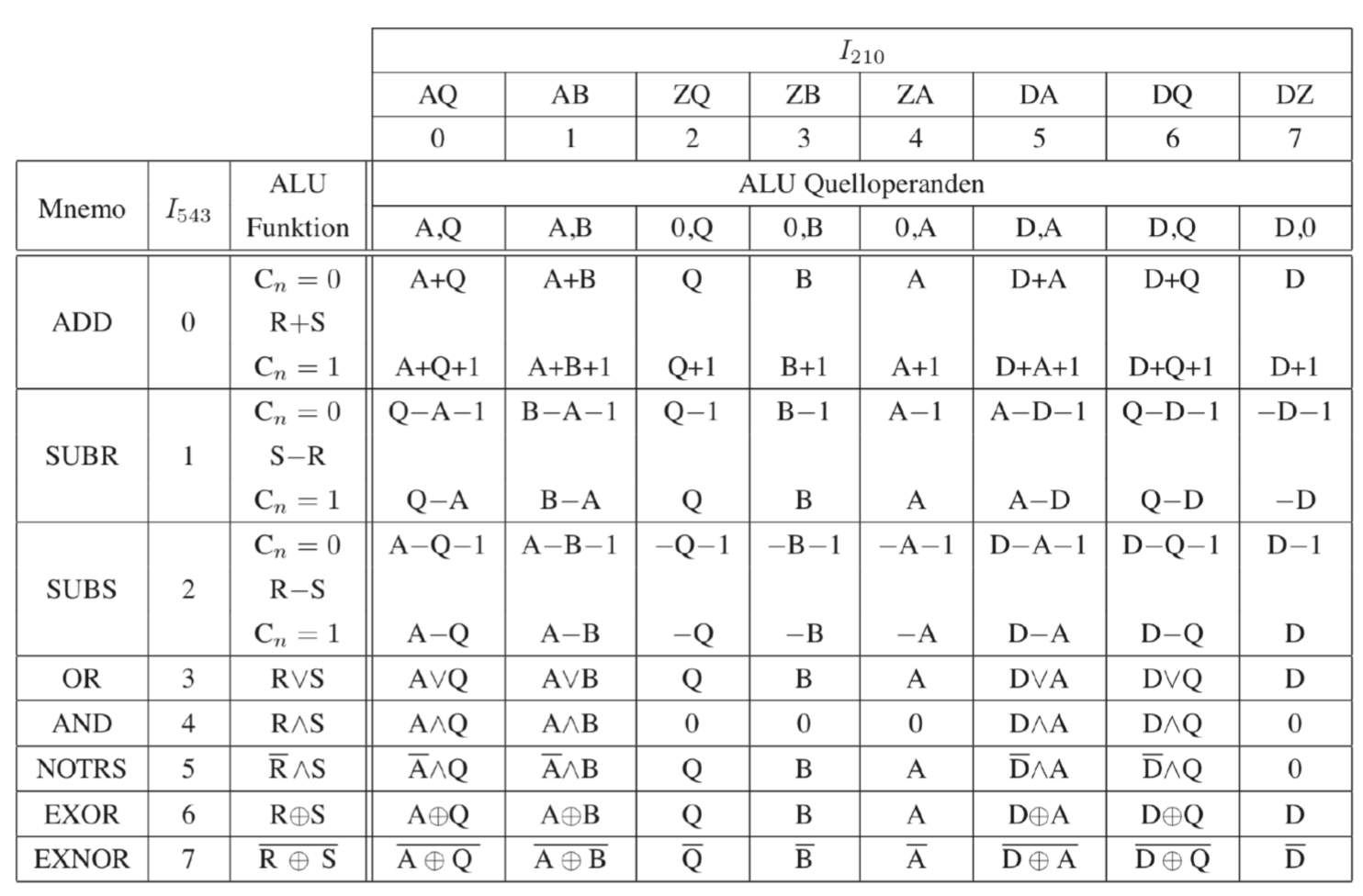
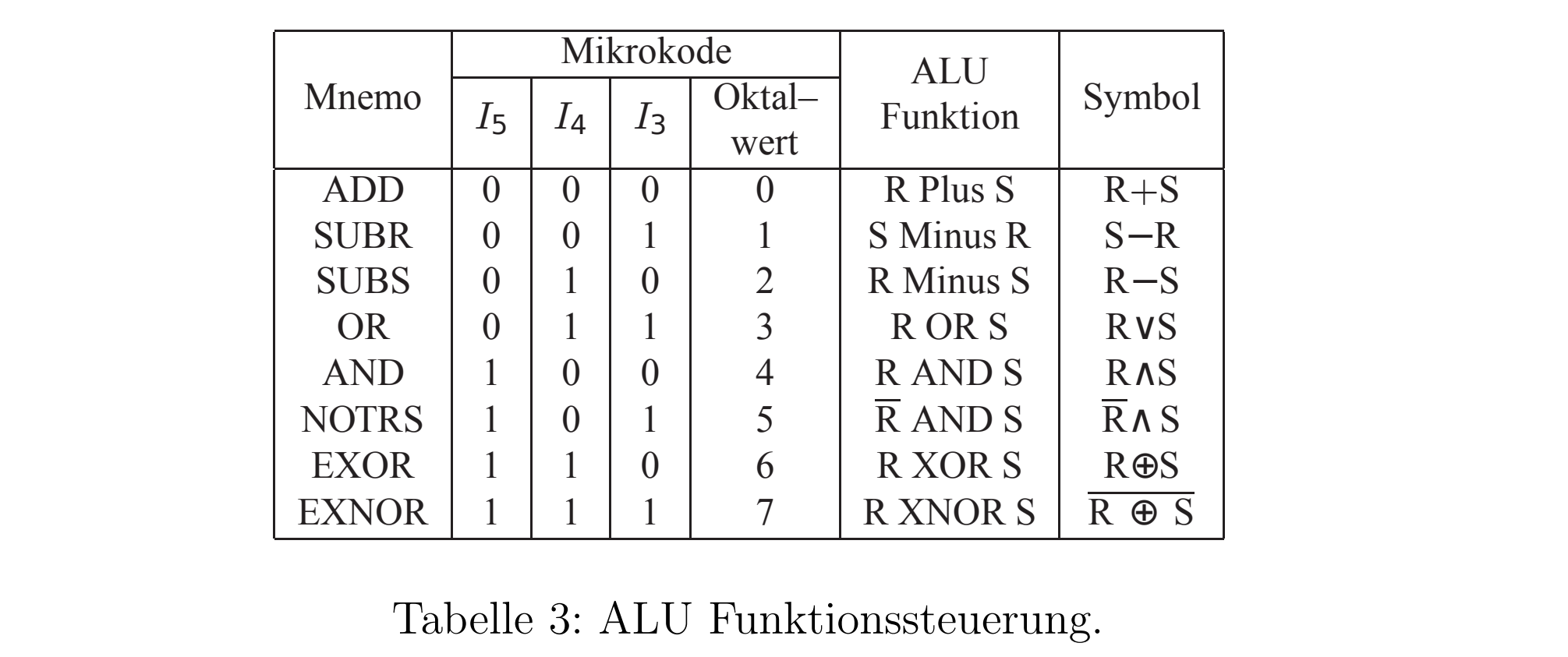
12.5.1 计算单元的ALU
下面我们介绍Arithmetic Logic Unit(ALU)或者叫计算单元。它负责自己的计算。共有8个指令可用。他们通过3Bit可以在微指令被控制。ALU有2个入口(R,S),1个出口(F),还有很多控制信号:IN(Carry), OUT(Carry, Zero, Overflow)。
之前提到有8个指令。下面是他的表格。
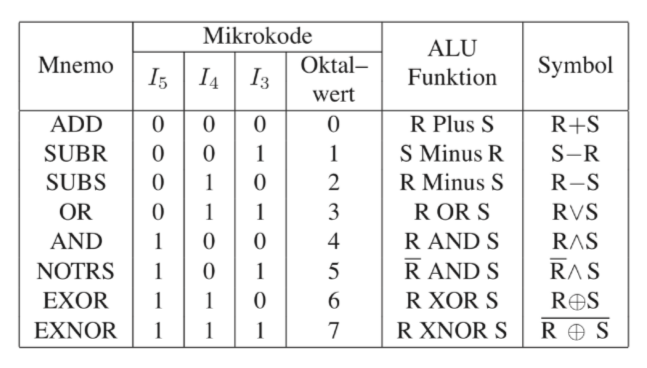
可以看到,只有简单的运算才有指令。由此才可能通过简单少量的逻辑去实现。为了计算更复杂的程序,需要写一个微程序。
12.5.2 计算单元的数据连接
计算单元(Rechenwerk)有一个外部的出口(Y)和入口(D)
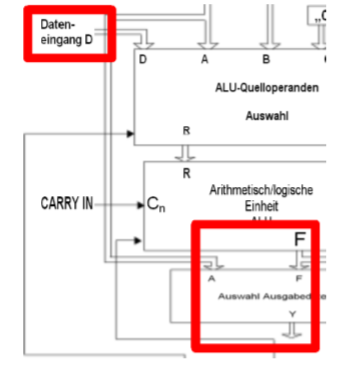
- 外部的出口可以是在数据总线,或者在地址总线
- 通过出口可以实现操作数和结果的互相传递
- 外部出口是DRAM(Datenbus)输入的接口,或者常数。
- 无论是入口还是出口,数据的来源和去处都是通过MIR的控制信号控制
从下图可以推断出,数据在计算单元是怎么传递的
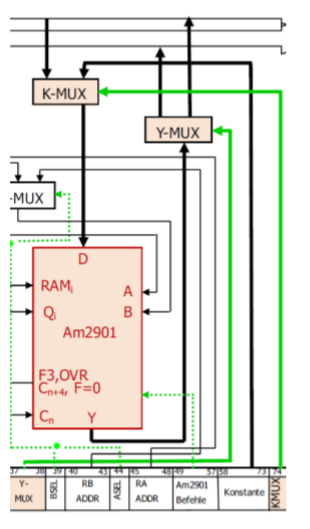
12.5.3 计算单元的寄存器
寄存器的位置在2门寄存器单元(Zwei-Tor Registerwerk)。那里有16个4 Bit的寄存器。并且有1个入口和2个出口。它使得每个时间脉冲可以有2个读取过程
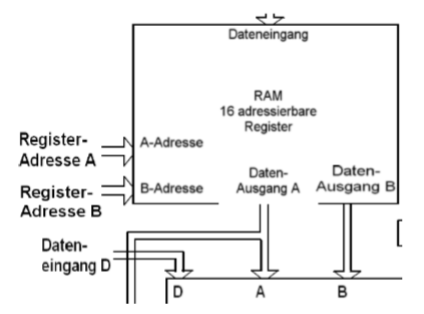
使用的寄存器有2种
- 通过Mikro IR :4 Bit 在MIR里
- 通过Makro IR:3 Bit 在IR里(最高Bit一直0),也就是在ISA里只有8个寄存器可见
在MIR里有2个区域(ASEL,BSEL),它们决定了给A/B 入口的值从Makro IR 还是从 Mikro IR里来。A-MUX/B-MUX把对应的寄存器地址传递到计算单元。
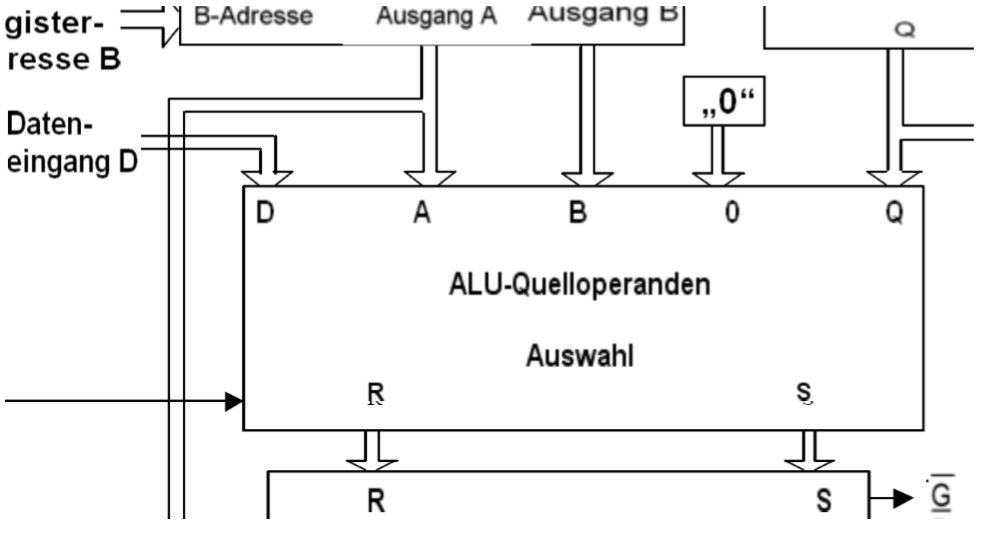
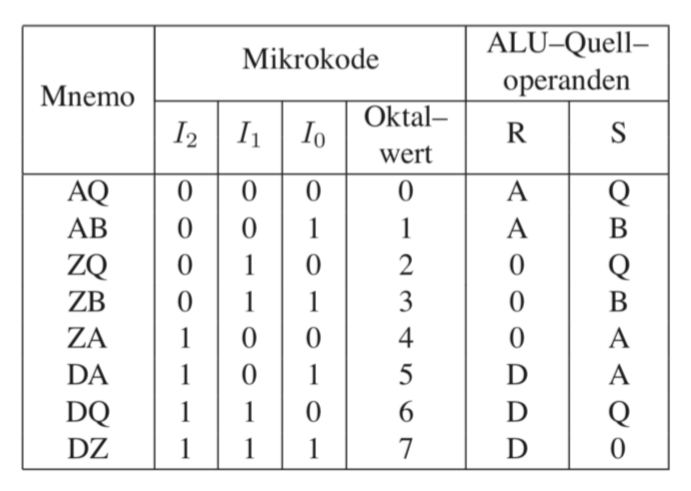
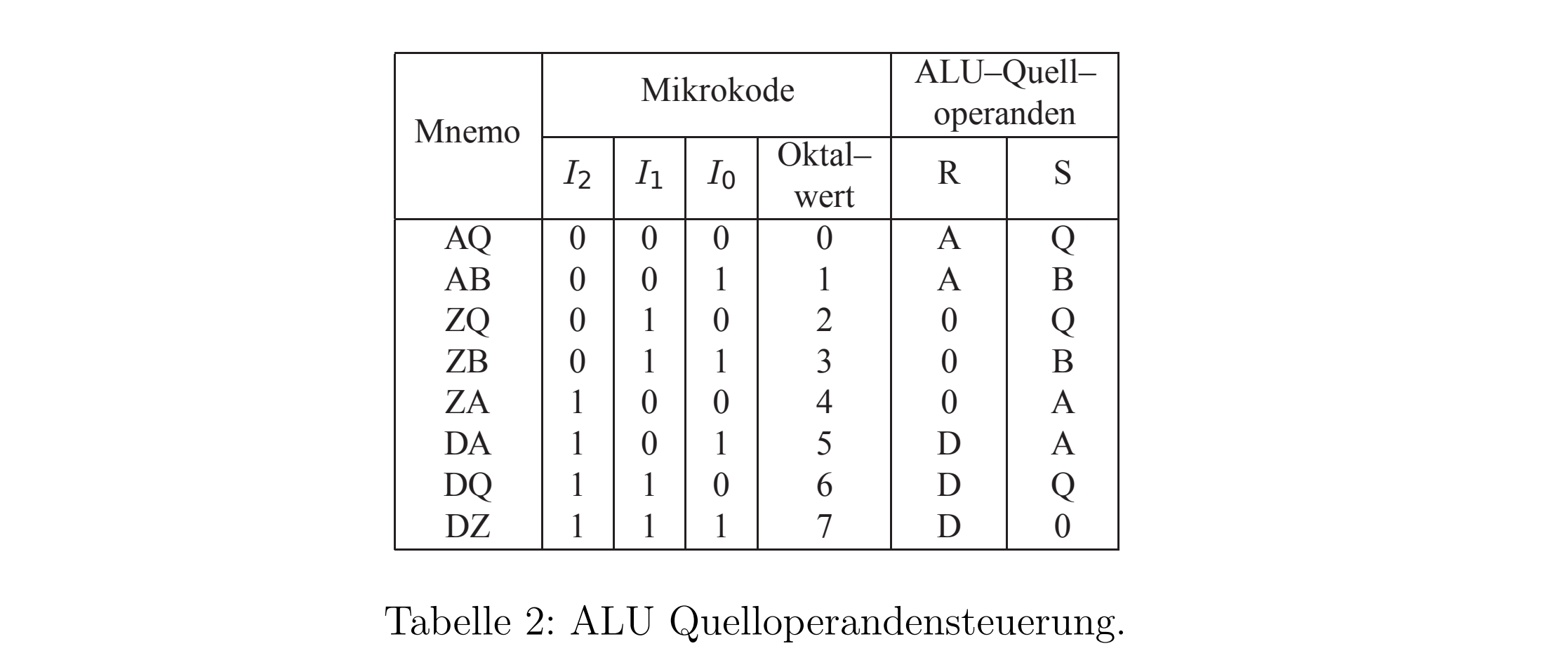
12.5.4 ALU 操作数(Operanden)
ALU的操作数源的选择是通过一个MUX的,它通过3 Bit(8个可能的控制)微指令控制的。MUX有5个源
- 外部数据入口
- A 寄存器出口
- B 寄存器出口
- Null
- Q 寄存器 (位移结果,或者一个先前的ALU结果)
除此之外ALU操作数的MUX有2个出口(R/S),它走入ALU。
12.5.5 操作数选择Operandenauswahl
在微指令中可以给选择给ALU的操作数,但没有所以的可能性,原因是为了避免不需要的复杂度。见下表。
将ALU的操作数和从MUX里来的操作数结合,我们得到了下面的操作集合:
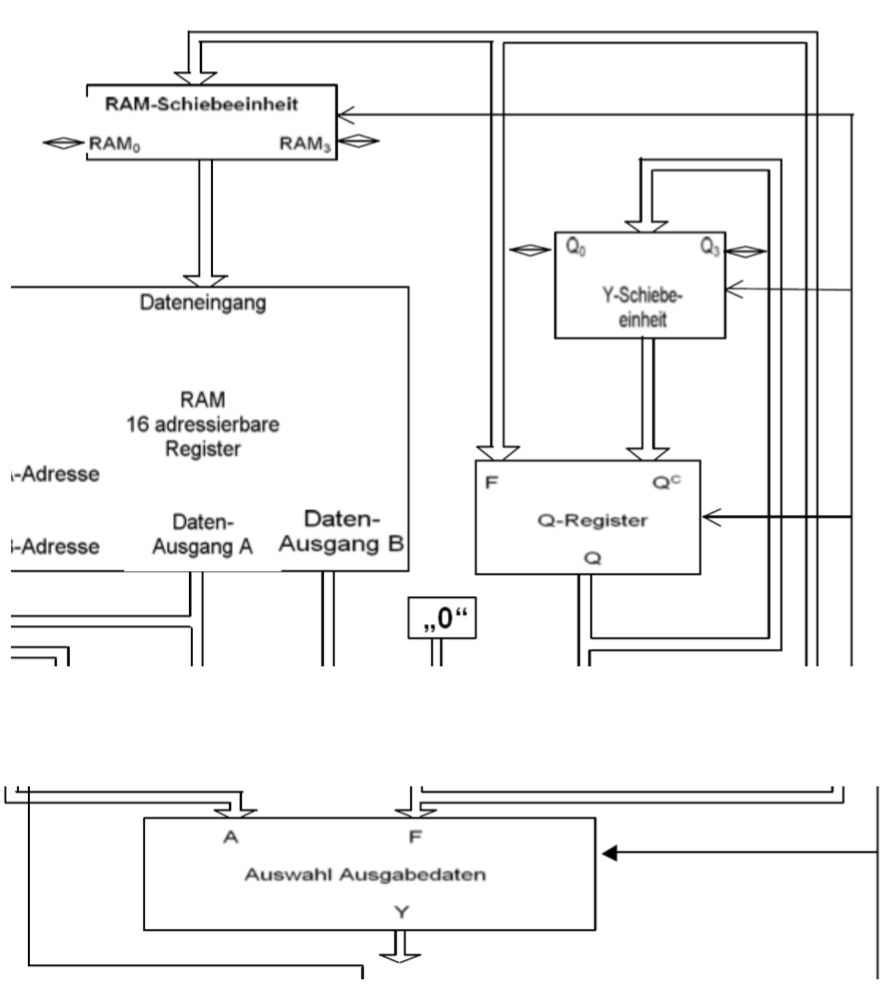
12.5.6 位移单位(Schiebeeinheiten)
位移单位是用作数据的预处理和后处理。它也是3Bit指令控制的。控制位移单位的信息也控制从A/F到Y的映射。也就是说,它给出了是A还是F应该映射到Y。F的回循环(Loopback)到寄存器B也会被它控制。
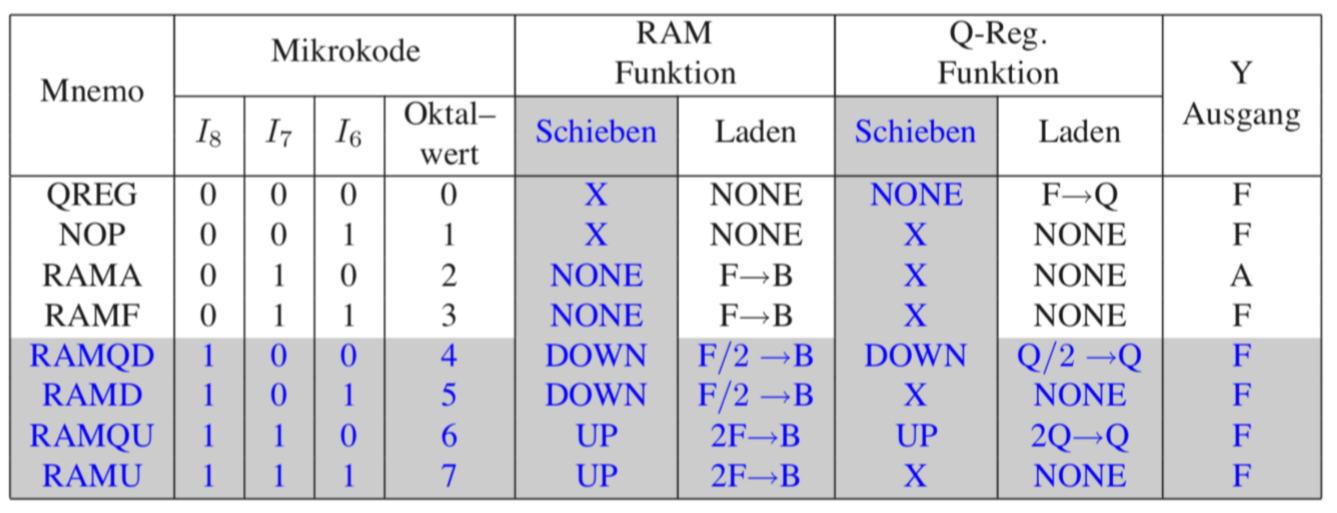
12.5.7 位移和选择指令
这些指令决定,F的值映射到寄存器B还是Q里。此外它还决定Y,F或者A被写入。信号控制会从位移指令解码。(表格灰色部分对考试不作要求)
12.5.8 计算单元的实现
计算单元可以被许多步骤实现:
- ALU可以作为Schaltnetz被实现
- ALU操作数选择可以用一个大的MUX作为Schaltnetz实现
- 寄存器是Schaltwerke
- 选择和数据线路:用门(Tore)和MUX
- 位移单元是Schaltnetze,并且附带寄存器和Schaltwerke
12.5.9 多个片段的组合
一个片段是计算单元,多个计算单元可以相互连接。组合的结果是:每4 Bit有一个自己的状态Bit(Statusbit)。它们会连接起来:
- Zero Flag:所有片段Null
- Carry Flag:必须传递
- 从高位计算片段来的负Bit
这些组合必须接到Leitwerk里。还有一个结果是会在层之间有旋转指令(Rotierbefehlen)。这些必须通过所有的片段。如果我们想要带上Carry旋转,那么最后一位Carry Bit必须要包含再里面。RAM和计算单元的寄存器Q会需要这些命令。
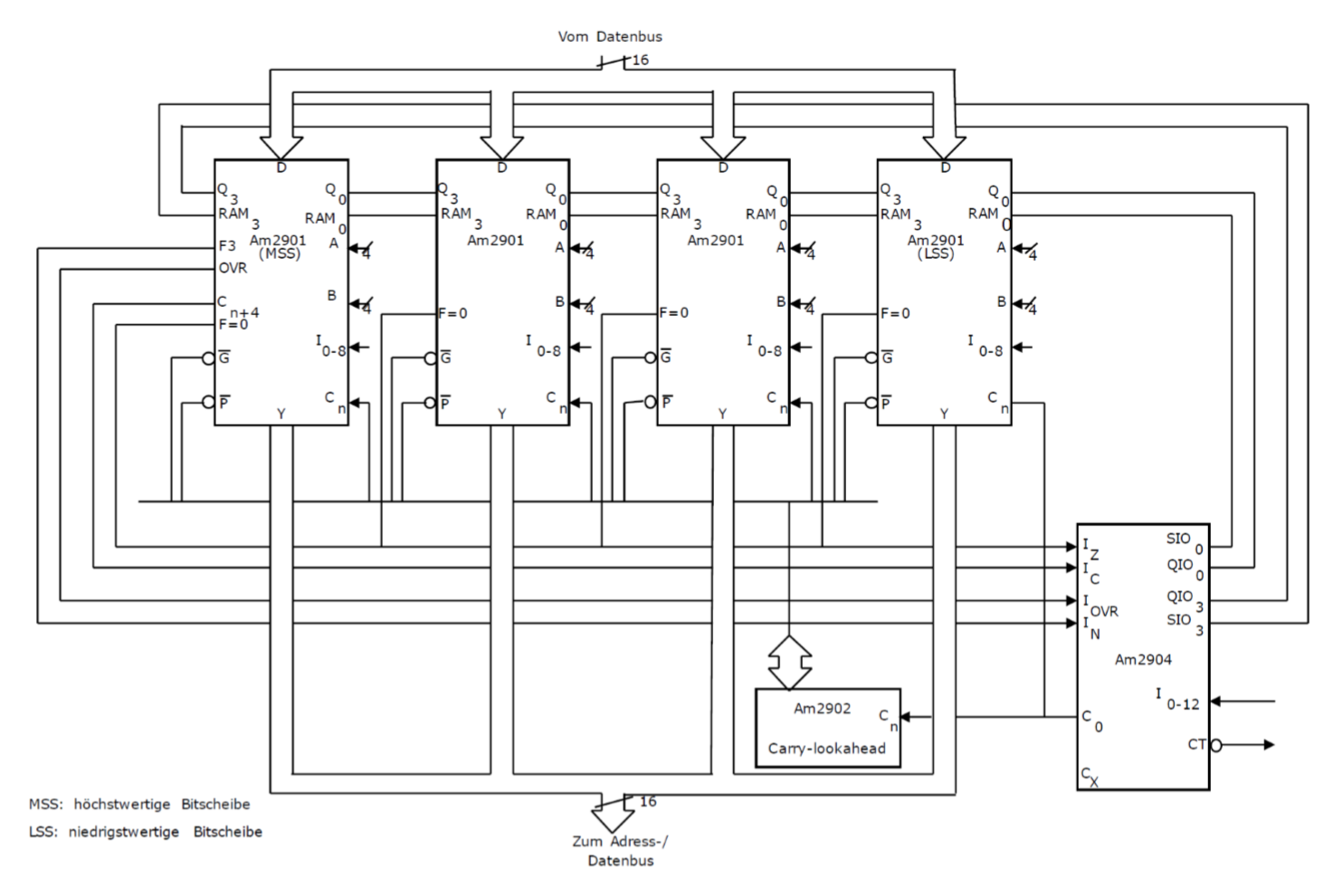
12.6 Wortrandlogikbaustein
也叫(Am2904)它是必需品,当我们连接多个组件的时候。
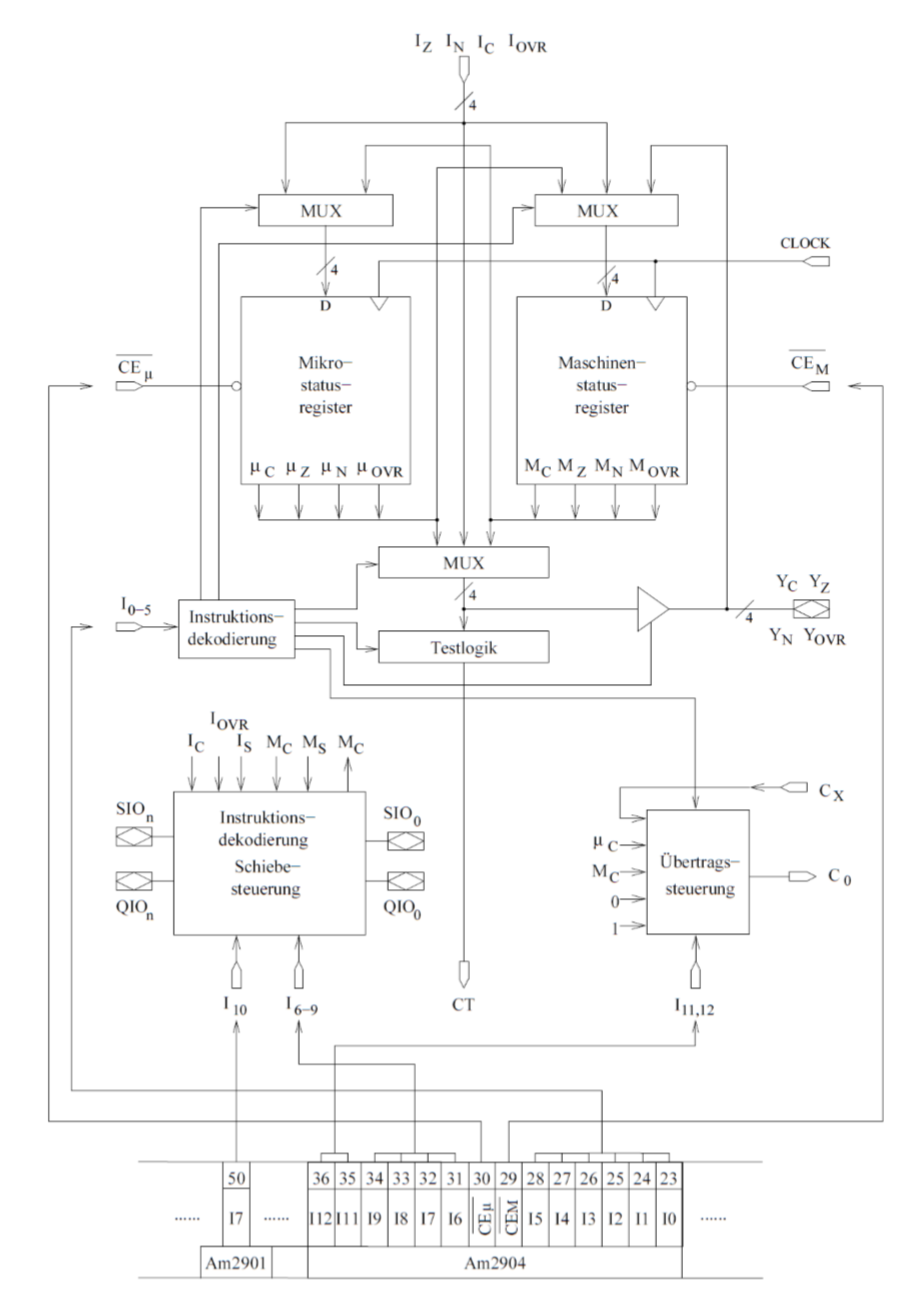
最重要的元件是两个状态寄存器(Statusregister)
- 机器状态寄存器(Maschinenstatusregister)(MSR) :ISA编程者可见
- 微状态寄存器(Mikrostatusregister)(\(\mu SR\)):ISA编程者不可见
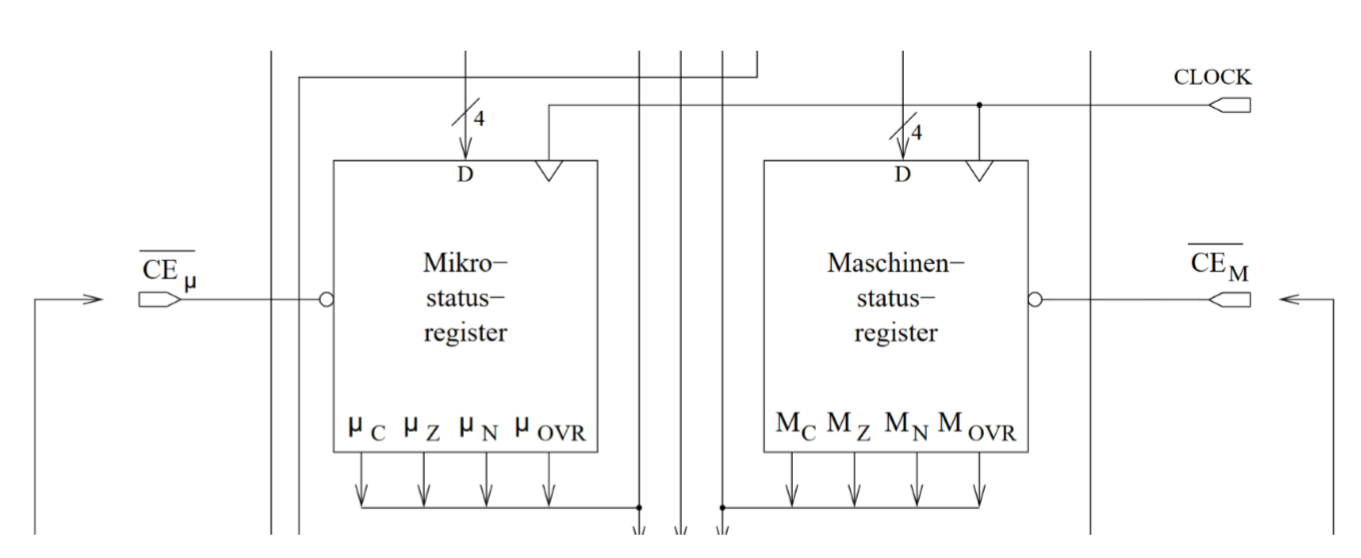
它们是独立被控制的并且按Bit位加载来自计算单元的状态信号(Statussignalen)。可能的状态信号如下:
- 溢出(Überlauf)(OVR)
- 多余部分(Übertrag)(C)
- 符号(Vorzeichen)(N)
- 空记号(Null-Anzeige)(Z)
状态信号通过4个状态入口(Statuseingang) \(I_{C},I_{N},I_{Z}\)和\(I_{OVR}\)被加载
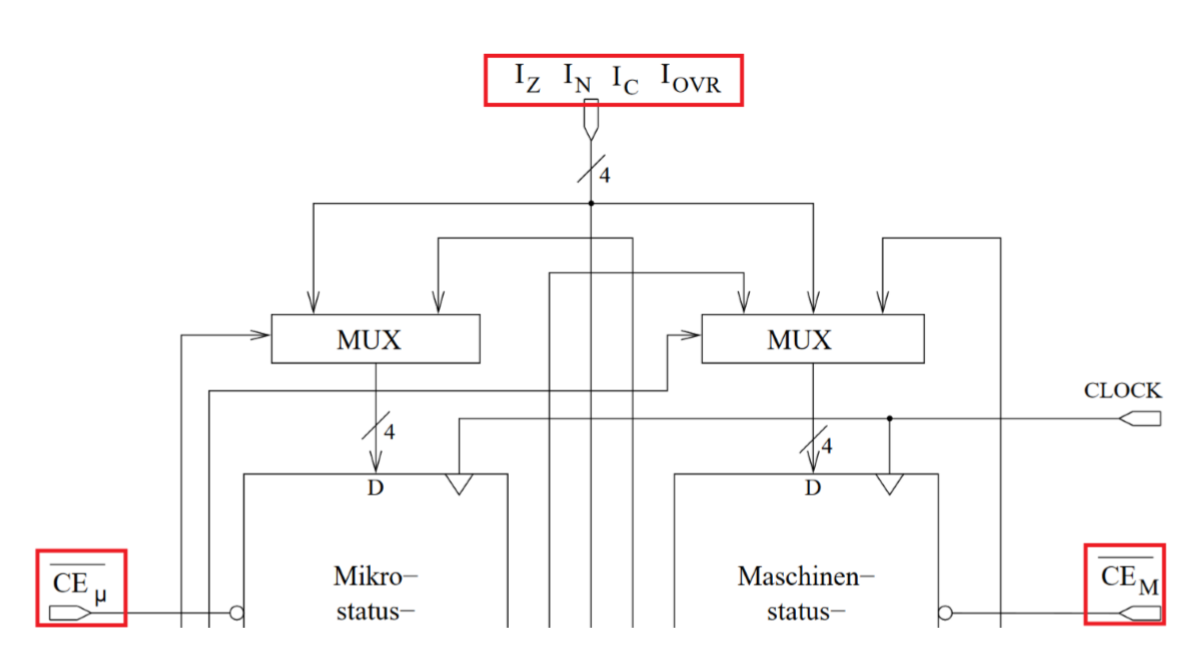
