
人工智能
人工智能
Intelligent Agent
- 通过传感器(sensors)察觉周围环境
- 执行器(actuators)根据环境做出反应
Agents interact with environments through actuators and sensors.
Percept sequence
感知的序列
Agent function
根据感知的序列映射出一个动作
可以选择列表(Tabular Agent Function)或者写程序(Agent Program)。 表格可以在理论上很好的描述(Expressiveness)一个agent的行为,但是缺乏实践意义(Practicality)
Agent program 是agent function的实际实现(practical implementation)
Rational Agent
理想的agent, 一直做"正确的"事情
- 显然的表现评估法则(performance measure)并不总有
- 设计者需要找到一个可接受的评估法则
对于一个感知序列,一个理想的agent需要选择行动,使得它在给定的知识范围的表现期望最大化
Omniscience agent
知道它行为的最终结果(实际不可能)
Learning学习
Rational agent 可以通过它的感知学习,改进它的知识
Autonomy
一个 rational agent 是autonomous, 如果它相比已经获得的知识,更加依赖于新获得的知识
Task Environment
我们用PEAS来描述