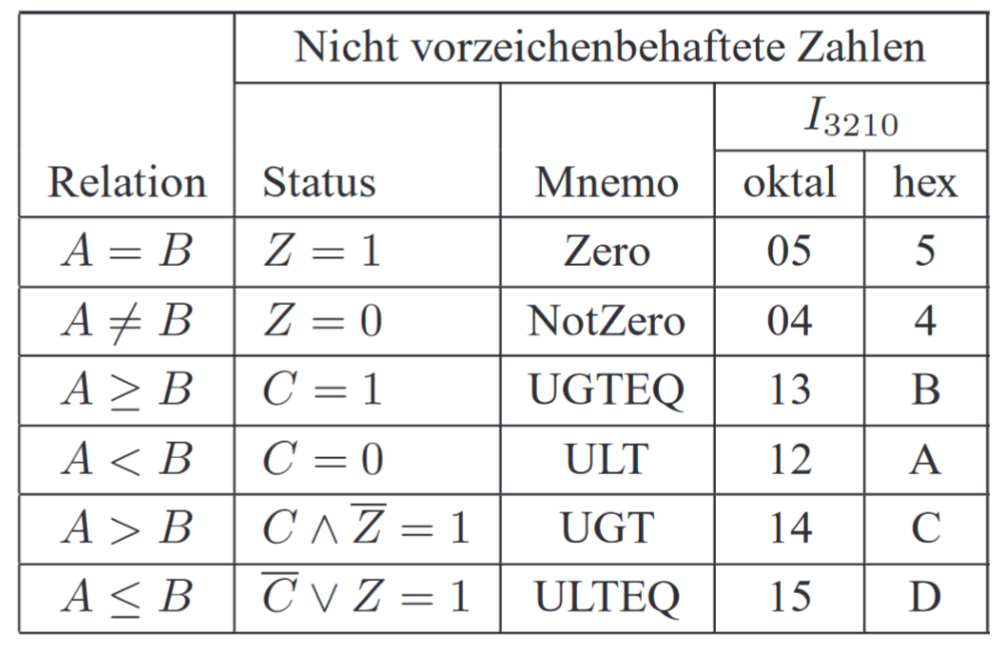
通过允许比特位(Enablebits)可以避免不预期的改变。它们是\(\overline{CE_{\mu }}和\overline{CE_{M}}\)通关建立的测试逻辑(Testlogik)可以访问状态寄存器。源于此的条件代码会在CT输出,它和在Mikroleitwerk中的测试入口\(\overline{CC}\)绑定。为了知道,条件访问从Mikrostatusregister还是从Maschienenstatusregister来,需要通道\(I_{4},I_{5}\)。当\(I_{5,4}=01(MI)\)时是从MikroSR被读取,\(I_{5,4}=10(MA)\)时时从MaschienenSR。通过\(I_{0}到I_{3}\)会在16种条件中选择1个条件。
从指令比特位(Instruktionsbit)\(I_{0}到I_{3}\)中选择的条件可以在下表中看到。这个表格可以在两个A-B操作之后用作比较。它会在之后传入在Mikroleitwerk的CC。
为了实施算数操作,我们需要多余数据的信号(Übertragssignale),它会从Am2904传入微计算单元。
12.7 微程序的例子
12.7.1 IFETCH
之前提过,IFETCH是拿到下一条指令的地址,并且跳转到这个地址。这些在3个时间脉冲中实现:
- Takt 1: BZ 被放到地址总线,并且有对存储器的读取 Bit 2-> E/H
- Takt 2: IR 被打开,下一条指令的数据会从数据总线被读取。
- Takt 3: 会执行JAMP指令,跳转到那个指令的地址,并执行那个指令
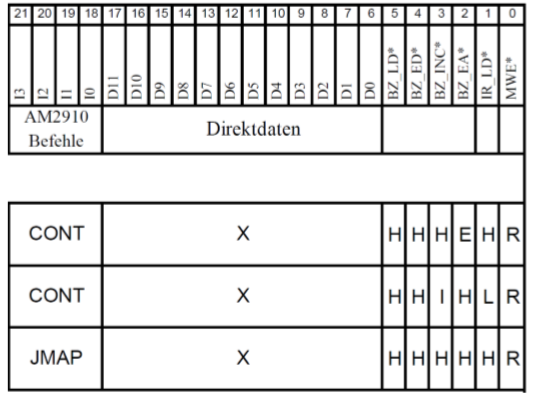
对这个功能,只有开头6个bit和AM2910指令是重要的。在整个过程,它是0,Bit为被设置成“R”,意思是可以从存储器读取。
- Takt 1:第2个Bit 被设成 "E" 。这使得BZ的内容被放在地址总线,对应的数据会从主存储器放到数据总线
- Takt 2:第1个Bit被设置成“L"。使得当前在数据总线的值会读取到IR里,此外第3个Bit被设成”I“,意思是BZ增长
- Takt 3:所有的控制Bit被设成”H“,为了避免不必要的激活。然后执行JMAP
12.7.2 简单加法
下面我们看两个寄存器(RA和RB)的简单加法,结果存在RB里
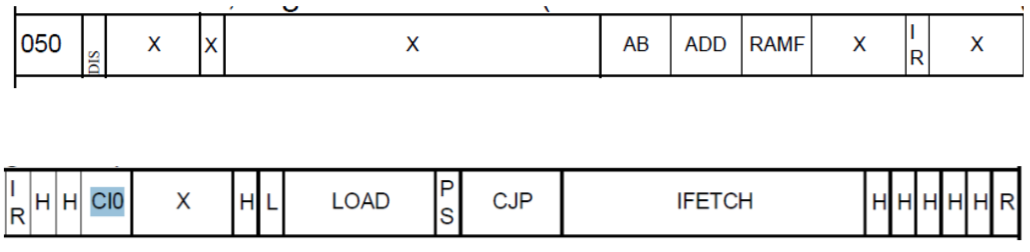
接下来会对每一个Bit详细说明
- 第一个相关的格子是”AB“。这个决定了它的操作数。它的意思是操作数”R“是寄存器A,操作数”S“是寄存器B
- 下一个格子”ADD“,这两个操作数会被加起来
- RAMF可以决定,操作的结果从F出口里出来,放到寄存器B里
- 有IR的两个格子说明了A-MUX和B-MUX从哪里取出地址。设置成IR说明地址从IR里读取不是从MIR里读取。
- 下一个”L“使得机器状态寄存器(Maschinenstatusregister)可以被改变
- ”CJP“意思是有条件跳转。由于CCEN Bit 被设置成PS(PASS),会无条件跳转
- IFETCH说明,会跳转到0,并且读取下一条指令
12.7.3 从存储器去寄存器
在这个例子中,我们将在一个存储空间(Speicherzelle),在寄存器A里的值,写入寄存器B。
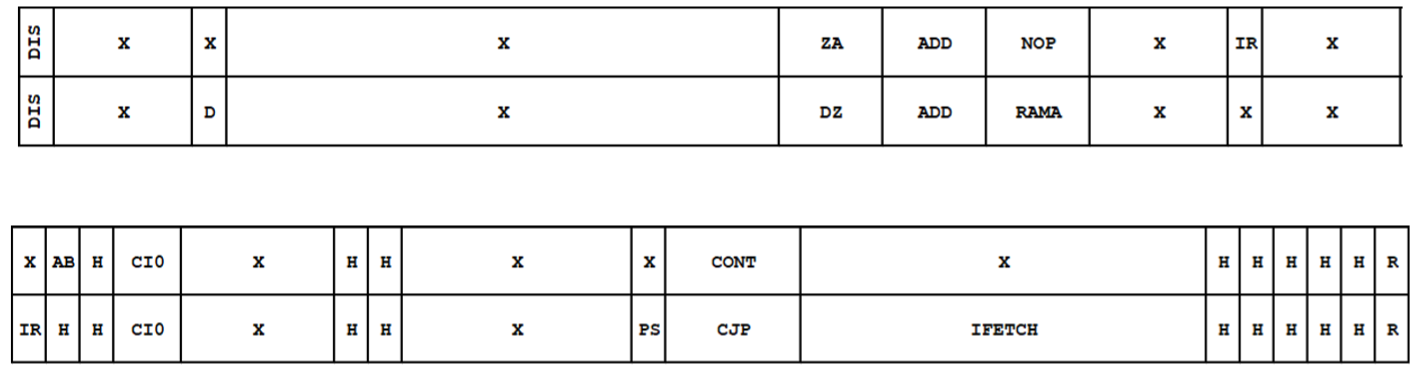
为了实现这个指令,我们需要2个时间脉冲:
- Takt1:把RA的值放到地址总线,于是我们就在存出器中得到了RA的地址。为此我们需要操作数ZA,于是我们得到了RA的存取和0。这个值被加起来放到数据总线上。(YMUX=AB)
- Takt2:我们把这个值从数据总线读取到RB里,为此我们把信号从KMUX设置到DB。于是给计算单元的下一个值就从数据总线出来了,当我们此外操作数选择(Operandenauswahl)设置成”DZ”。接着我们使用位移指令“RAMA”或者“RAMF”,它把值从ALU的F出口出来,放到B寄存器中。
- 接下来跳转到地址0处执行IFETCH
12.7.4 Conditional Jump Carry
下面我们看如果Carry被设置了的有条件跳转。这个指令跳转到一个已知的地址,当Carry Flag被设置。否则就接着执行。
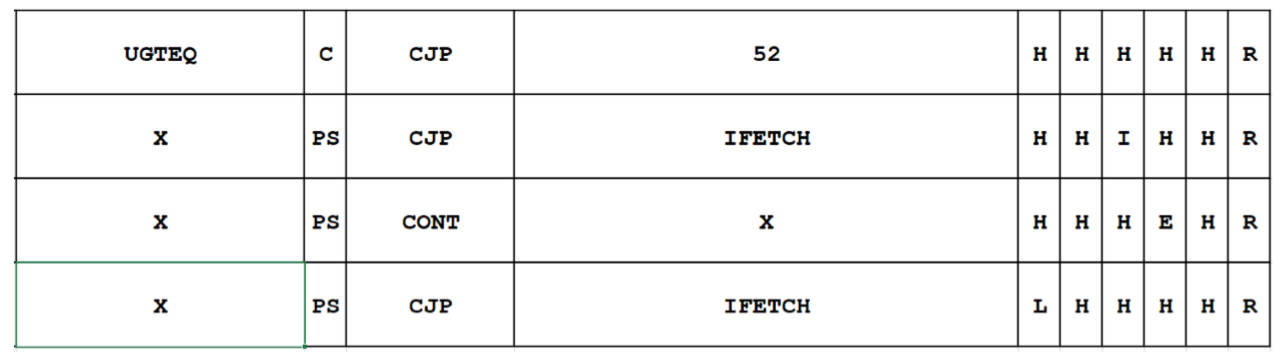
在这个例子里,我们假设第一行对应地址50并且立即值(immediate-Wert)是52
- Takt1:会用UGTEQ检查,CF有没有被设置。把CCEN-Bit设成“C”,为了说明,这个条件已经检查过了。如果CF被设置,那么会跳转到地址52处
- Takt2:(Adr.51)如果没有被跳转,会接着执行地址51。目前BZ还显示着立即值,它却不被需要,所以BZ必须增长(3. Bit)。然后执行一次IFETCH使程序继续执行
- Takt2:(Adr.52)如果跳转了,程序必须从52处继续执行,BZ必须放到地址总线上,于是下一个Takt可以读取下一个指令
- Takt3:最后一步BZ从地址总线被读取。因此现在存储空间的数据在地数据总线的BZ的地址上。这个值会重新加载到BZ上,然后执行IFETCH。
13 笔记ALU编程
- CJP 指令
- \(\overline{CCEN}=PS\) CJP指令从D入口读取地址,它是BAR-Feld绑定在一起
- 主存储器
- \(\overline{MWE}=R\) 允许读取
- \(\overline{MWE}=W\) 允许写入
- 计算单元
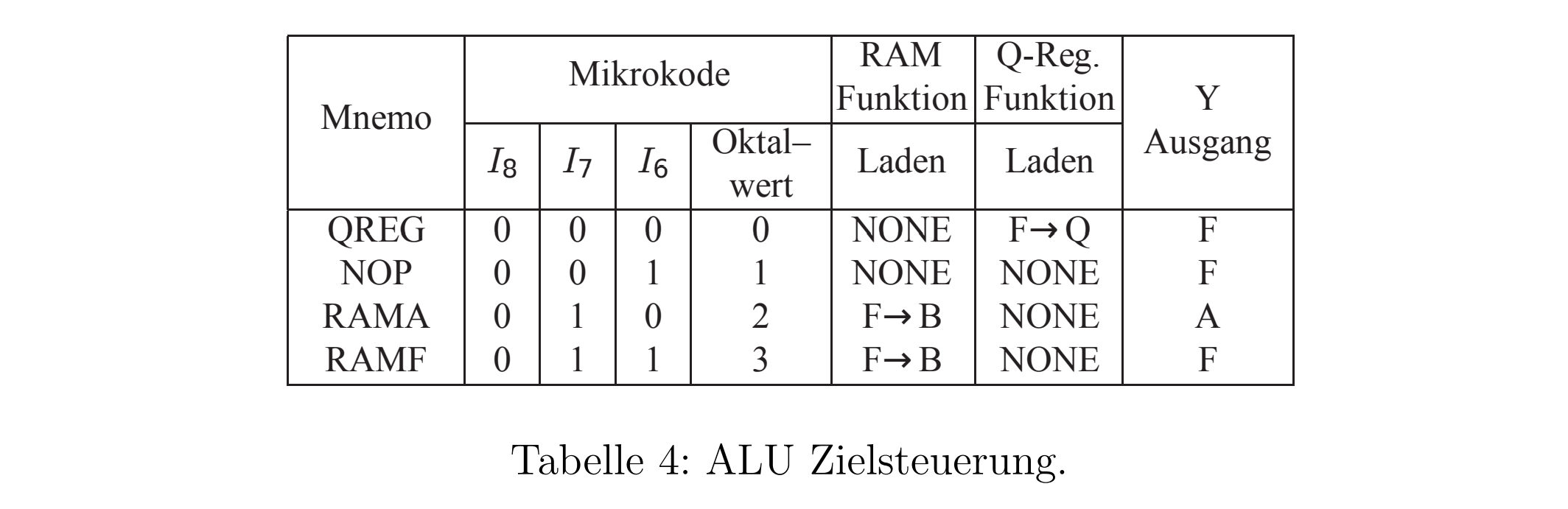
从A和B入口可以选择使用16个计算单元的内置寄存器
- 总线
- 下面的元件可以放在地址总线:
- BZ 通过 \(\overline{BZ\_EA}=E\)
- Rechenwerksbaustein 通过 \(\overline{ABUS}=AB\)
- 只有主存储器可以读取地址总线上的数据
- 这些元件可以放在数据总线上:
- 主存储器 \(\overline{MWE}=R\)
- BZ 通过\(\overline{BZ\_ED}=E\)
- Rechenwerksbaustein 通过\(\overline{DBUS}=DB\)
- 下面的元件可以从数据总线上接收数据
- 主存储器 \(\overline{MWE}=W\)
- BZ 通过\(\overline{BZ\_LD}=L\)
- Rechenwerksbaustein 通过\(KMUX=D\)
- IR 通过 \(\overline{IR\_LD}=L\)、
- 模板:
CI0/CI1:
使用r0:
- BSEL/ASEL:MR
- RA/RB Addr :0
从DB里读取:
- KMUX = D
结果到RB:
- DEST: RAMF
- Y-MUX: HH
结果到Adressbus:
- DEST: NOP
- ABUS: AB
第14章 物理层Physikalische Schicht
在这一层会把抽象的通过符号表示的电子元件通过半导体实现。半导体是一个化学元素,它的导电性在导体和绝缘体之间,所有它比较适合做晶体管(Transistor)。关于半导体,我们主要用硅。
通过添加有针对性的杂质,可以实现在低温下的导电性能。我们通常用p添加(p-Dotierung, Aluminium),或者n添加(n-Dotierung, Phosphor)。这些添加在一个特定的排序,通过电场,可以实现晶体管。
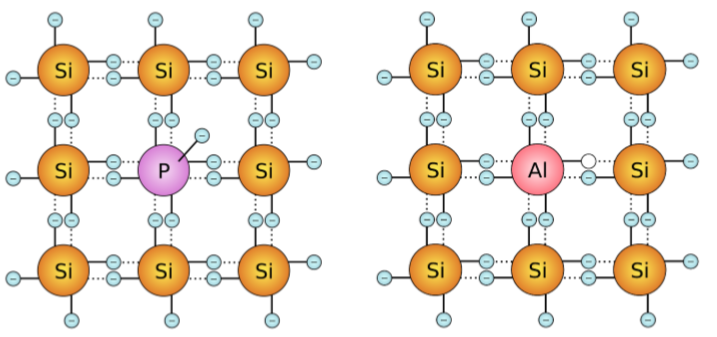
14.0.1 晶体管作开关(Transistoren als Schalter)
晶体管是最重要的开关元件在微架构里。为什么晶体管这样工作取决于半导体的自身品种。在n导区域和p导区域(n-leitenden und p-leitenden Zonen)的接触表面(Berühungsfläche)存在一个隔离层(Sperrschicht),它使得通常情况下没有电流流过晶体管。这个隔离层只会通过一个控制电流或者控制电压被提起,只有这样,电流才可以流过。(一个晶体管由2个pn通道(pn-Übergängen)构成)最常用的晶体管叫MOS晶体管(MOS-Feldeffekt-Transistor) (MOS -> metal-oxide-semiconductor)
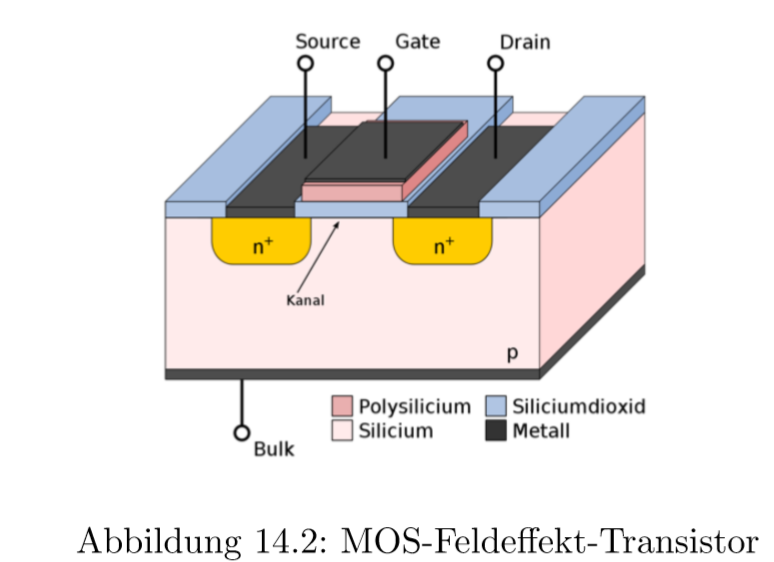
14.0.2 MOS晶体管
一个MOSFET有2个状态:
开 Schalter offen
通过一个正电压加在隔离门(isolierten Gate),电子从硅底层(Silizium-Substrat)被抽到表面。在2个n-区域中间(Source, Drain)由此产生了狭小的n导层(n-leitende Schicht)。通过这个狭小的层可以使得电流从源流向汇点
关 Schalter geschlossen
当门电流远离的时候,导电的通道消失,晶体管不再能导电
通过门电压可以控制Drain电流的有和无
14.0.3 半导体生产过程
半导体的生产过程可以简单分为8个步骤
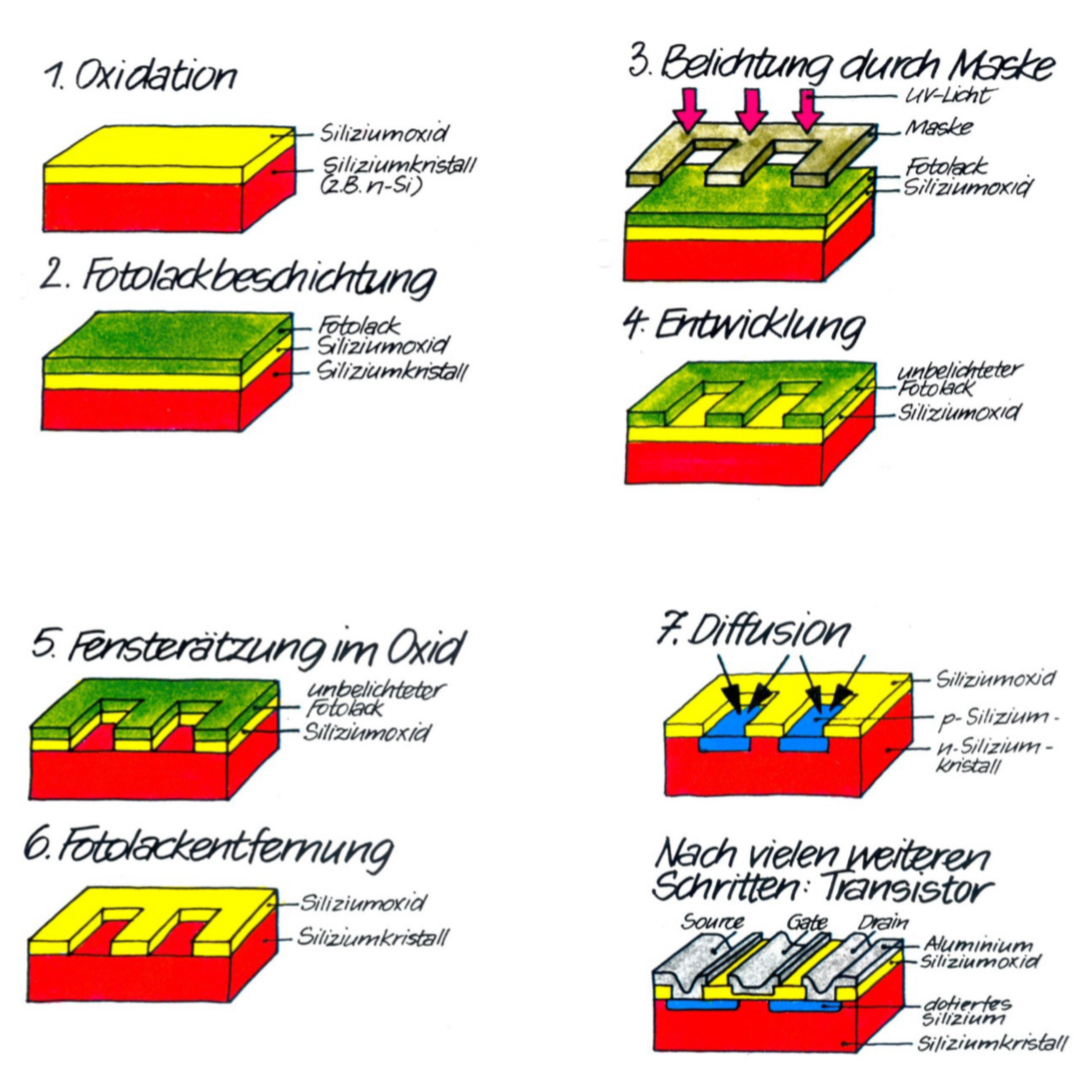
- 我们从一个硅层开始
- 上面图上光刻胶(Fotolack)
- 未完成的晶体管被光照,上面会放一个模板(Schablone)在光源和晶体管之间
- 通过光照在光刻胶上产生了洞
- 然后我们会用有腐蚀性的(ätzend)的东西,在这些窗口洞上的氧化硅移除
- 接着光刻胶被移除,之后就可以看到晶体管的基本结构
- 通过扩散(Diffusion)可以产生p层和n层(p- und n- Schichten)
- 在之后的几步就有了完成的晶体管
第5部分 Gatter 层
第15章 Schaltnetze
首先我们讨论Schaltnetze,这个没有状态。它只有入口值,通过一个过程函数转换成出口值。
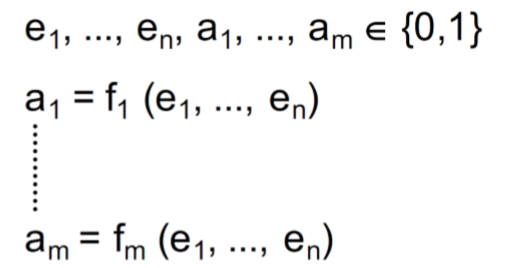
15.0.1 Schaltfunktionen
简单来说,n元开关函数(n-stellige Schaltfunktion)是一个函数,它是由{0,1}的集合构成的。也就是\(\{0,1\}^{n} \rightarrow \{0,1\}\),我们有n个输入信号,1个输出信号
例子:
单元开关函数(Negation)
neg: {0,1} -> {0,1}
neg(0) = 1, neg(1) = 0
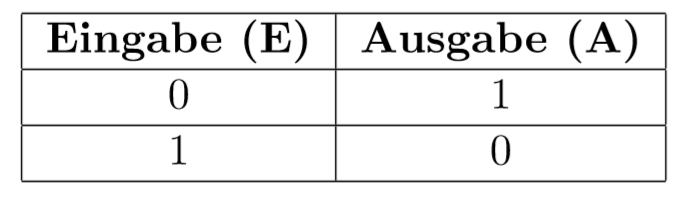
二元开关函数(Konjunktion)

15.0.2 1集和0集
- Einsmenge : 所有输入源的集合,使得输出的集合是{1},比如neg = {(0)}, konjunktion = {(1,1)}
- Nullmenge: 所有输入源的集合,使得输出集合是{0}, 比如konj = {(0,0),(0,1),(1,0)}
15.0.3 Gatter - Elementare Einheiten
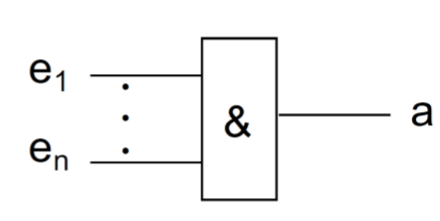
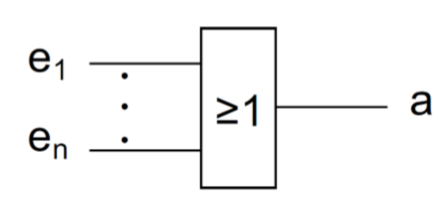
门(Gatter)会通过开关函数被描述。Konjunktion 用 \(\&\) , Disjunktion 用 \(\geq1\)
Konjunktion(UND)
Disjunktion(ODER)
初次室外还有Not-And(NAND) 和 Not-Or (NOR)门被使用
15.0.4 Negation
为了表示取反,我们在入口和出口引入了一个小圆圈,在出口画上了一条线
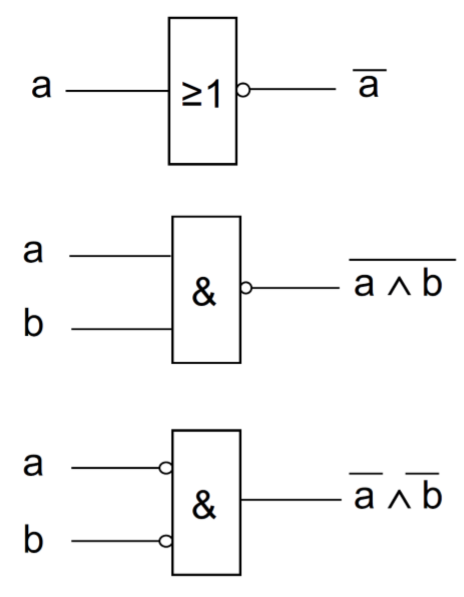
15.0.5 另一种符号
当我们在网上看各种电路图,它们会经常使用其他符号
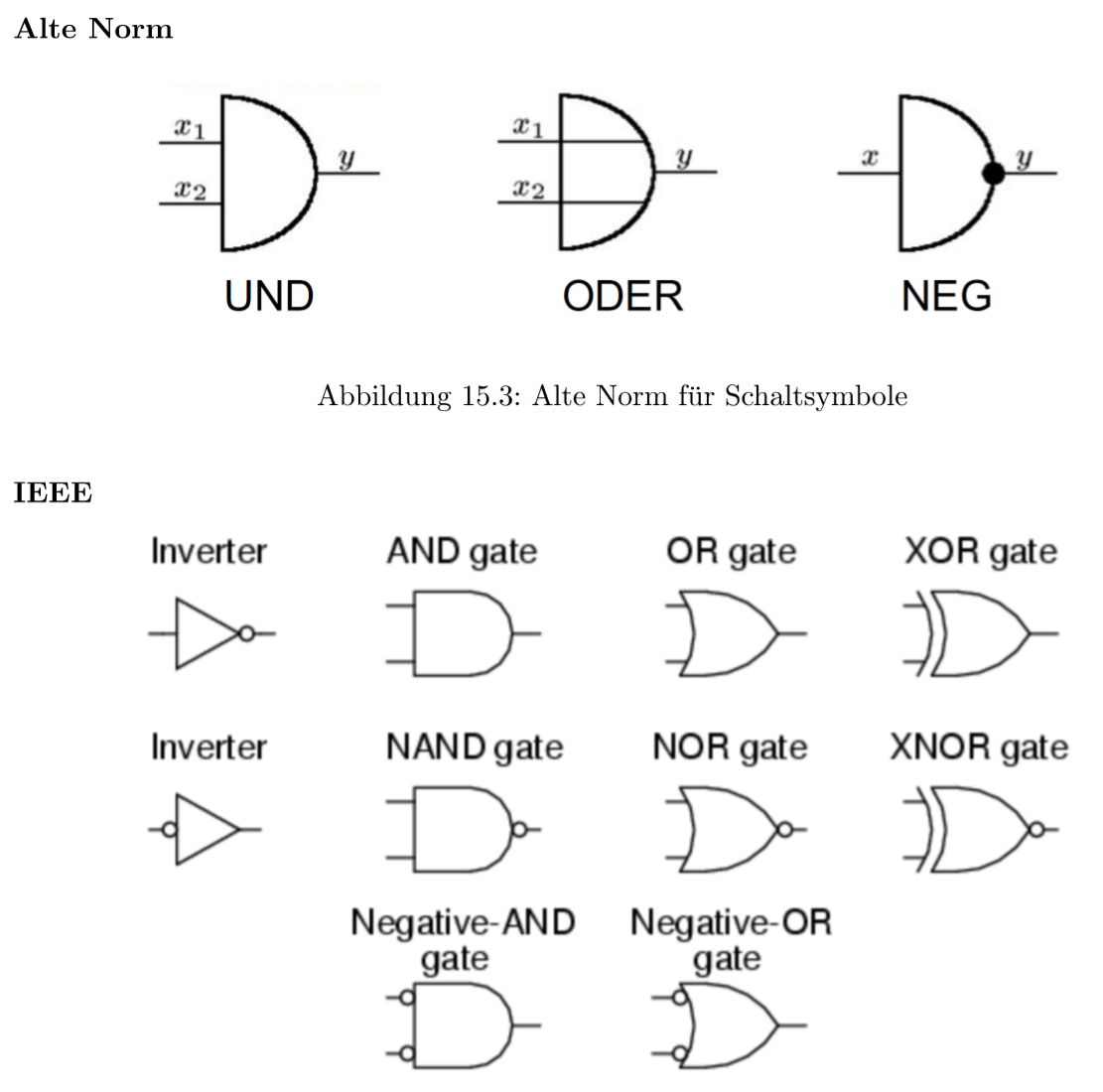
15.0.6 数据流网Datenflusspläne
许多门符号可以组成数据流网,它还被叫做逻辑电路图(logische Schaltpläne)。
比如\((x\wedge y\wedge z)\vee(x\wedge y\wedge \bar{z})\)

15.0.7 布尔代数
一元运算符:\(\neg\)
二元运算符:\(\and ,\lor\)
15.0.9 一些公式

15.0.10 对偶Dualität
每个公理都有是一对的\((\and,\lor,0,1)\)和\((\lor,\land,1,0)\)
接下来我们会使用下面的写法:
- \(\bar{a}\) 替代\(\neg a\)
- 优先级:not ,and, or
- \(ab\) 替代 \(a\land b\)
15.0.11 Schaltnetz
一个Schlaltnetz是一个功能单元,它实现了一个或者多个开关功能(Schaltfunktion)。所有我们可以把一组开关功能用\(\{0,1\}^{n}\)来表示

15.0.12 加法器
它由4个入口(2*2Bit)组成,用来双重计算加和。
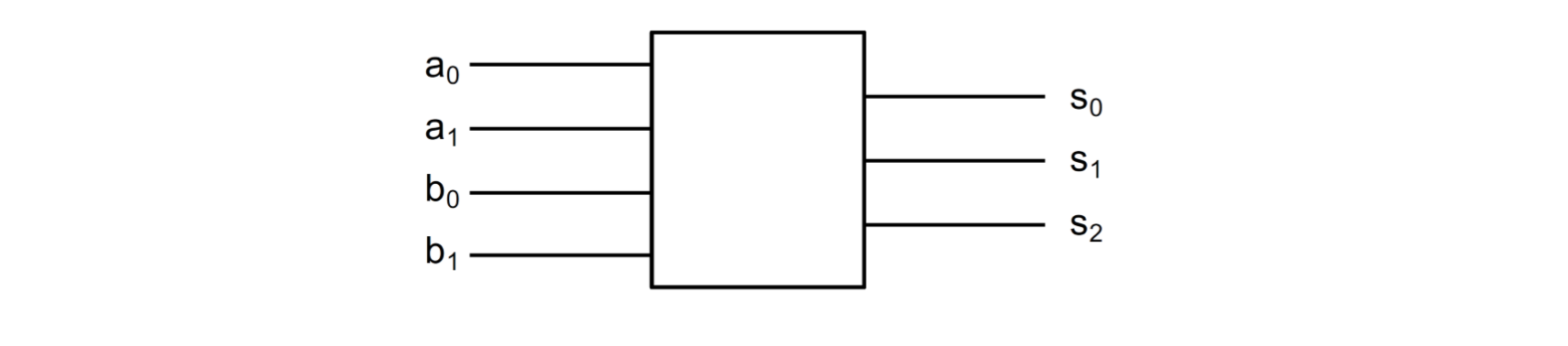
从入口信号集合我们可以看出,它有多少个定义的点。所以一个n元的开关函数\(2^{n}\)个定义的点(比如在4个入口,就有16种不同的数据可能性)
15.0.13 解码器Decoder
对于入口为P的解码器,最多可以有K个出口,\(k\leq 2^{p}\)

经典的解码器有:
- 在存储器中的地址解码器、
- 在控制单元和计算单元的指令解码器
比如一个2Bit的解码器长这样
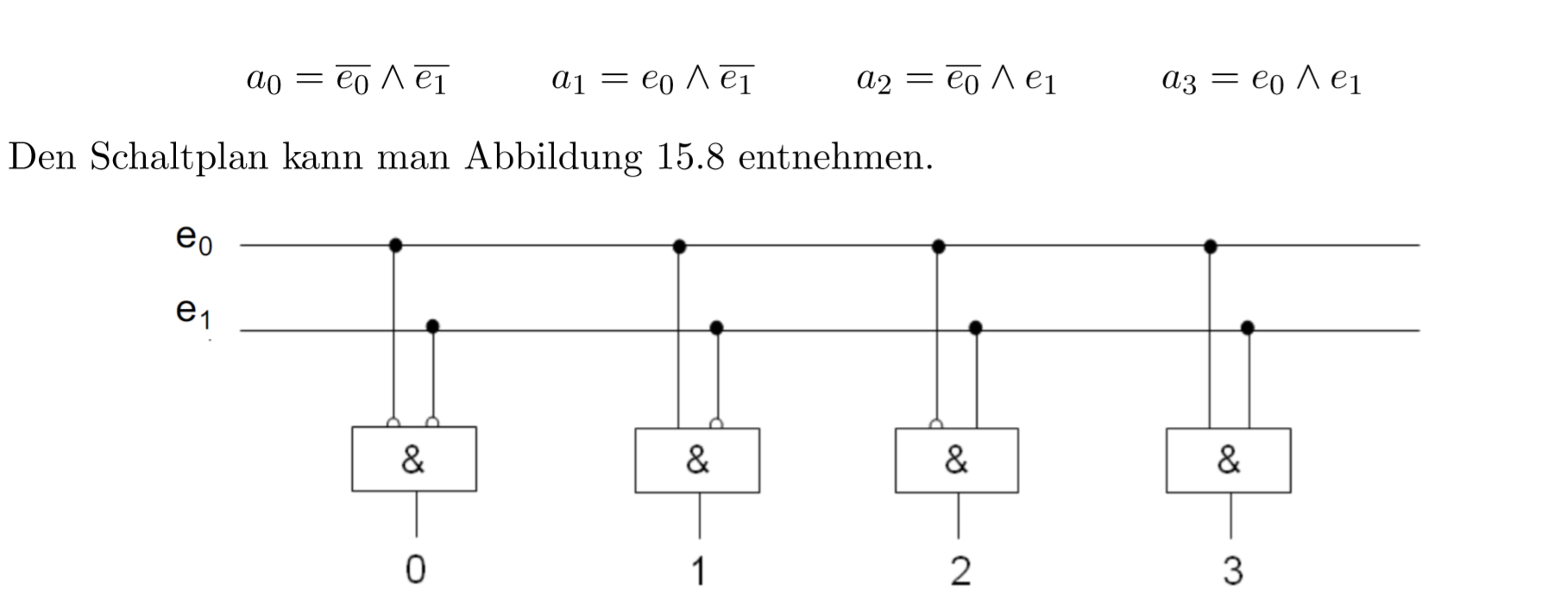
15.0.14 编码器Encoder
他是解码器的对立面。K个入口,P个出口,\(k\leq2^{p}\)

比如一个2Bit的编码器:
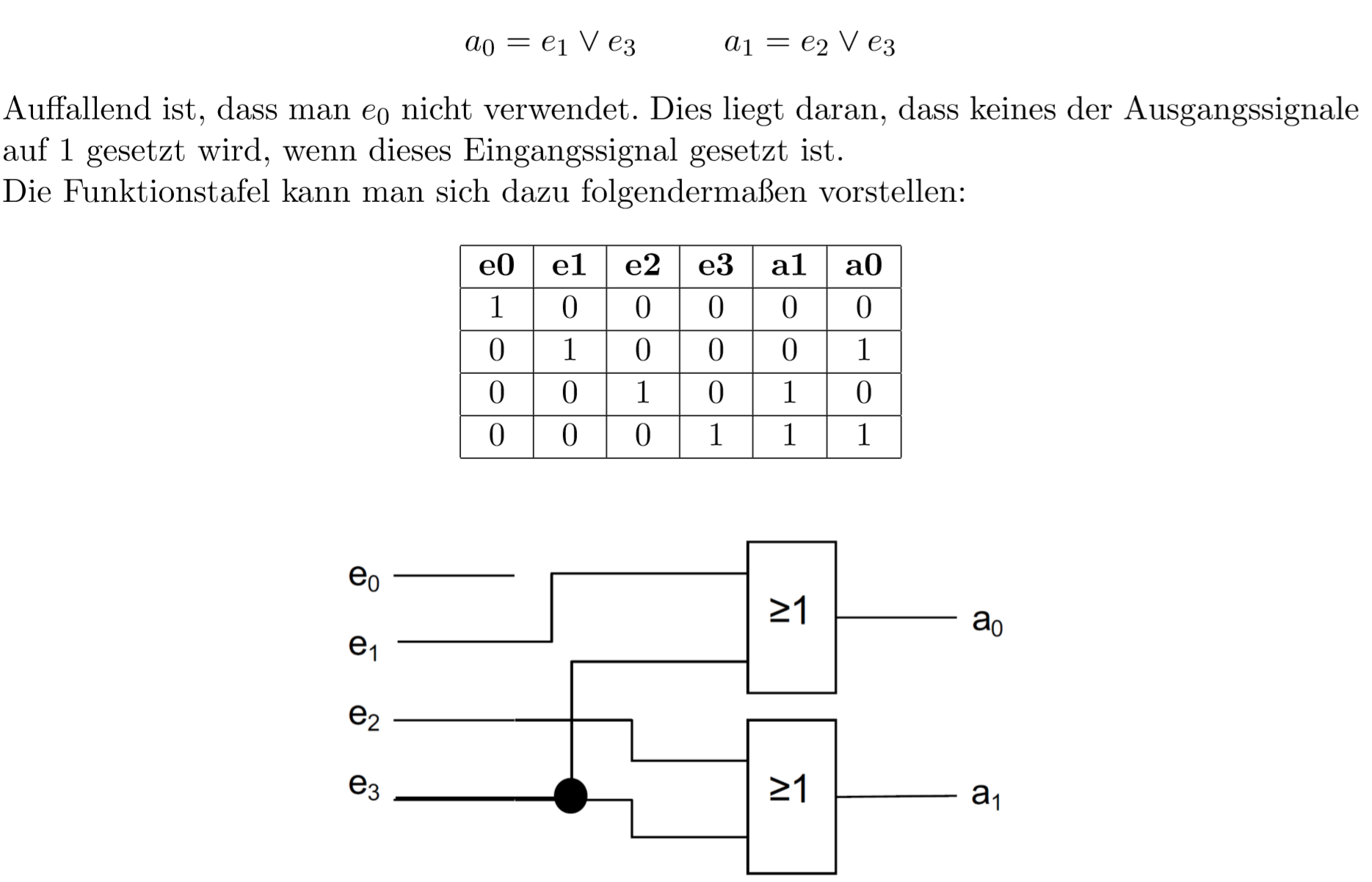
15.0.15 选择器和反选择器 MUX/ DEMUX
它们被用来选择那些入口信号可以出来。对于一个n源\({log_{2}}^{n}\)有个控制信号。
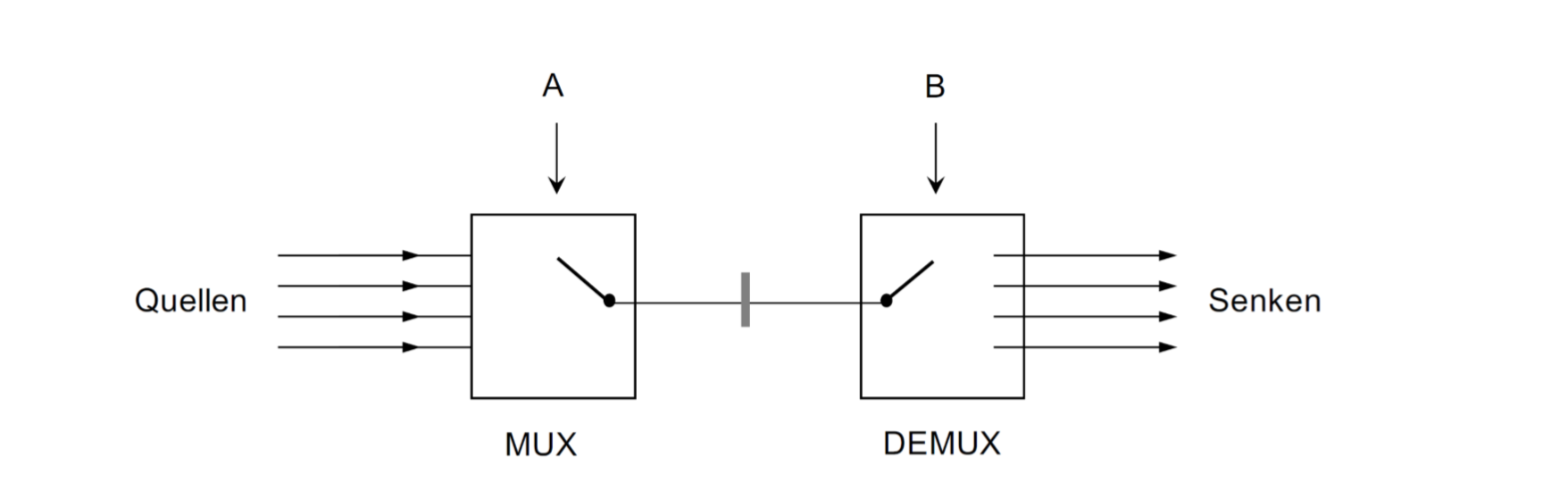
比如下面是一个选择器/反选择器的具体实现:
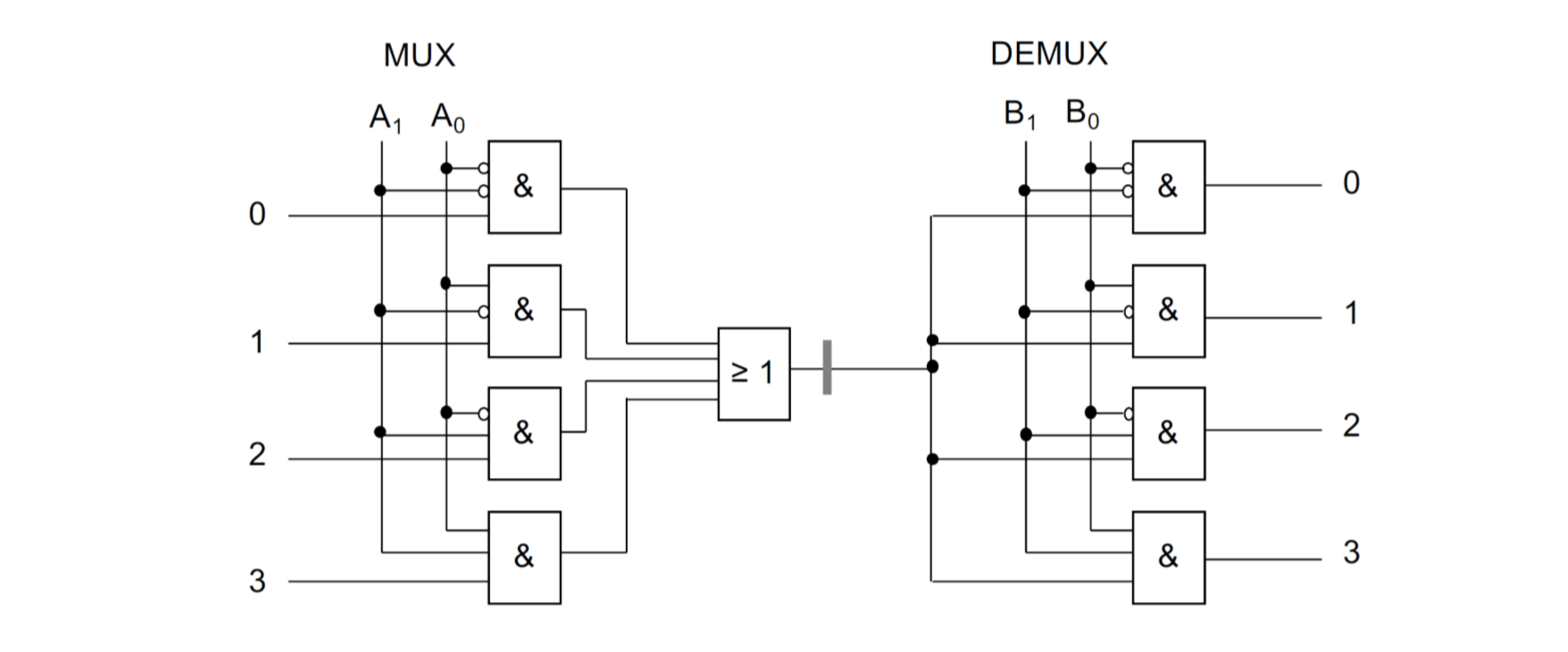
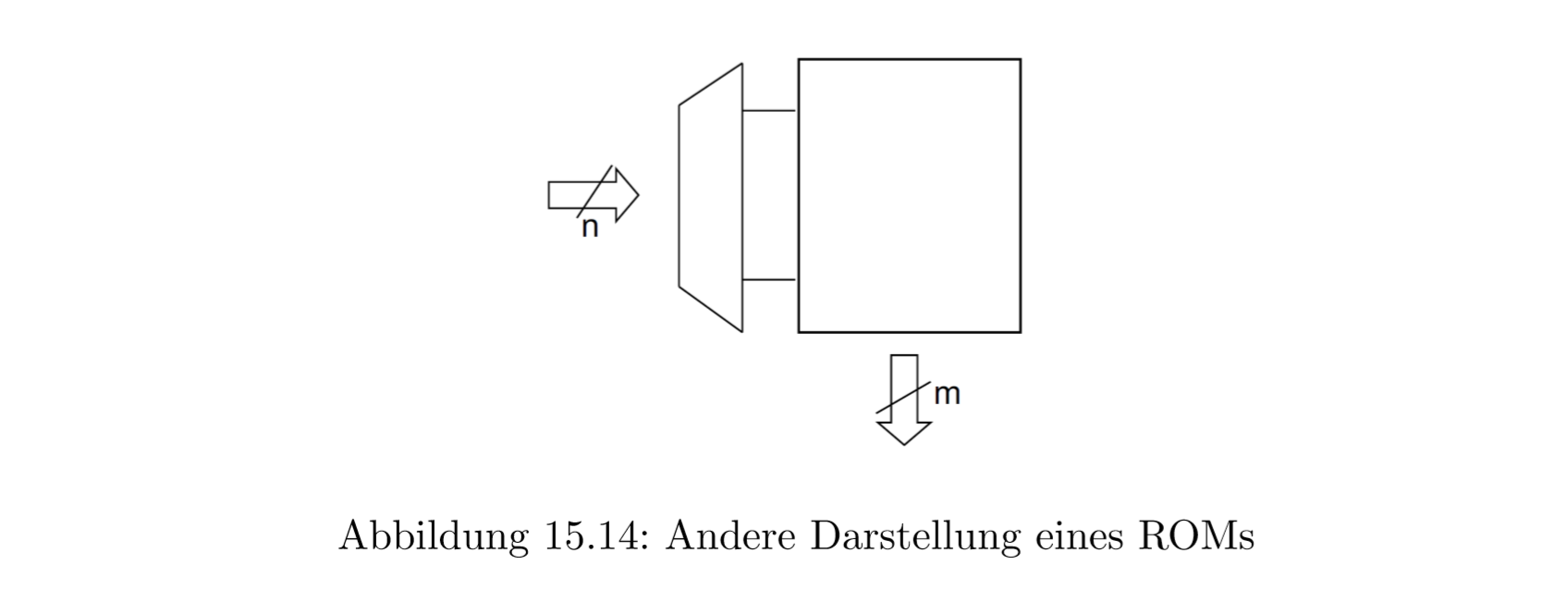
15.0.16 只读存储器Festspeicher (ROM)
一个结合逻辑电路网的例子是ROM。在这里我们用一个n元函数映射到m元上。
- 我们有n元的地址
- 我们有m元的数据单元
我们可以组合解码器和编码器
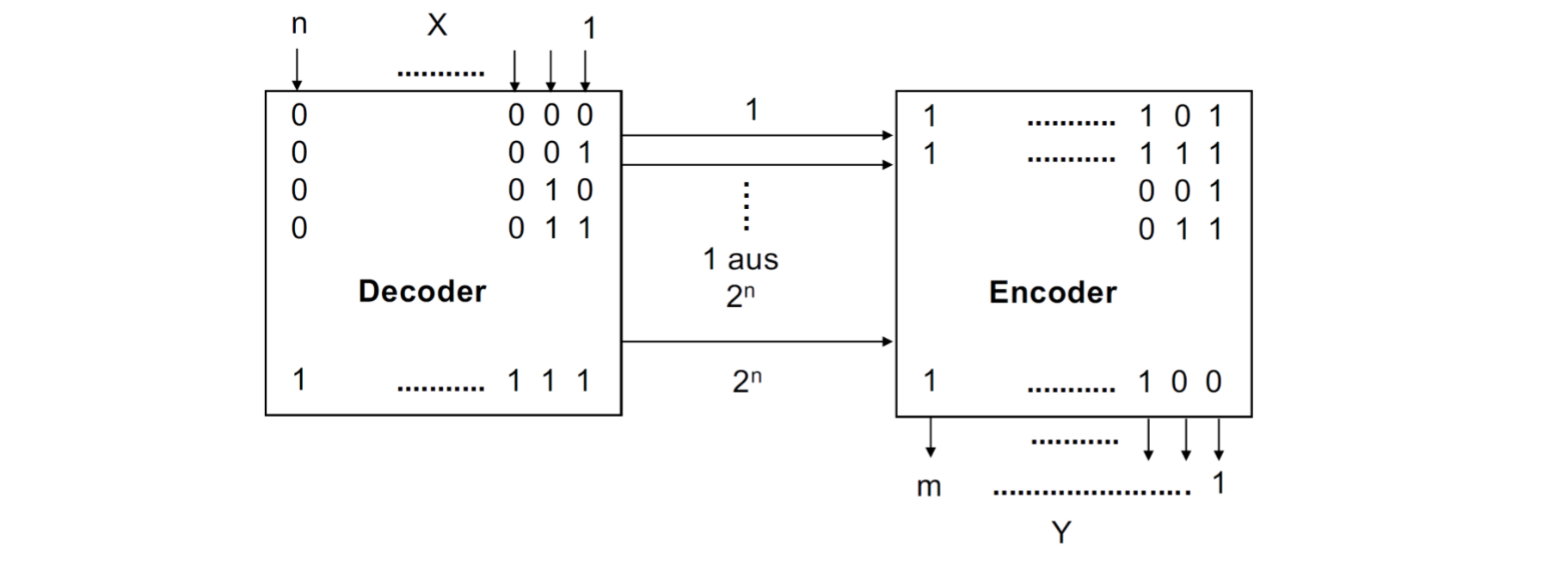
另一个可能的表示是:
15.0.17 电路函数Schaltfunktion和电路代数Schaltalgebra
一个Schaltnetz可能由多个Schaltfunktion组成,所以每个输出信号都由一个Schaltfunktion。怎么来表示它呢?我们可以用DNF来表示它
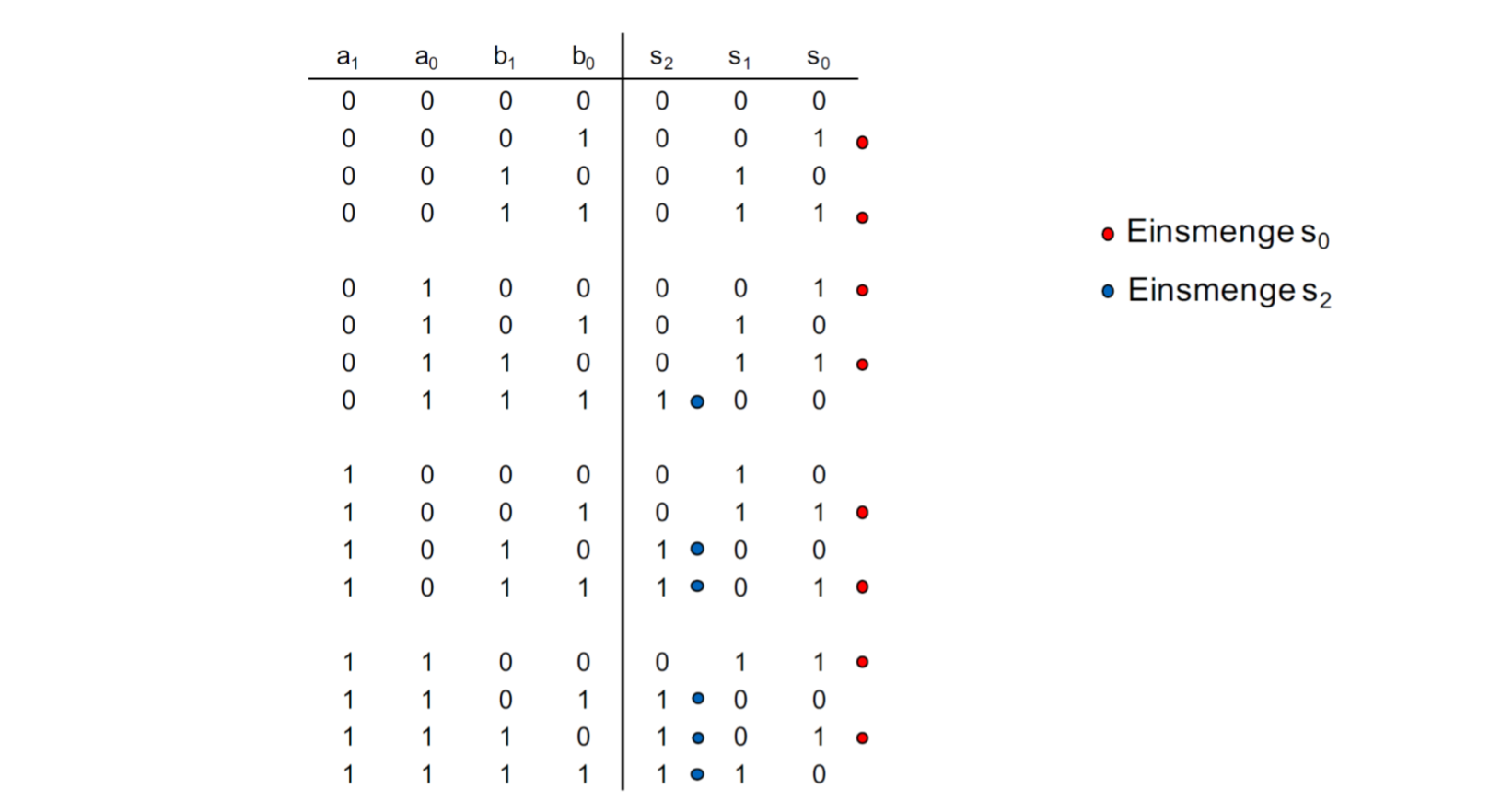
对应的DNF是:
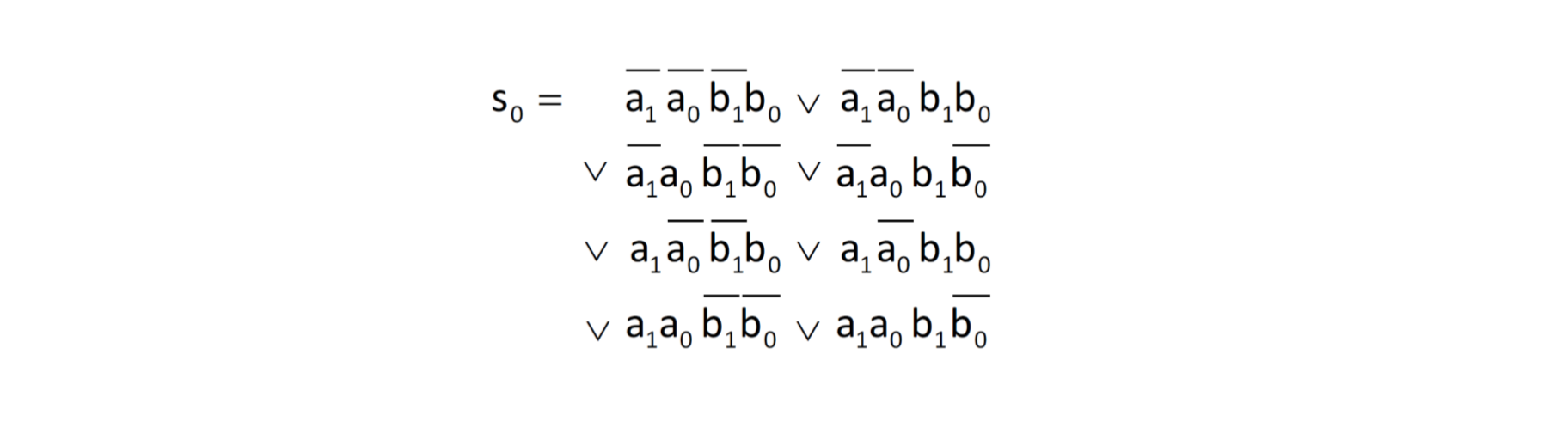
15.0.21 代数组合
DNF和KNF过于繁琐,如果我们之间在电路网上实现的话。所以要简化DNF和KNF。比如下面这个简化
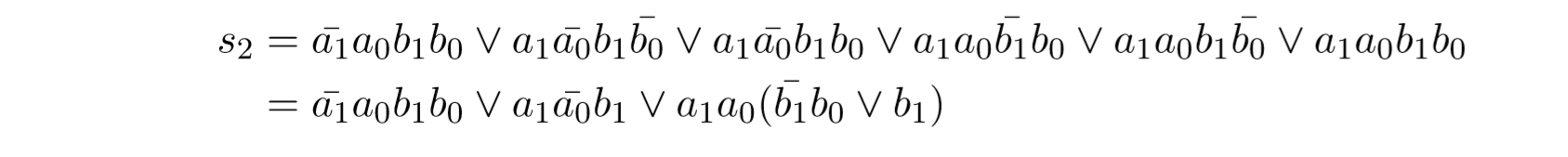
现在问题是,这个形式是否更好了。DNF的优势是穿过的电路开关都是一样的。当我们化简过后实现它,会出现通过4个元件的路径,他会导致不可预见性的问题
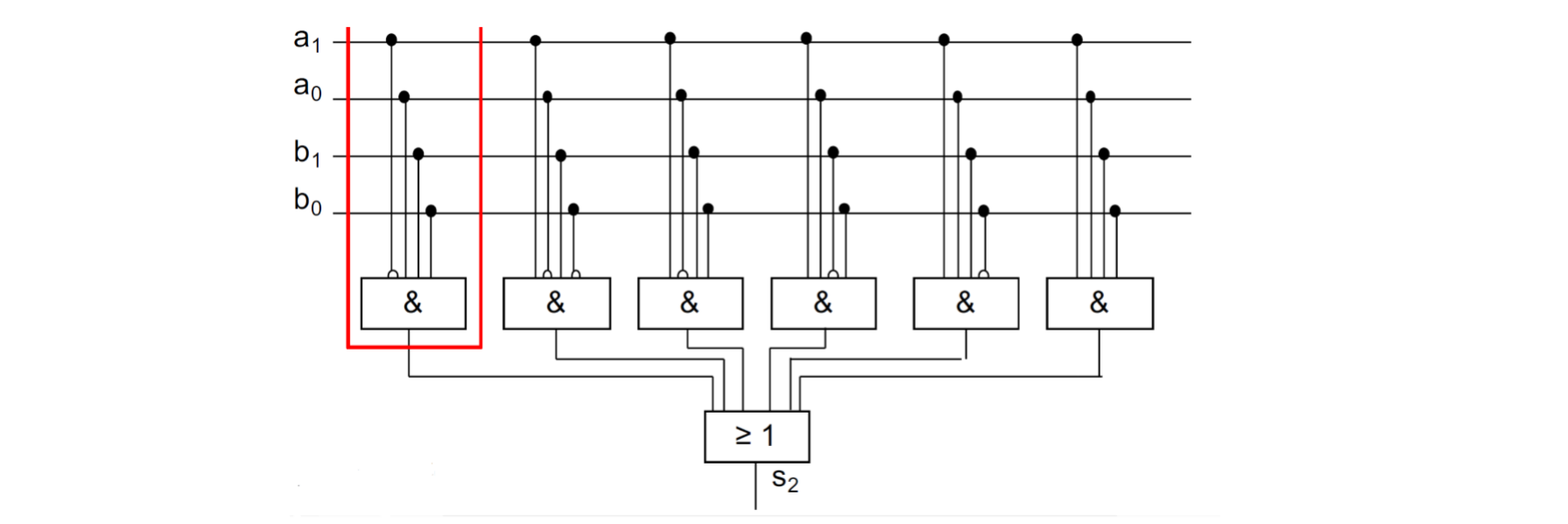
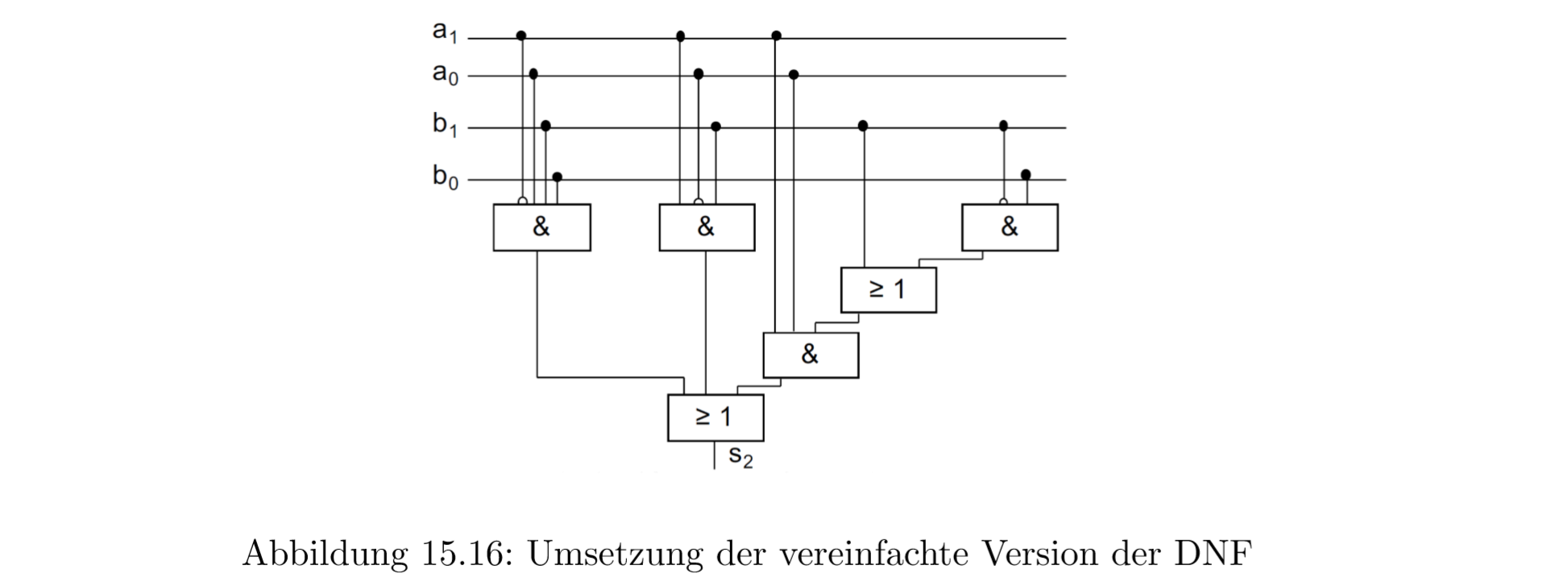
15.0.22 电路网简化
我们想要:
- 少的电路元件
- 少的入口
- 少的层次(Stufen)
- 短的电路
- 便宜的电路元件
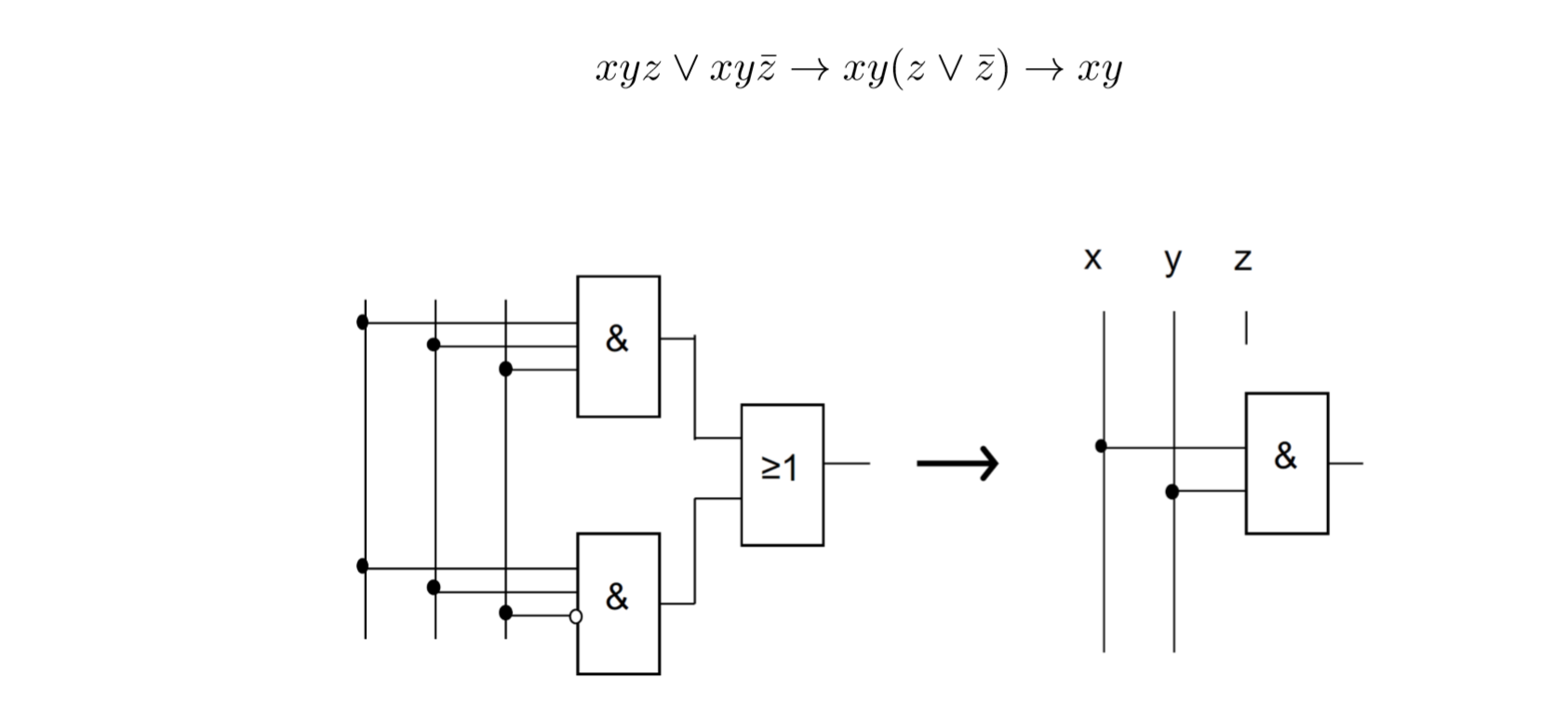
然而没有简化电路的有效算法。简化电路的开始是融合(Verschmelzung),比如下面:
为了简化电路,我们需要下面的定义:
- k元单项式(k-stelliges Monom) : k个单项式的KNF形式
- Minterm:n元单项式
- Disjunktives Polynom: 几个单项式的DNF形式
- Argumentbereich 1位导致不同: 相邻的\((01011,00011)\)
- 这个相邻的概念可以从多项式看出:\(x_{1}\bar{x_{3}}x_{4},x_{1}x_{3}x_{4} \rightarrow x_{3}\)不相关
- Verschmelzungsmenge消除集合:n元单项式变成k元单项式
比如n=3
下面这个式子被简化:
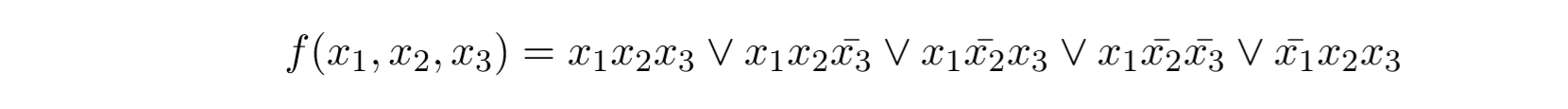
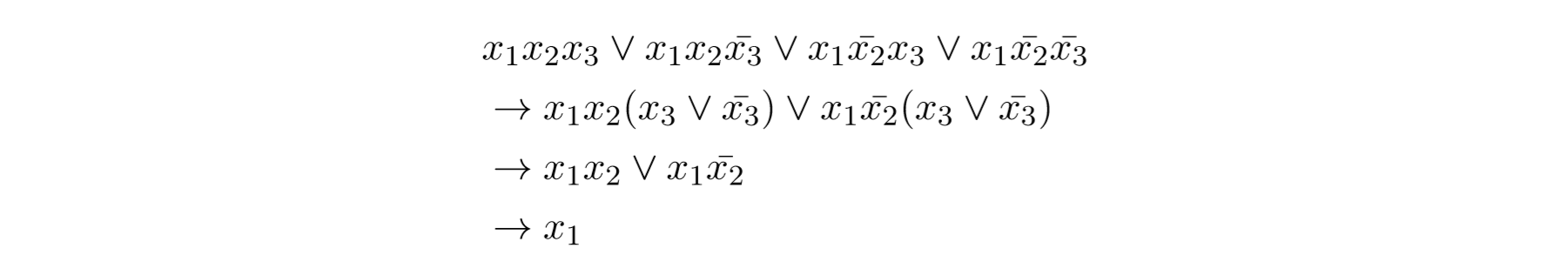
我们只能合并有1项不同的两个式子。或者我们可以扩展,在后面加上相同的元素
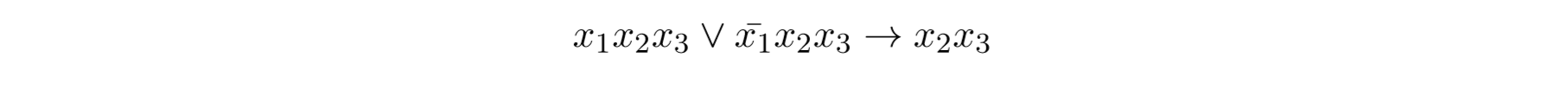
另一个简化可能性是图象式简化,这里我们可以应用编程,对于简化我们需要n维立方体:
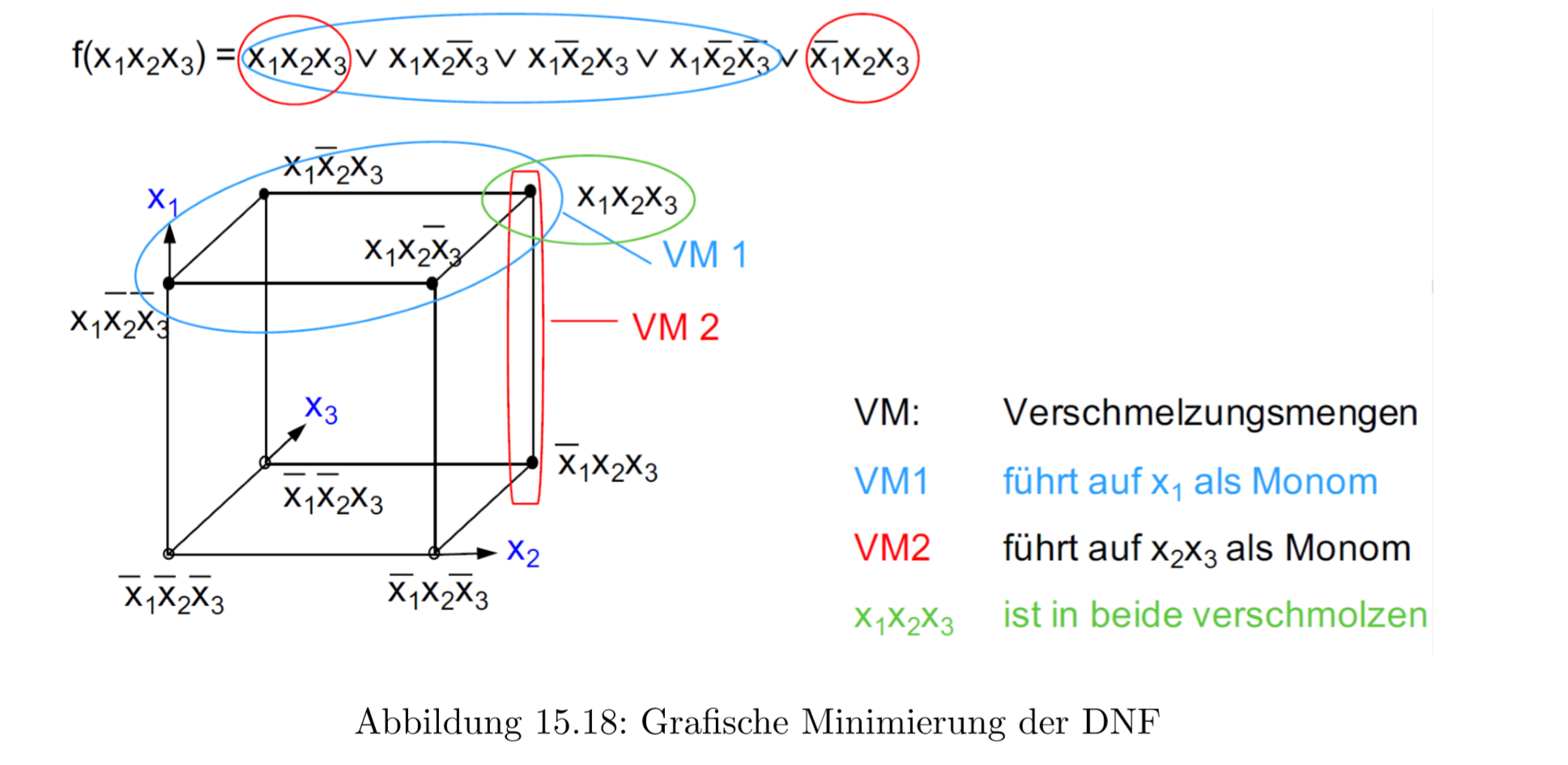
15.0.23 KV图
另一个展示可能性式KV图比如下面的
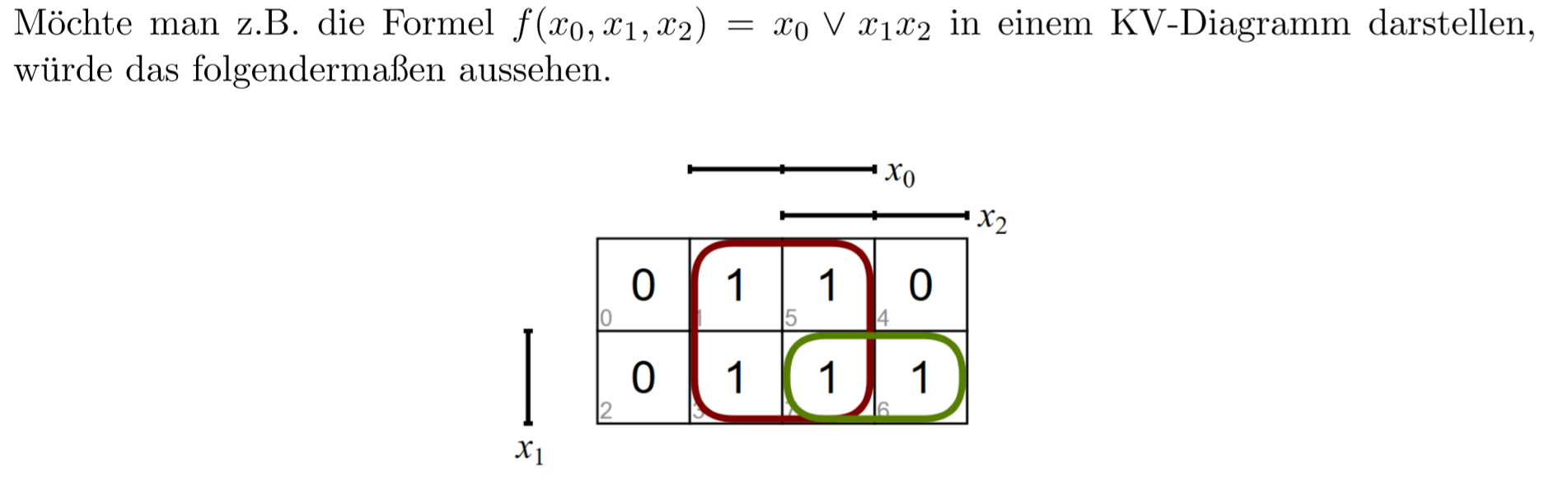
在这里,每一个长方形都可以变成一个变量。
简化
现在我们可以堆每个图里的单个值用1个n元的Minterm表示。这却不是很高效,因为:
- 标记所以在DNF/KNF里的Minterme/Maxterme
- 当式子可以消融,那么就可以组合
构造
KV图没有固定的格式,比如下面式2个变量的,有8种不同的KV图
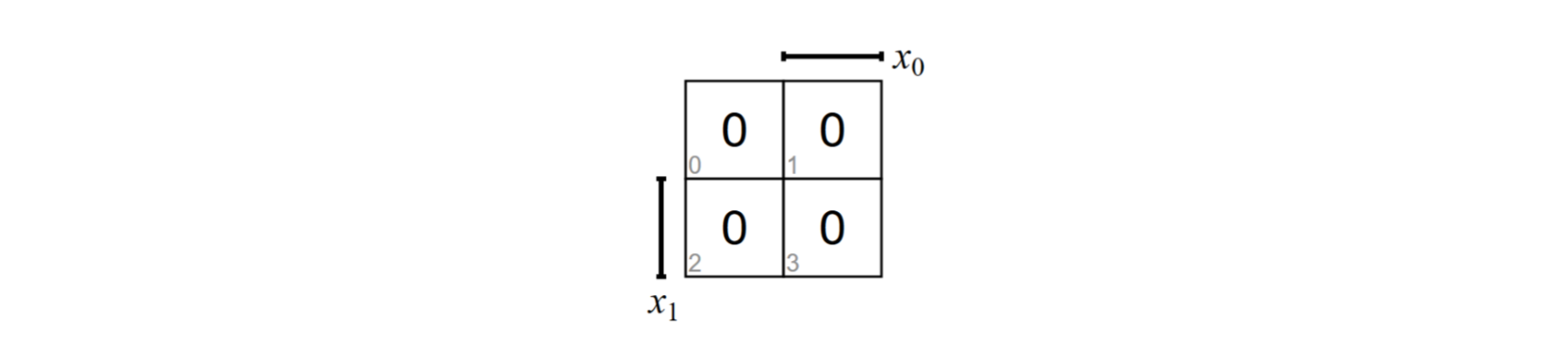
所以我们可以用以下几点:
- 当KV图式正方形的时候(变量是偶数个),可以向右对称
- 这个新的地区就对应了新的变量
- 当KV图是一个长方形(奇数个变量)那么向下翻
- 新地区是新变量
比如下面这个是n=3和n=4
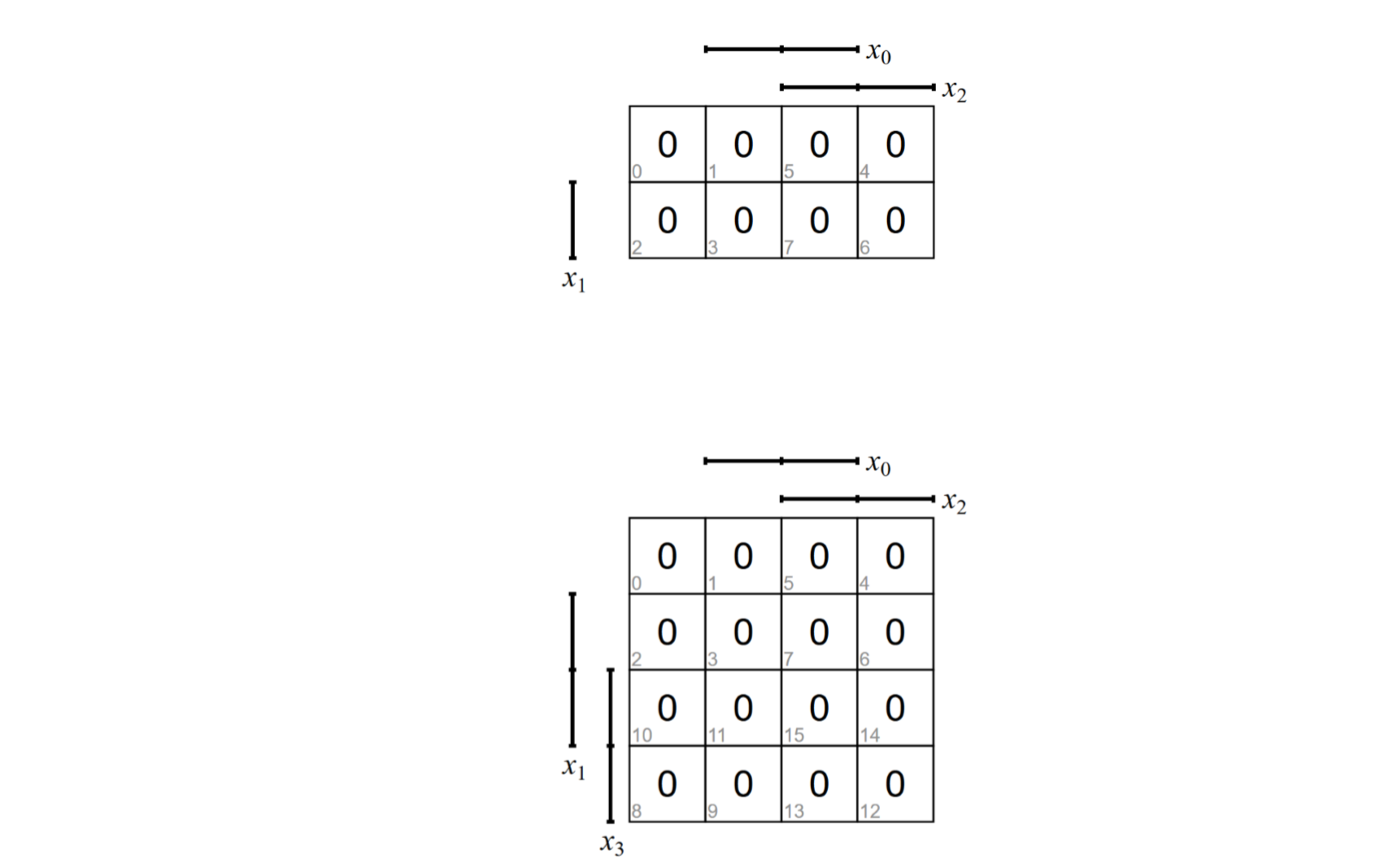
相邻特性
在KV图里,我们也观察相邻特质。
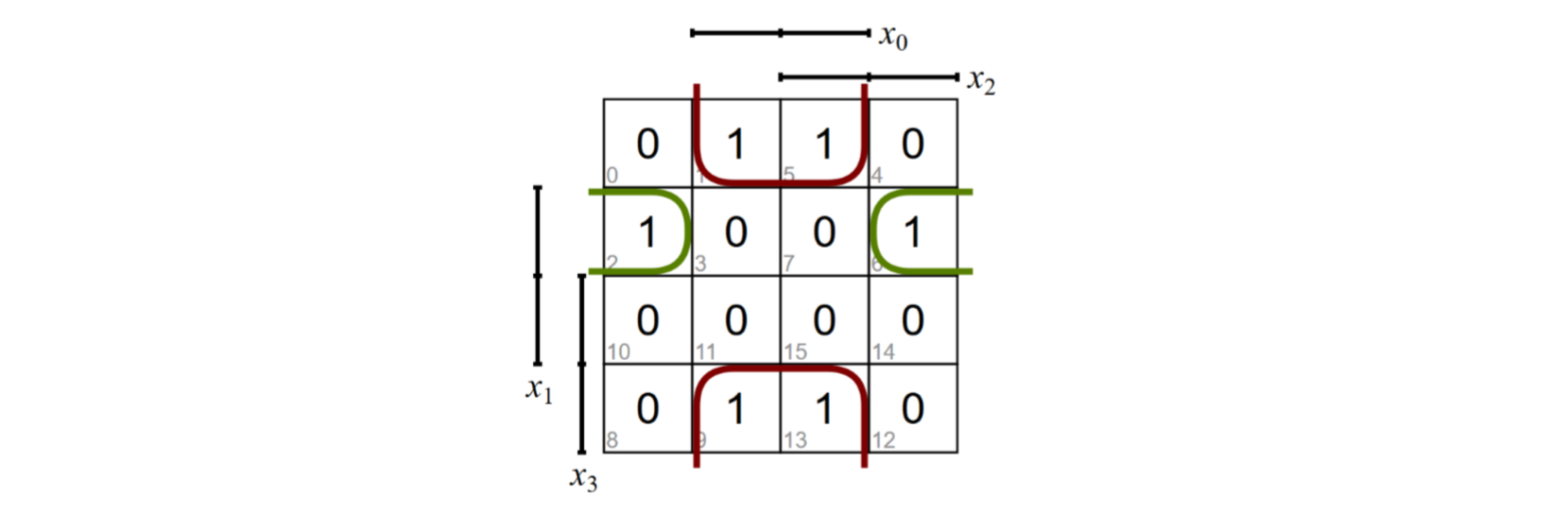
比如n=4
我们想要简化下面的式子:
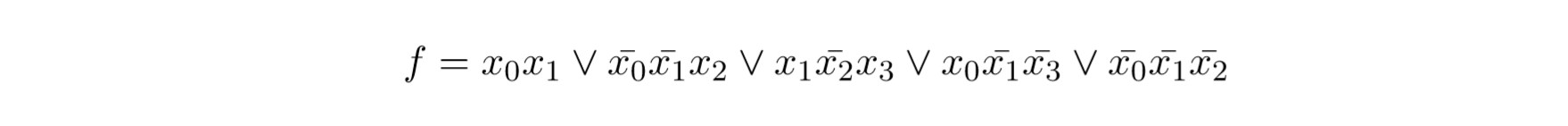
于是我们可以这么做:
- 所有的Minterme放到KV图里
- 构造2,4,8...的组
- 这些组合必须相邻
- 由这些组合我们有新式子
- 那些不能简化的Minterme,我们叫蕴涵项Primimplikanten
- 我们的目标是从蕴涵项里得到最小DNF
- 结果不一定唯一
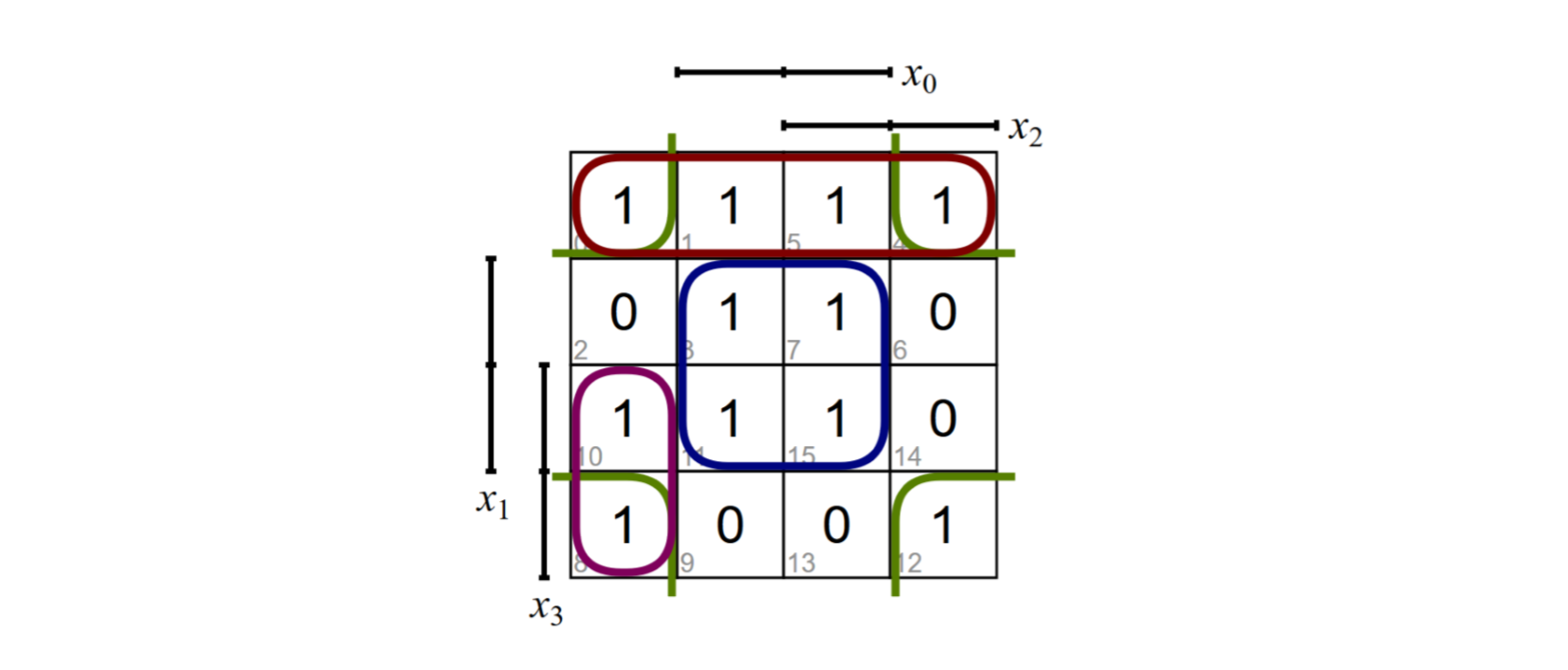
于是有:
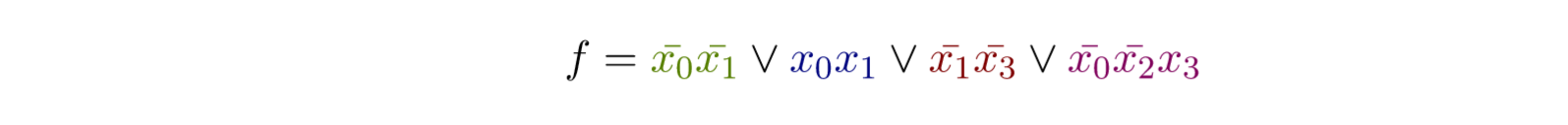
15.0.24 函数组Funktinosbündeln的优化
现在我们会了从最小DNF里得到电路图。当我们看函数组中每个函数的共同的电路元件,它经常可以组合在一起。这些经常不造在最小DNF上。为了简化函数组,我们要用编程方法。比如我们有下面2个式子:
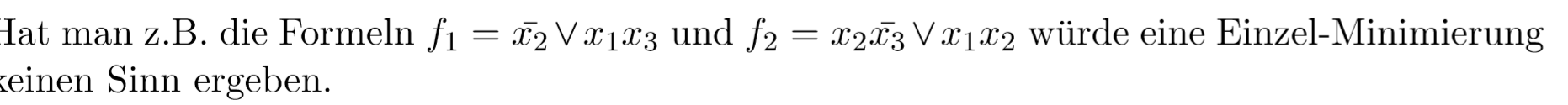
那么每个简化就没有意义。我们有它们两个的电路图:
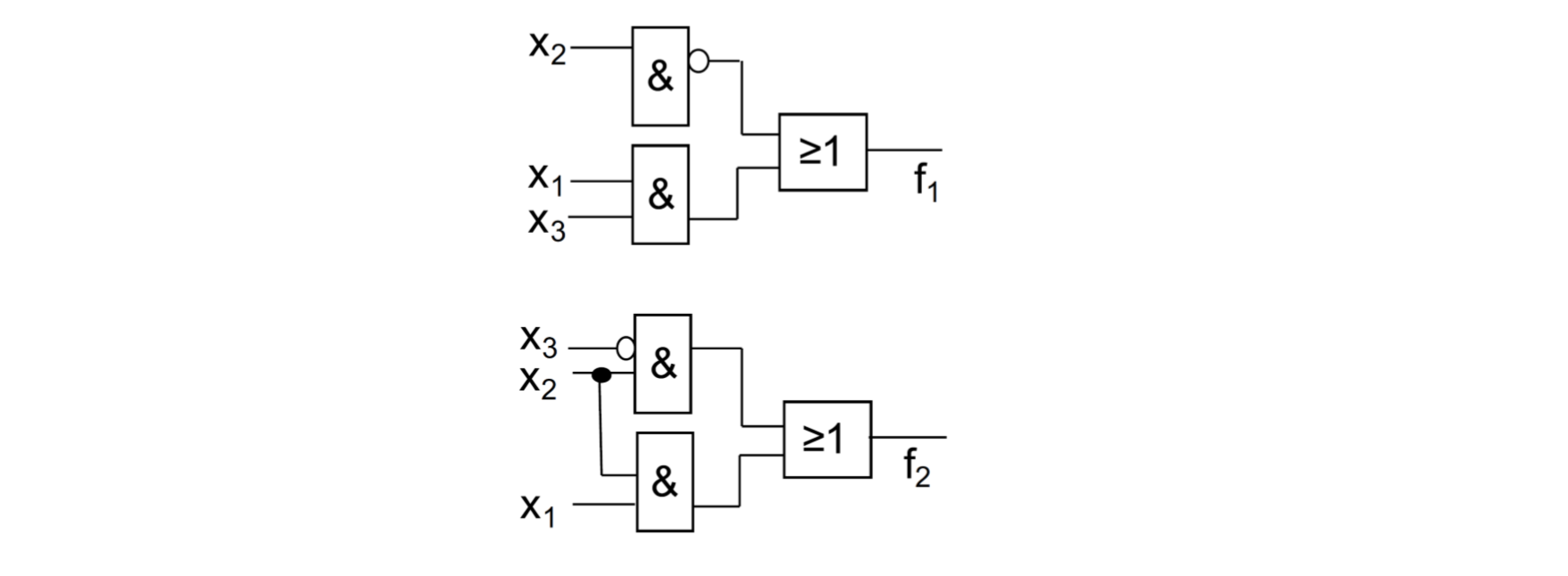
如果我们组合优化,那么可以得到下面的
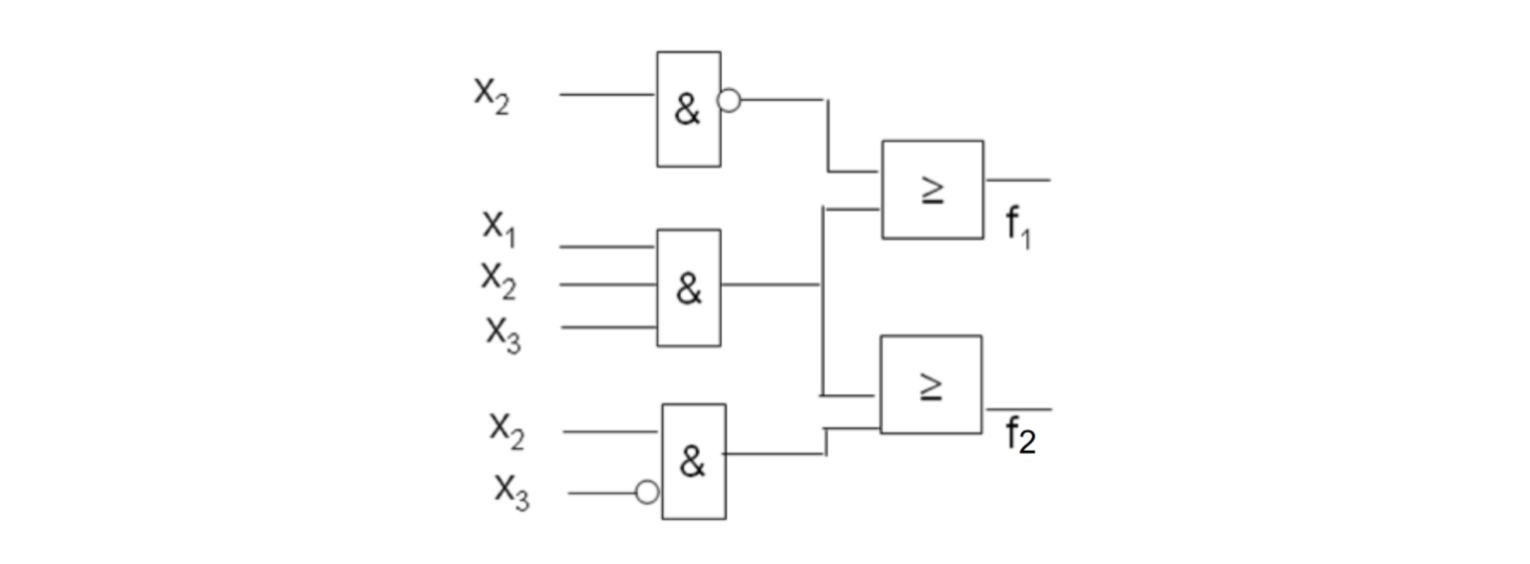
15.0.25 NAND和NOR
大部分电路技术用NAND和NOR因为它比较好实现。而且它功能齐全,可以表示所有运算。
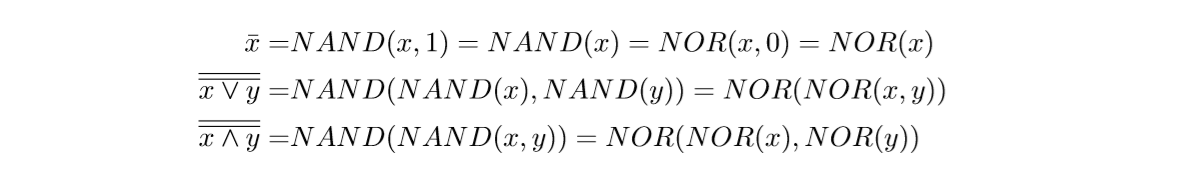
这里需要多次用摩根定律。
NAND电路网使用
最小多项式可以变成NAND/NOR的形式。它很便捷,但不是最小化的
NAND用在2bit加法器上
这是加法器的电路图,下面是变成NAND的
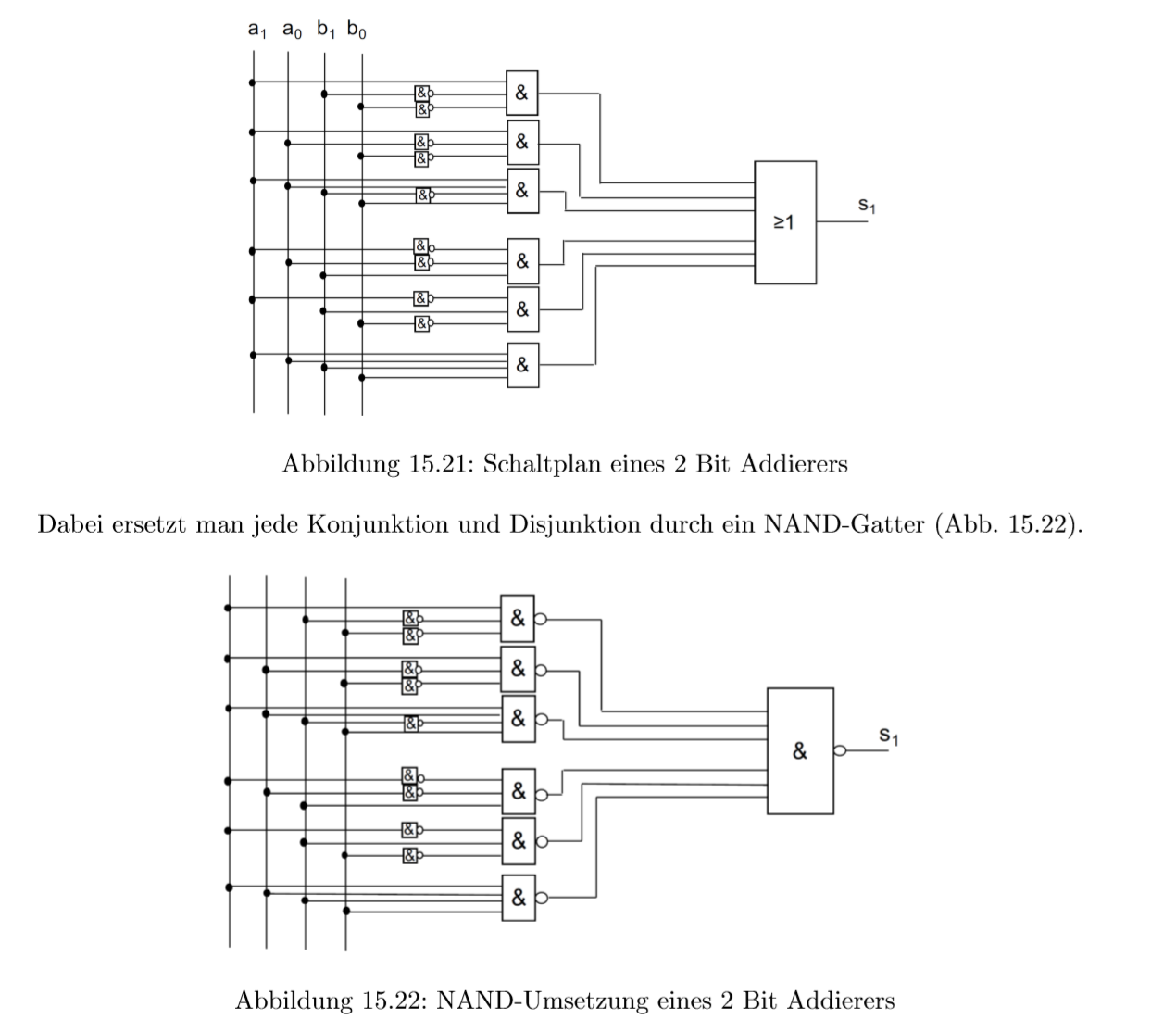
15.0.26 Hazards
每个电路信号在元件之间传播的速度有限
- 传导 -> 没10cm 需要1ns 纳秒
- 门需要0.05 ns
这个在门里的运行速度会受很多因素波动
- 温度
- 入口信号的值
- 导线的长度和种类
- 信号传递者的种类和数量
第16章 Schaltwerke
16.1 Schaltwerke的实现
在Schaltwerk里,结果Resultatsfunktion和状态函数Zustandfunktion会通过Schaltnetz实现\((\lambda,\delta)\)
每个反馈路的延时会通过\(\tau\)来实现。在某时刻\(t_{i}\)的出口和状态的值可以通过下面的函数表示 \[ a^{t_{i}}=\lambda(e^{t_{i}},q^{t_{i}-\tau}) \\ q^{t_{i}}=\delta(e^{t_{i}},q^{t_{i}-\tau}) \] 图像化展示如下:
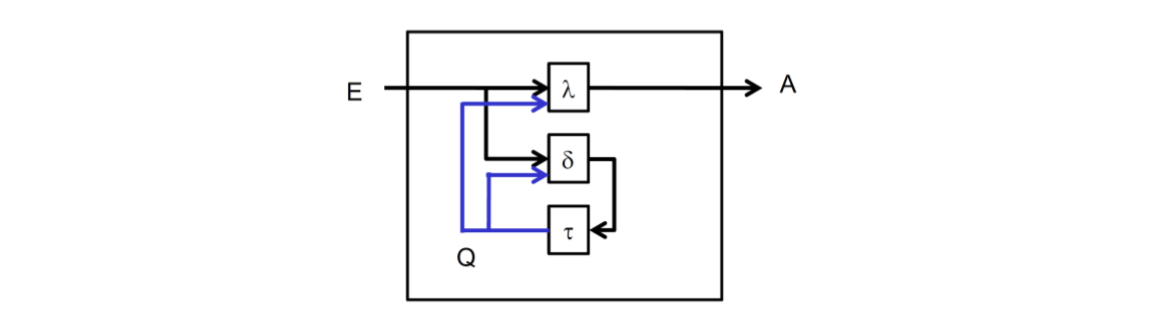
16.1.1 Schaltwerke 和有限状态机 endliche Automaten
- 有限状态机:很重要的定义
- 实际应用:状态空间大
- 两种状态机: MEALY Automaten MOORE Automaten
- \(\delta\)和\(\lambda\)的表示:状态机表和状态机图
Mealy状态机
一个有限的Mealy型状态机可以用六元的元组表示 \[ M(E,A,Q,\lambda,\delta,q) \] 这对应了下面的入口值:
- $ E=e_{1},...,e_{m}$ 入口符号的集合
- $ W=a_{1},...,a_{r}$ 出口符号的集合
- $ Q=q_{1},...,q_{n}$ 状态空间
- \(\lambda :E\times Q \rightarrow A\) 结果函数
- \(\delta :E\times Q \rightarrow Q\) 状态函数
- q: 开始状态
其中,E,A,Q都是有限的,下面是它的状态机表
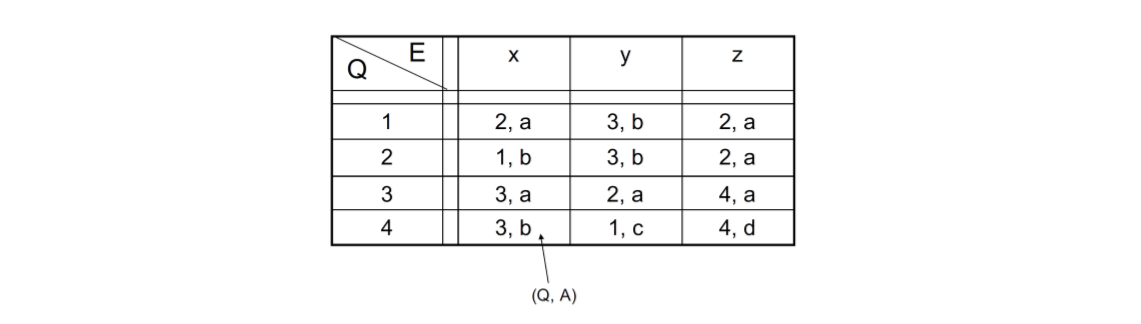
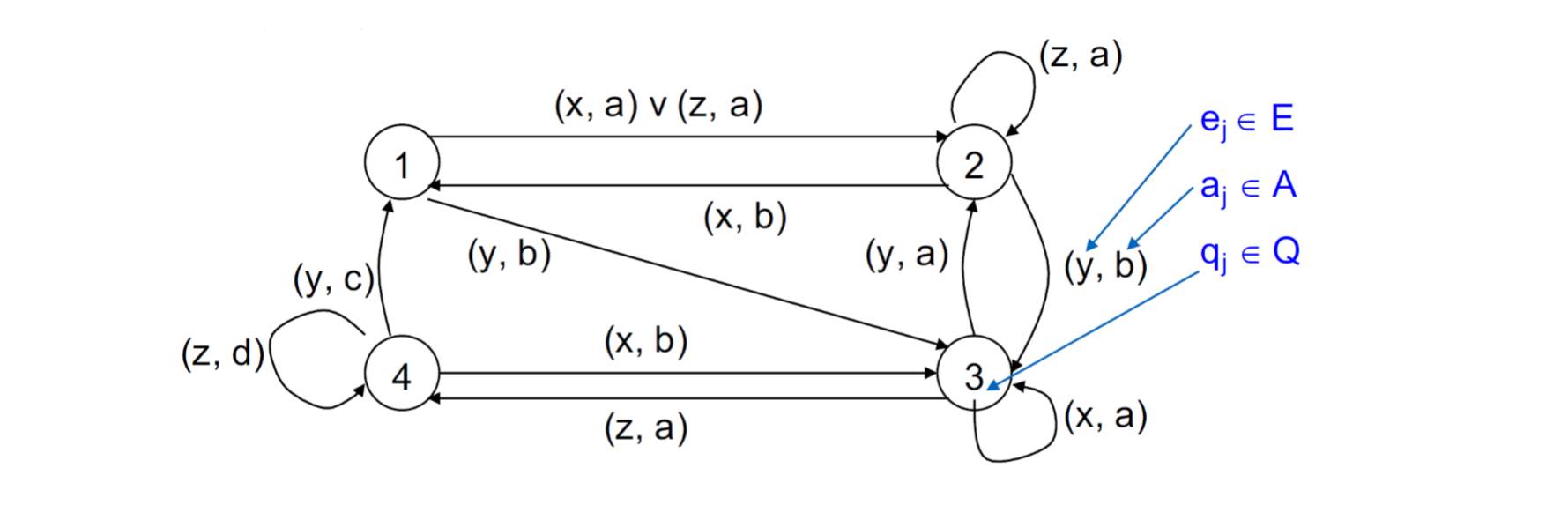
左边对应了状态,上面对应了输入值。2,a分别是会被调成2,输出a。下面是状态机图
Moore状态机
它和Mealy状态机很像。。 \[ N=(E,A,Q,\lambda,\delta,q) \] 状态机表:
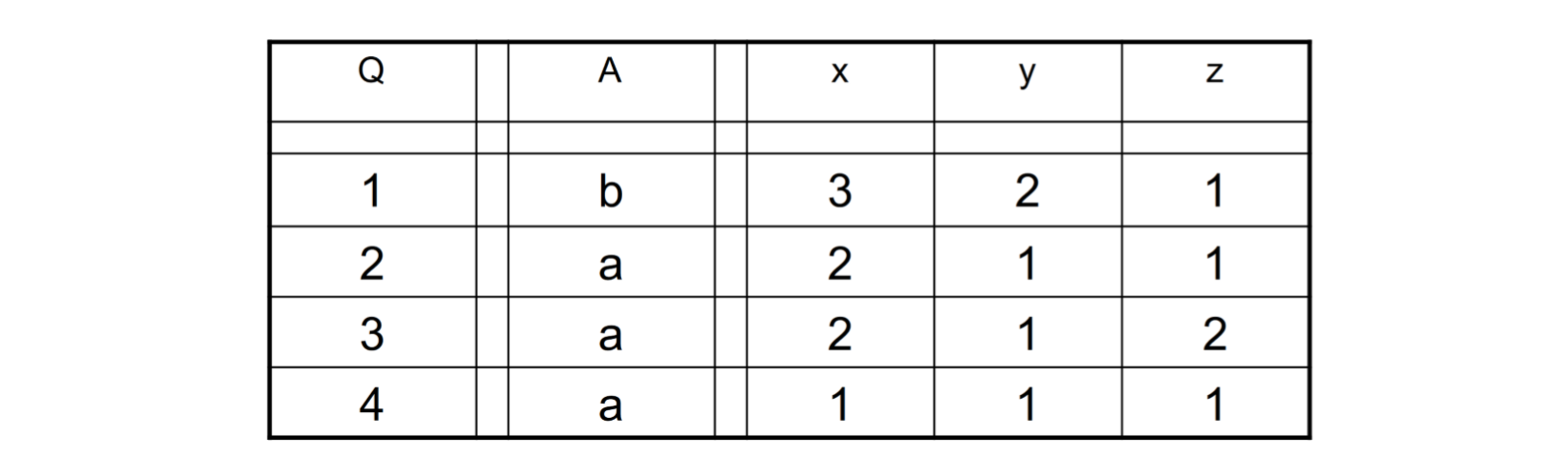
我们可以这样理解:
- 当前的状态是2,那么输出是a
- 如果读入了x,那么状态机保留状态2
- 如果读入\(y \lor z\),那么状态机的状态到1
- 这也对应了其他情况
下面是状态机图
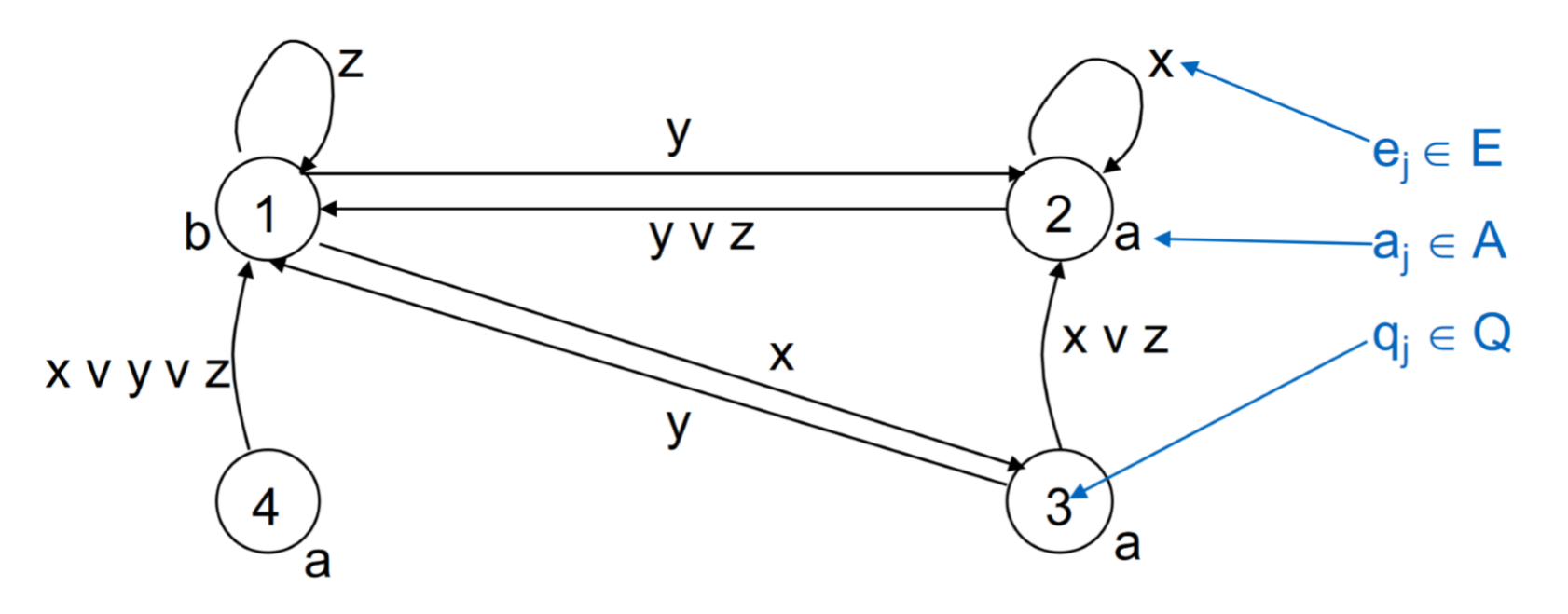
MOORE和MEALY的等价性
输入序列相同,那么输出序列也相同。所以可以从MOORE状态机变成一个MEALY状态机。反之也可以
RS触发器(Latch) ,NOR实现
下面我们看RS Latch,它有两个门Reset 和 Set。2个状态 \((q_{1},q_{2})\)和2个出口\((a_{1},a_{2})\),\(a_{2}\)是反转出口。RS触发器是用来存储单个Bit的
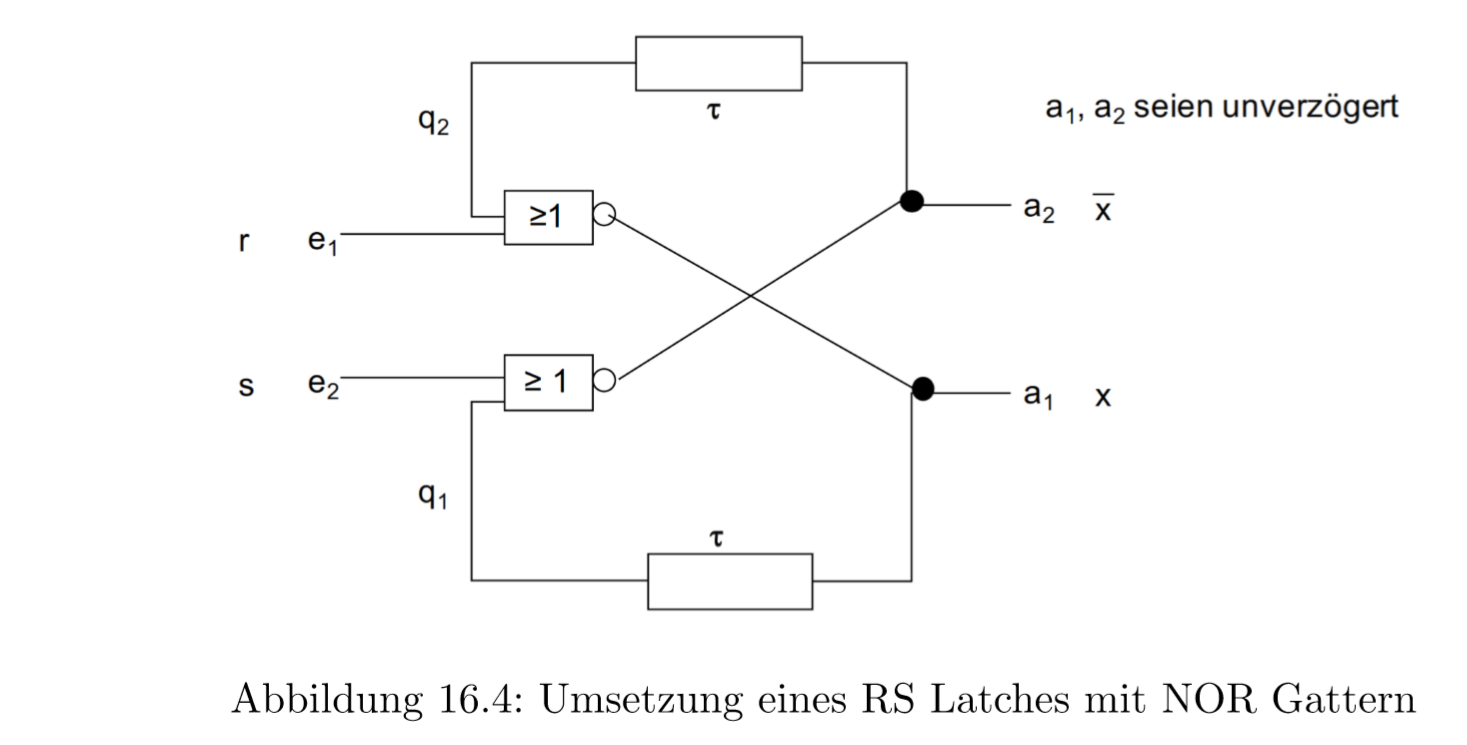
它的功能我们可以如下想象:
- 当R和S口都设为0的时候,它是安静状态(Ruhezustand),保存原来的状态
- 当S设为1的时候。\(x\)出口会被设为1
- 当R设为1的时候,\(x\)会被设为0
- \(\bar{x}\)和\(x\)总是相反的
- S=R=1这种情况不被允许
避免无定义的状态
为了避免S=R=1这个不被定义的状态,我们需要其他的逻辑。
- 我们在R入口里放一个UND门,并且和S相连
- 在S入口里放一个UND门和R相连
JK触发器(Jump and Kill)
JK触发器以RS触发器为基础。它解决了RS触发器未定义的S=R=1的状态。在JK触发器中,S=R=1会反转它的状态\(x:=\bar{x}\)
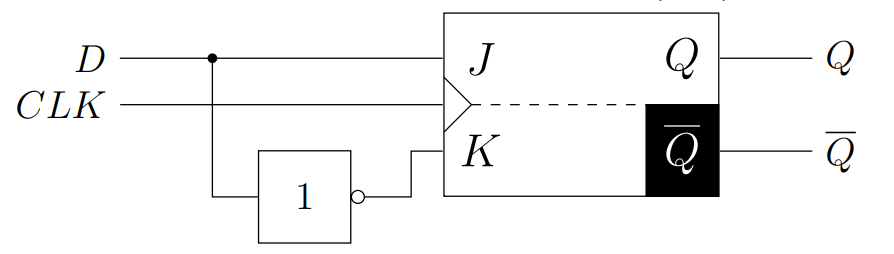
D触发器
D触发器也是以RS触发器为基础。我们只有一个D入口,还有时钟信号入口(enable)
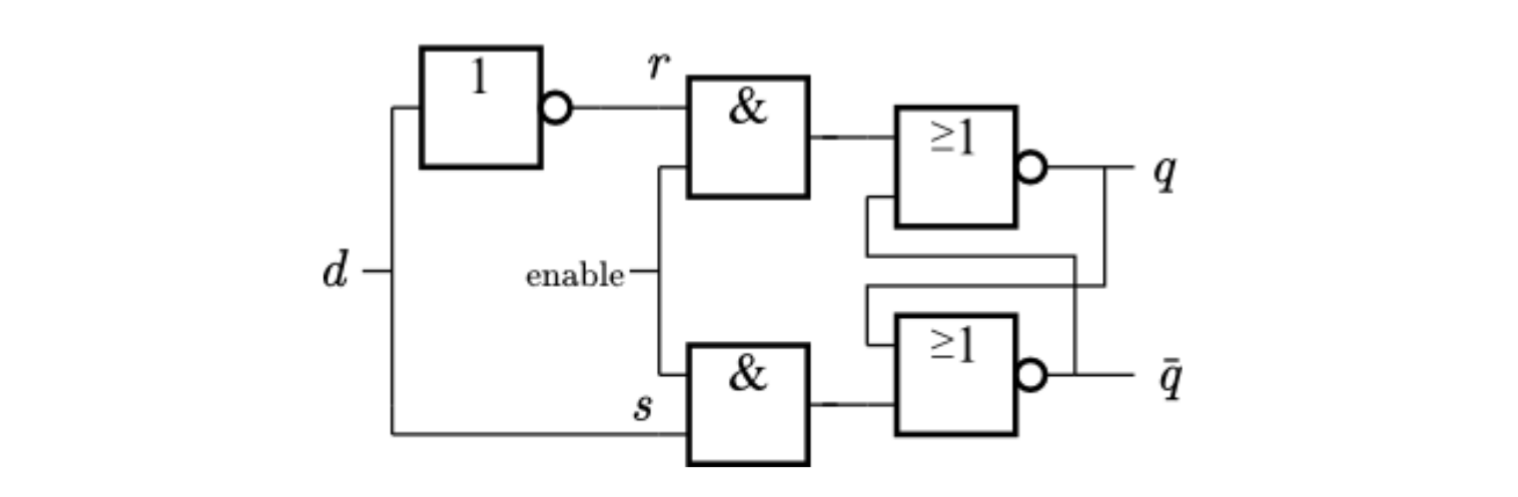
- D入口信号分成2路,上面的被反转一次进入r入口
- 下面的进入s入口
- 时钟信号控制它是否会接着往下传递
存在的困难
Schaltnetze和Schaltwerke不是开始就稳定。这个过程需要时间,由此就会产生混乱
16.1.2 平行和同步Parallelität und Synchronisation
为了定义平行,我们需要定义过程Prozess:
- 可以以时间段分割处理
- 分割把一个过程分成若干个步骤
- 过程的例子有:程序解释和在Schaltwerk里的持续的信号齿面
在一个过程里有许多分割的处理片段。
同步
解释同步之前,有必要了解上面是2个过程的异步
如果两个过程异步,那么它们没有时间先后关系。 就是两个过程是不需要协调的,\(P_{1}\)可以不用等\(P_{2}\)做完了再继续
同步化就是把两个过程同步的措施
异步过程的例子
- 两个程序跑再两台不同的计算机上
- 两个电话信号没有关系
同步过程的例子
- 铁路火车
- 两个程序的协作
函数性
一个计算是函数的,当它的输入唯一可确定并且结果是可以重复产生的。(例子:序列化的程序,它没有与其他交流)所以很多相同关联交流的异步的过程是非函数的,就算它们单独是函数的。它包括两个过程访问同一个变量
例子:相连的Schaltnetze
为了理解函数性的准则,我们看一个例子。下面两个函数的Schaltnetz连载一起是否还是函数的
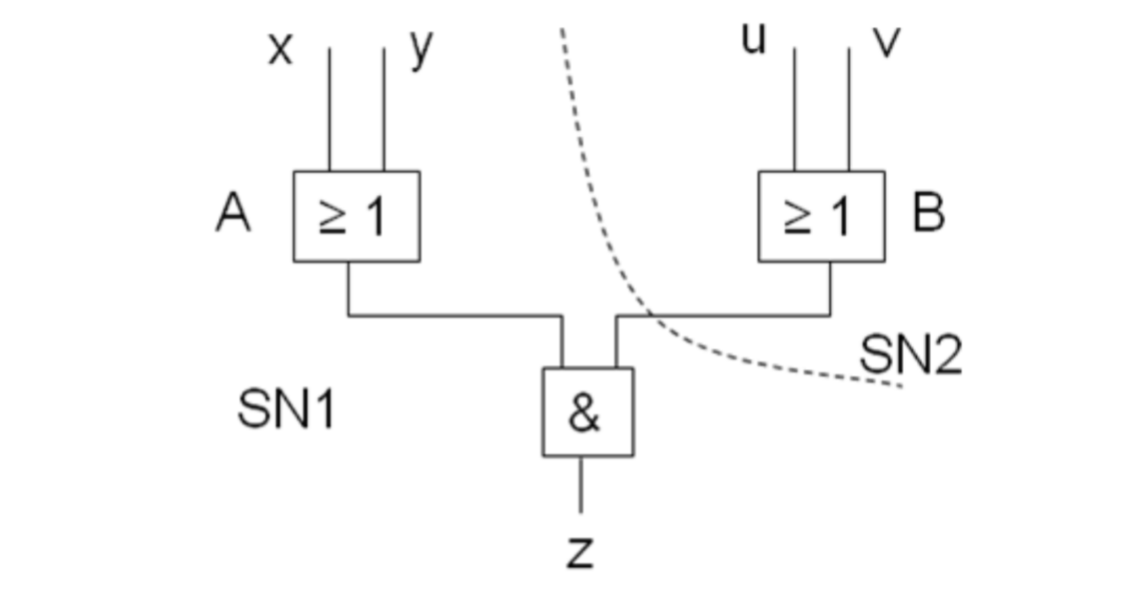
下面的事情可以发生:
- A比B慢。于是有可能发生:比如xyuv是\(0100 \rightarrow 0011\) 。那么z会成为1,当然这对于0011的输入是不可能的
- 也就是说,z可以取决于它的历史纪录,也就不是函数的
- 但是加了一段时间后,它就又会变成函数的,那么就可以想到时间脉冲来解决
通过时间脉冲来同步
为了使得Schaltnetze过了一段时间后再次协调,可以加入时间脉冲。在一个计算机里很多个过程会通过小的步骤同步。从技术上来说,几乎所有的Schaltwerk都是通过时间脉冲来同步的。
同步的Schaltwerk
一个同步的Schaltwerk就是它的反馈通过时间型号来控制。它控制中间的小状态。一个时间型号通过入口信号来控制也是有可能的
同步的Schaltwerk也有很多相对的缺点,它比较慢而且耗费高。但安全且正确的功能比它的缺点要重要很多。当一个计数器有时钟(Taktung),它被称为FlipFlop。
例子:齿轮计数器Flankenzähler
一个同步的Schaltwerk的例子是所谓的齿轮计数器。它是如下定义的:
- 要求的是初始状态e=0的Schaltwerk
- 今后应该由开始的0推导而出
- 每第4个齿轮应该输出1
一个齿轮是从0到1的跳转或者从1跳转至0
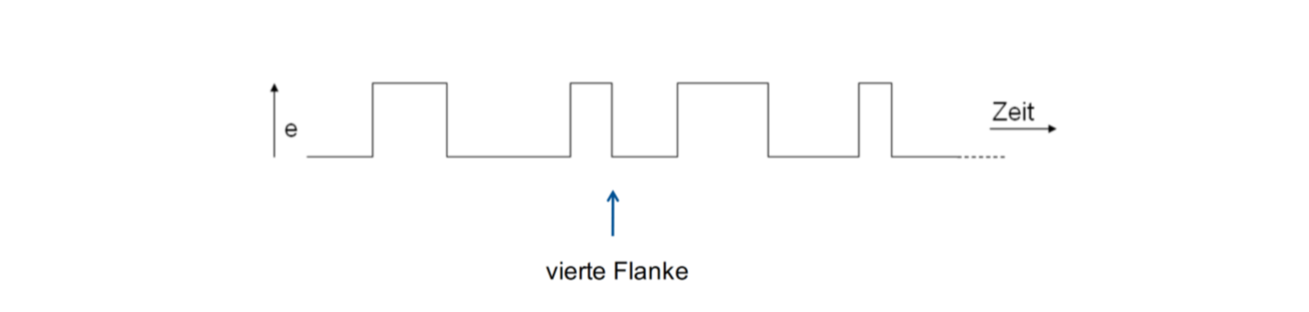
16.1.3 Taktung
FlipFlop
加入时钟控制型号的Latch
RS-Flipflop
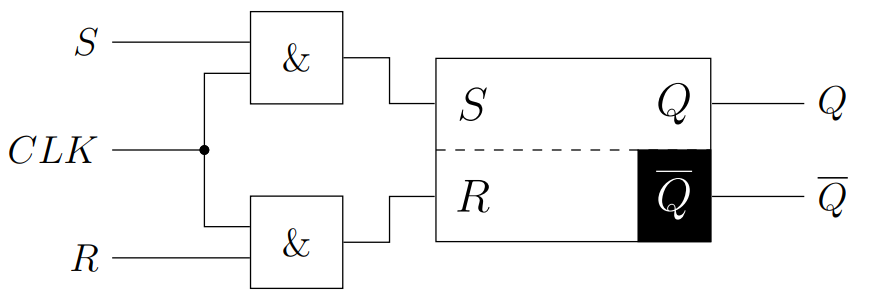
JK-FlipFlop
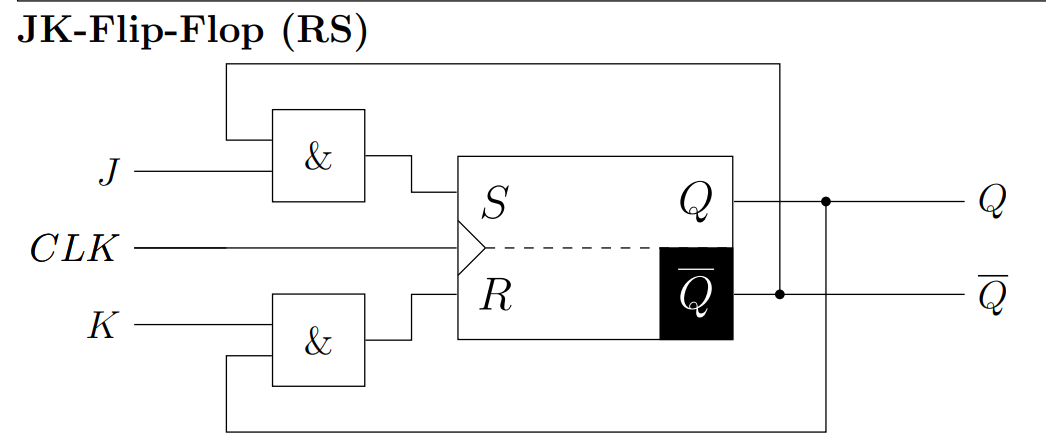
D-FlipFlop
Master-Slave-FlipFlop
为了避免信号冲突
第18章 VHDL
VHDL是Very-High-Speed Integrated Circuits Hardware Description Language.
VHDL基本概念
- Entity -> 外部接口
- Architecture -> 实现功能
之后VHDL还有变量和信号
- Variablen 是局部的没有延时的变量用\(:=\)来赋值
- Signale 可以是全局的,有延时的。用\(<=\)来赋值
数据类型
- 标量类型,写在Entity里
1 | A: in bit; |
- 组合信号类型,写在Entity里
1 | D: in bit_vector(0 to 7) |
除了这些以外,还有一些有很多值可能性的类型
- std_logic
它除了0,1还有其值的可能性

- std_logic_vector
一个由许多std_logic组成的vector
1 | byte: in std_logic_vector(7 downto 0) -- 定义 |
Entity
Entity是一个接口,里面定义了输入输出信号。每个信号都有类型
1 | entity addierer is |
Architecture
1 | architecture addop of addierer is |
在begin之前也可以定义中间变量,信号
VHDL中的计算
when 和 else
1 | architecture v1 of tasterbinaer is |
process
用于表示时钟信号关连的结构
1 | architecture v1 of tasterbinaer is |
第19章 存储器
19.1 存储器Speicher
存储器很重要
- 它包含很多程序和数据
- 很多指令需要对存储器的直接存取
19.1.1 内存墙The Memory Wall
存储器的速度比CPU慢很多
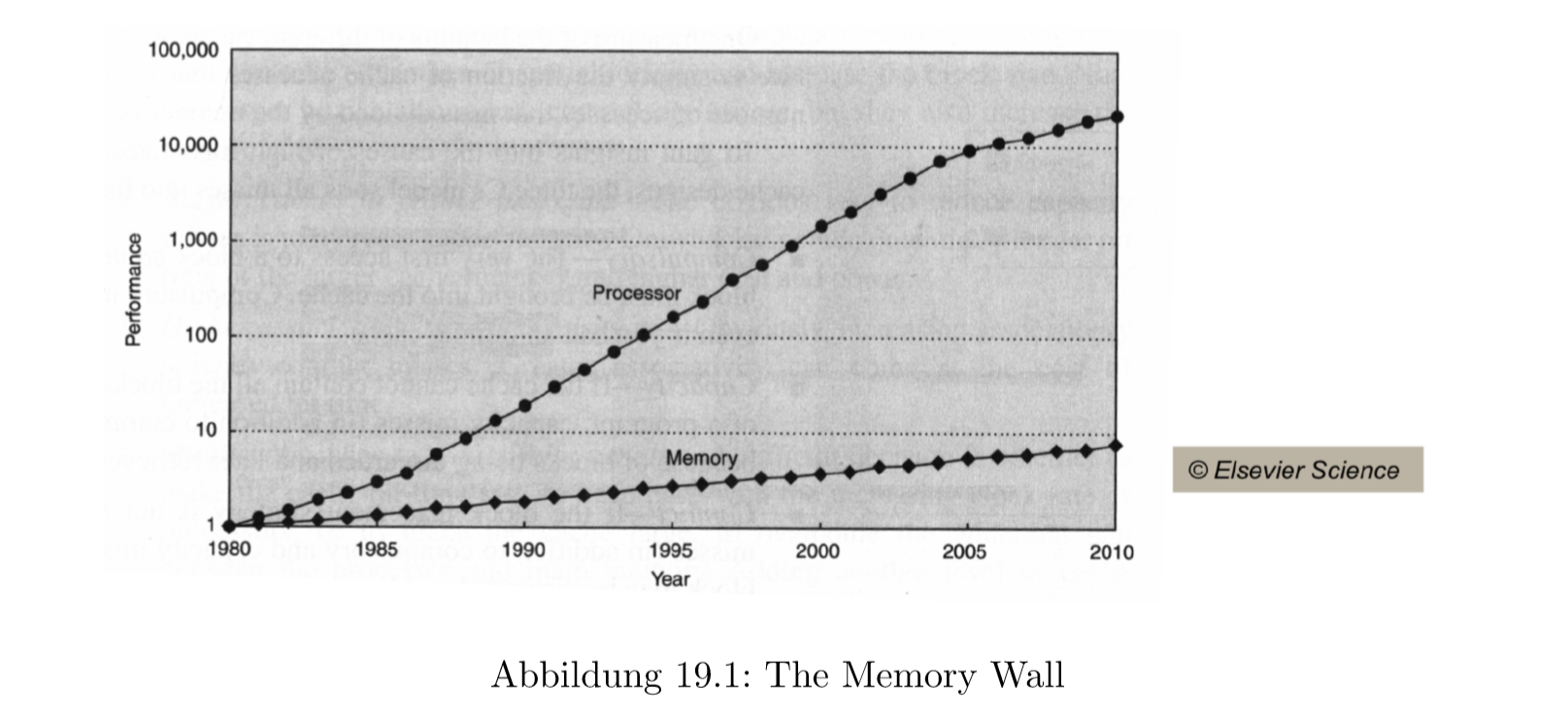
通过这个增长趋势可以出现下面的困难
- 那些对存储器存取的指令需要等待
- 处理器会经常空运作
- 处理器没有完全利用好
19.1.2 半导体存储器Halbleiterspeicher
我们先来看存储器的不同种类和技术。经典冯诺依曼存储器是RAM。Ramdom Access Memory在这个存储器上由很多存储单元Speicherzelle。除此之外还有很多其他的:
- Read-Only Memory(ROM) 嵌入式的eingebaut
- Programmable Read-Only Memory (PROM) 像ROM一样除了只能编程一次
- Eraseable Programmable Read-Only Memory(EPROM)像PROM可以通过UV光把里面的内容清除再次编程
- 暂时的存储器 -> 静态RAM(SRAM-FlipFlops),动态RAM(DRAM)
之后我们介绍这些暂时的存储器Flüchtigen Speicher
SRAM
SRAM全名Static Random Access Memory。它像触发器一样
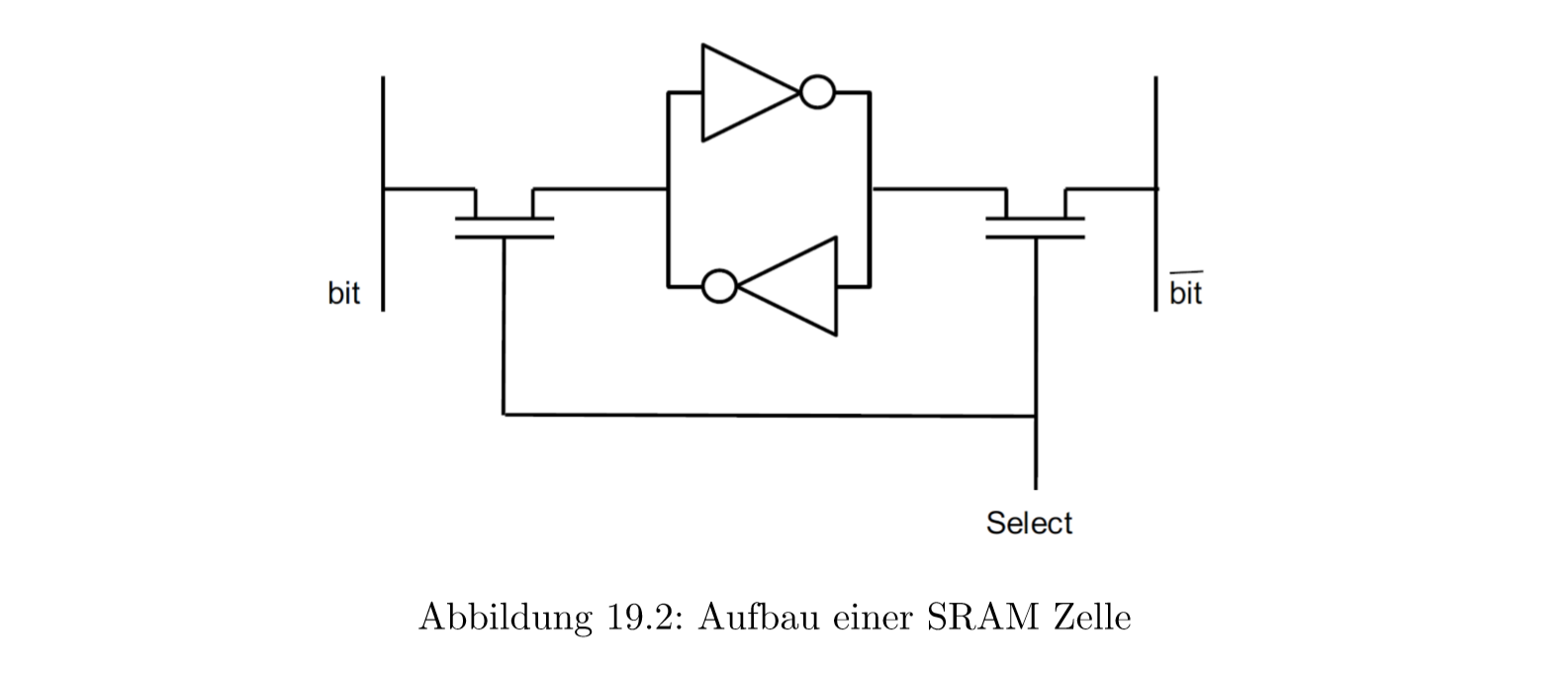
我们可以很好看到,单个Bit是怎样存储的。有两个晶体管,它手Select门影响。也就是它只会当Select=1的时候进行存取,否则晶体管就关闭
它的工作原理是这样的,第二个存储片段是倒相器。这就使得右边是\(\overline{bit}\)左边是\(bit\)。这种存储器是用在寄存器和缓存上面的
存储的时候bit 设位1,\(\overline{bit}\)设为0。读取的时候bit设为1,\(\overline{bit}\)设为1。根据电压差可以判断出内部存储的bit。
- 优点:
- 通电就有值
- 很快
- unempfindlich
- 缺点:
- 相对很大而且很贵
- 能耗高
DRAM
DRAM全名 Dynamic Random Access Memory。和SRAM不一样。和SRAM不一样,DRAM是由电容制造的。此外还有一个选择导线和Bit导线
Cache

Cache的结构
Cache由若干个Cache Set(Cachemenge),每个Cache Set由很多Cachezeilen构成。
Index是用来表示第几个Cache Set的,长度是\(log_{2}|CacheSet|\)
1个Cache Set 由n个Cachezeile就是n-fach assoziativ
offset表示一个Zeile中间的具体某个Byte的,长度是\(log_{2}|Cachezeile|\)
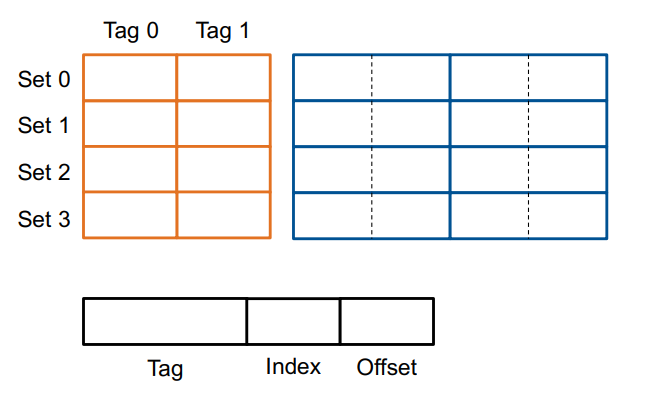
Cache寻址优缺点

Cache 分类

Cache 优化
计算机性能
Roofline Modell
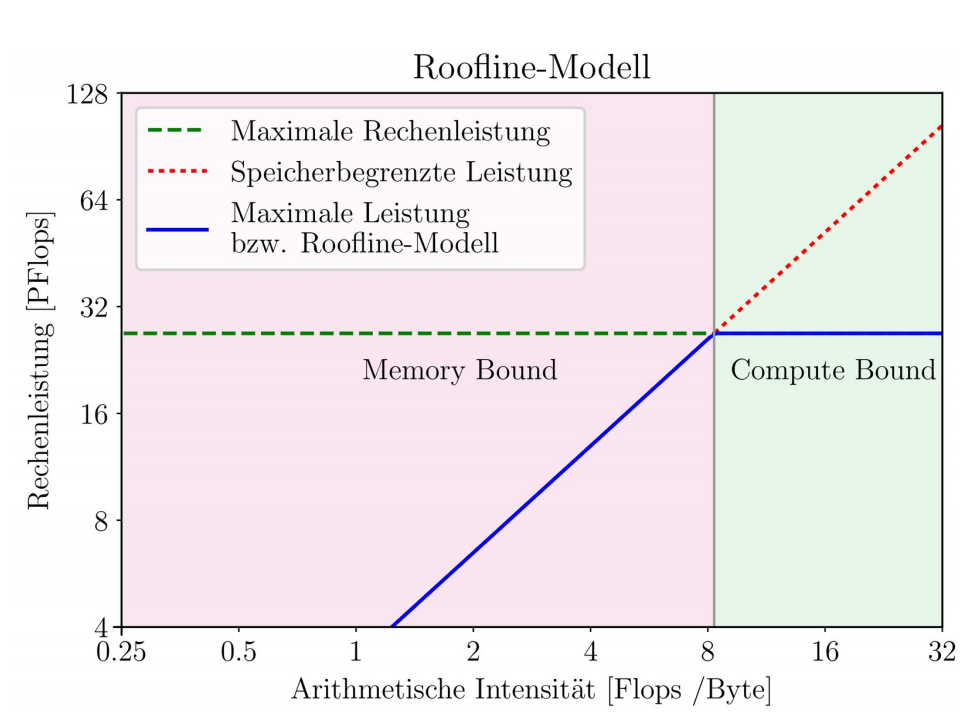
Praktikum
Week 1
64bit寄存器
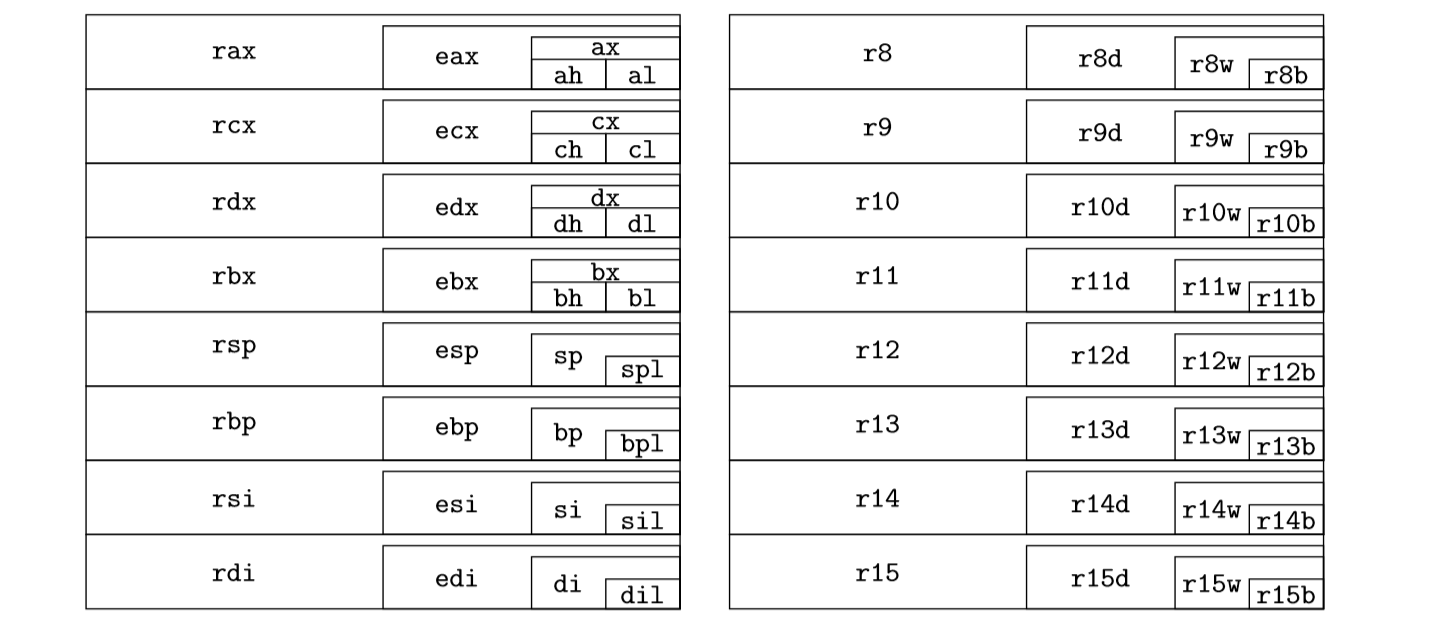
Immediate-操作符
64位宽的常数只能写在mov指令中,对于32位常数
连接ssh
1 | ssh fan@lxhalle.in.tum.de |
反汇编指令
1 | objdump gauss -d -M intel | less |
优化级别
O1,O2, O3, Ofast, Os, Og
命令是:
1 | gcc -O2 -o gaussO2 gauss.c |
存储区域
1 | objdump -wh gauss |
上面这个指令可以看到Speicherbereiche
.text: 程序代码
.rodata:全局变量,常数(readonly)
.data: 初始化的全局变量(read-write)
.bss: 0初始化的全局变量
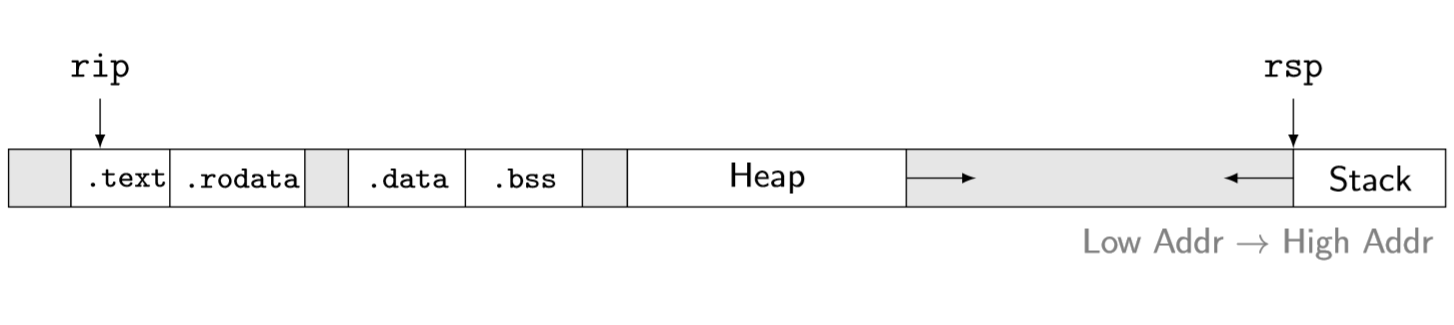
在堆中申请内存
1 | char* p = malloc(256 * sizeof(char)); |
补码
取反+1

Week2
指令
MOV r/m, r — r, r/m — r/m, imm
r/m/imm的意思是
- r = 寄存器
- m = 内存指针 (Speicherreferenz, z.B. [rax]) I
- imm = 常数(Zahl, die direkt in die Instruktion codiert wird)
1 | mov eax, 4 |
PUSH r/m : Legt ein Element auf den Stack I
POP r/m : Nimmt ein Element vom Stack
ADD r/m, r — r, r/m — r/m, imm I
SUB r/m, r — r, r/m — r/m, imm
MUL r/m
MUL的操作数是 rax 和传入的参数,存在 rdx:rax里
IMUL是带符号的乘法
DIV r/m
除法要先清空 rdx
rax 是商, rdx 是余数
Jump 1b/f
b 是backwards 往回跳,f是forwords,往前跳
C语言编译过程
gcc编译时,文件扩展名为.S和.s的区别是,.S支持预处理,而.s不支持。
gcc编译一般分为四个阶段,分别是预处理、编译、汇编、链接。
预处理
1 | gcc -E main.c -o main.i |
编译预处理的文件
1 | gcc -fno-asynchronous-unwind-tables -S main.i |
汇编
汇编的作用是将汇编代码转成对应的二进制形式的cpu指令:
1 | gcc -c main.s |
链接
链接的作用是把代码之间的引用关系关联起来,最终生成一个完整的程序:
1 | gcc main.o lib.o -o main.exe |
由上可见,文件扩展名为.s的文件其实就是汇编代码文件。
快速编译
1 | gcc main.c strlen.S -o main.exe |
在汇编语言中用printf调试
现在一个c文件中写好自己的print函数
1 | void my_print(int a) { |
然后再汇编.S 文件中加入 .extern my_print
1 | .intel_syntax noprefix |
用的时候,把要输出的变量放到ecx里,然后调用程序即可
浮点数表示
无符号
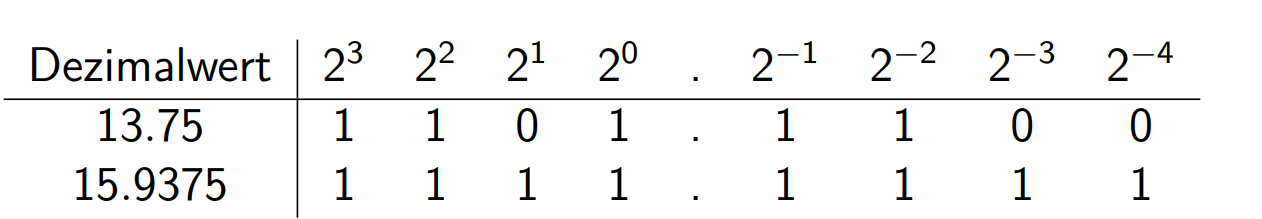
带符号
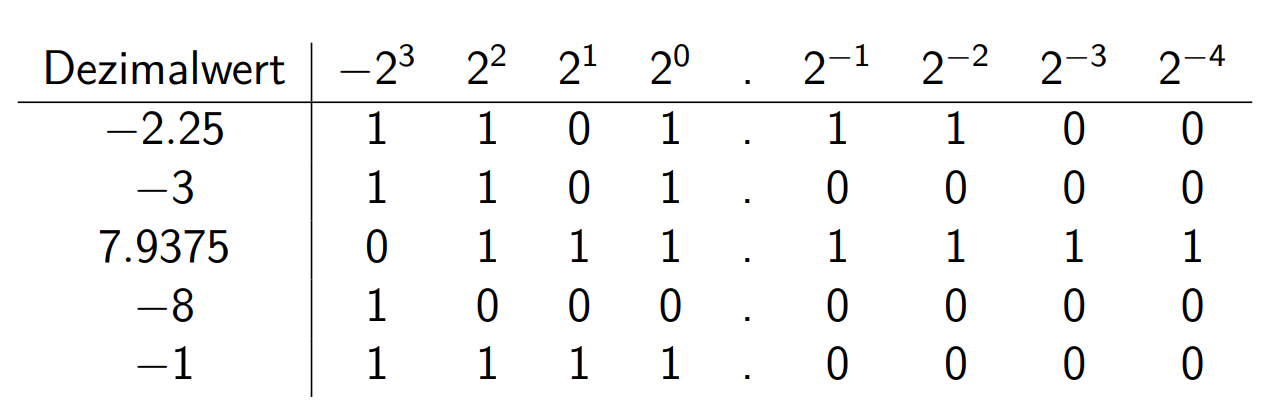
快除常数
根据这个公式,可以把除法转换成乘法和位运算
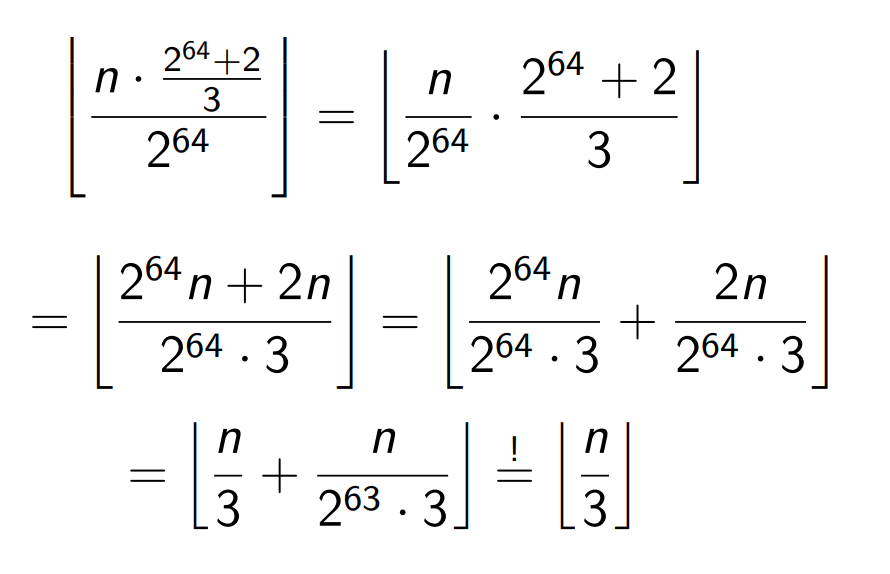
1 | div3 : |
函数传参
传参顺序是
1 | rdi, rsi, rdx, rcx, r8, r9 |
第7个参数以后用栈传递
1 | rsp+0x8, rsp+0x10 |
返回值在 rax 里
调用约定
Callee-saved:
rbx, rbp, rsp, r12 - r15就是函数开始和函数结束的值要一样
caller-saved:
rax, rcx, rdx, rdi, rsi, r8 - r15
Week3
系统调用
- 在操作系统里的调用,如输出在终端,读取数据,申请内存
调用约定
- 每个系统调用对应一个index, 在
rax里 - syscall 覆盖
rcx, r11 - 返回值在
rax里 - 参数在
rdi,rsi,rdx,r10,r8,r9里
一些系统调用
exit(60) 结束一个进程, exit_group(231)
结束所有线程
read(0) write(1) open(3)
close(3) 文件读写
文件读写
1 |
|
系统参数
1 |
|
Week4
使用gcc调试
使用 -Wall -Wextra 可以获得更多报错,警告信息
1 | gcc -o strange -O0 -Wall -Wextra strange.c |
Week5
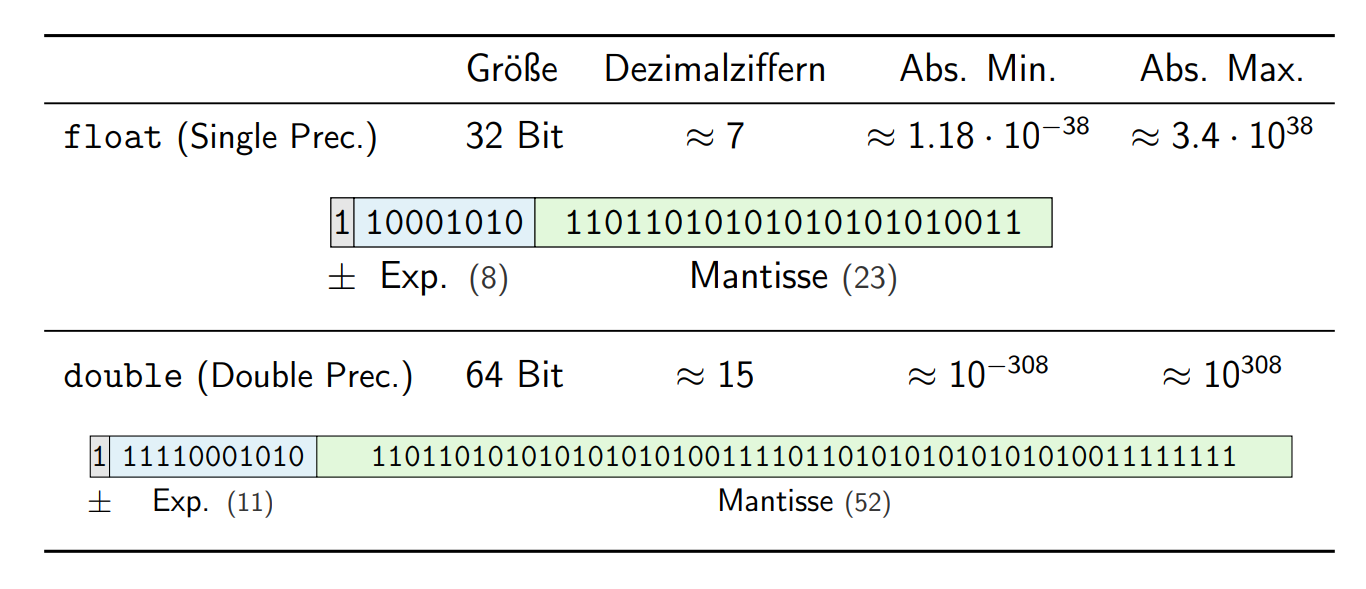
浮点数
计算
\[ \text {SignBit} \times \text {Mantisse} \times 2^{\text {Exponent}-\text {Bias}} \]
SSE
128位寄存器 xmm0 - xmm15 ,
它可以32bit 或64bit 同时计算

它可以用来计算浮点数
指令
- XOR异或:
pxor dst, src
xorps xmm1, xmm1 全部异或
从内存读取浮点数
movss dst, src比如
movss xmm0, [rip + .Lconstx]movd和movq可以从普通寄存器拷贝过来cvtsi2ss xmm1, r8把带符号的寄存器或内存拷贝为单精度浮点数cvtss2si r8, xmm1把float拷贝为整数加法:
addss dest, src减法:
subss dest, src乘法:
mulss dest, src除法:
divss dest, src开平方根:
sqrtss dest, src比较:
ucomiss op1, op21
2
3
4
5
6cmpFloat:
ucomiss xmm1 , xmm0
jp .Lunordered ; xmm0 or xmm1 NaN
jb .Llesser ; xmm1 < xmm0
ja .Lgreater ; xmm1 > xmm0
je .Lequal ; xmm1 == xmm0调用约定
调用约定
返回值:xmm0
参数: xmm0 - xmm7
比如:
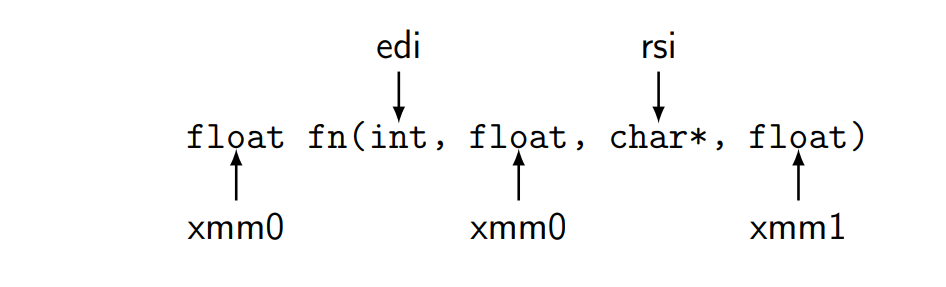
要调用它:
1 | ex : |
Week6: SMID
SISD: Single Instruction Single Data Stream
之前的操作都是固定长度的(byte, word, dword, qword)操作, 如果要操作数组就要遍历
SIMD: Single Instruction Multiple Data Stream
指令
加法
paddd xmm1, xmm2/m128 32位加法
每次加4个32位的数
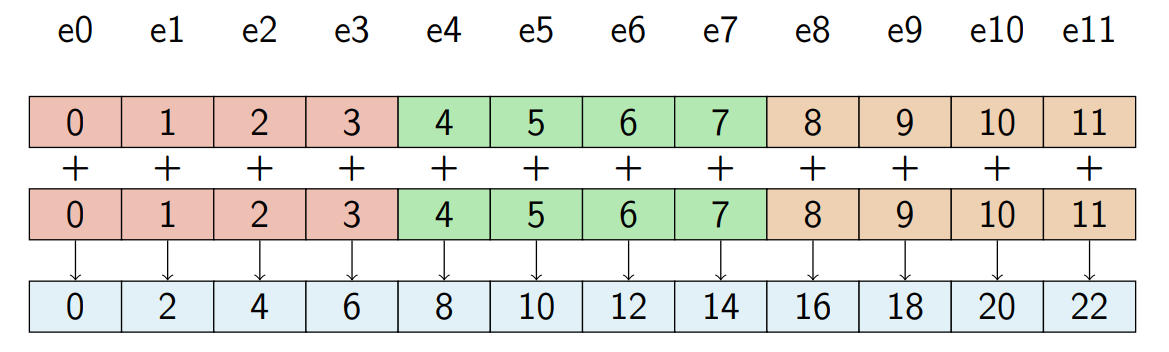
paddb xmm1, xmm2/m128 1byte加法
paddq xmm1, xmm2/m128 64位加法
每次加2个64位的
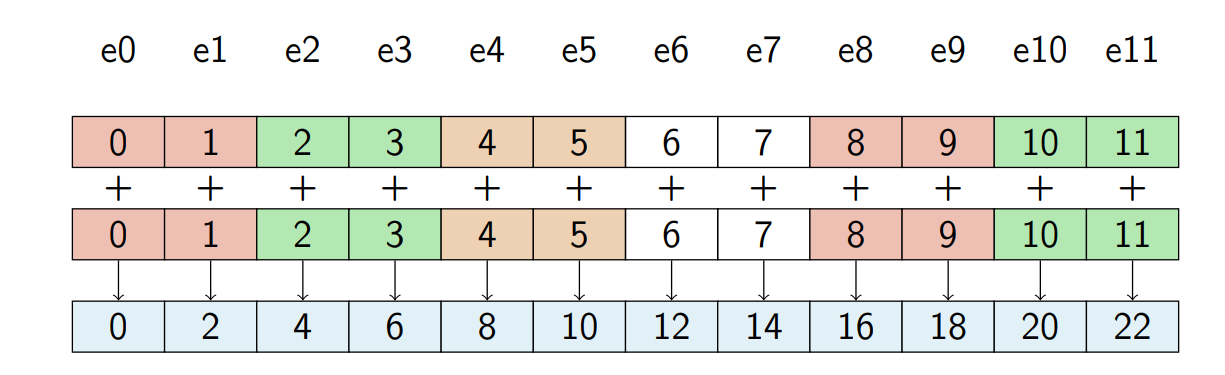
addps xmm1, xmm2/m128 加4个float
addpd xmm1, xmm2/m128 加2个double
pshufd xmm0, xmm0, 0x00 把低位的复制成高位的
1 | haddps xmm0 , xmm0 ; 把xmm0中4个32bit加起来放在低位 |
对齐Alignment
要求16bit对齐的指令
movaps xmm/m128 xmm/m128 复制4个float
movups xmm/m128 xmm/m128 在不对齐的情况下复制
4个float
AVX寄存器
位宽256bit
ymm0 - ymm15
它支持3元运算,如 \(a = b + c\)
指令
vaddps xmm/ymm, xmm/ymm, xmm/m128/ymm/m256 [1] = [2] +
[3]
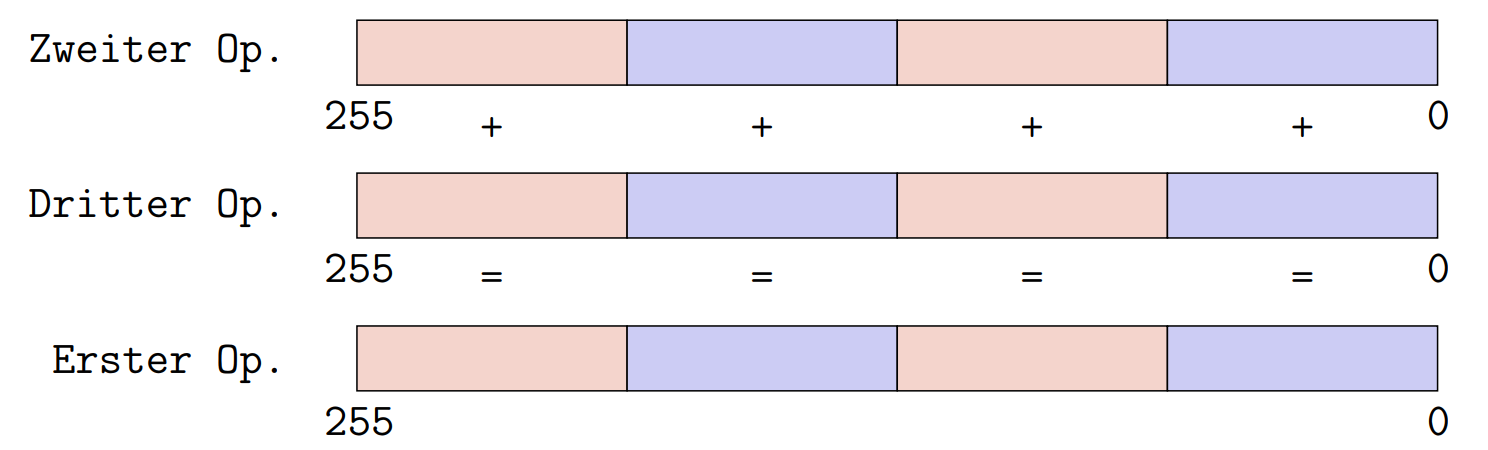
vmovsd xmm, xmm, xmm
合并2个64bit浮点数到1个xmm寄存器
vbroadcastss xmm/ymm, xmm/m32
广播一个32bit操作数到一个xmm里
vpsllvd xmm/ymm, xmm/ymm, xmm3/m128/ymm/m256
每32位左移
vpsrlvd xmm/ymm, xmm/ymm, xmm3/m128/ymm/m256
每32位右移
vpsravd xmm/ymm, xmm/ymm, xmm3/m128/ymm/m256 每32位
arithmetric 右移
vzeroall ymm ymm 清零
vzeroupper ymm ymm 上128bit清零
BMP文件读写
1 |
|
 wechat
wechat alipay
alipay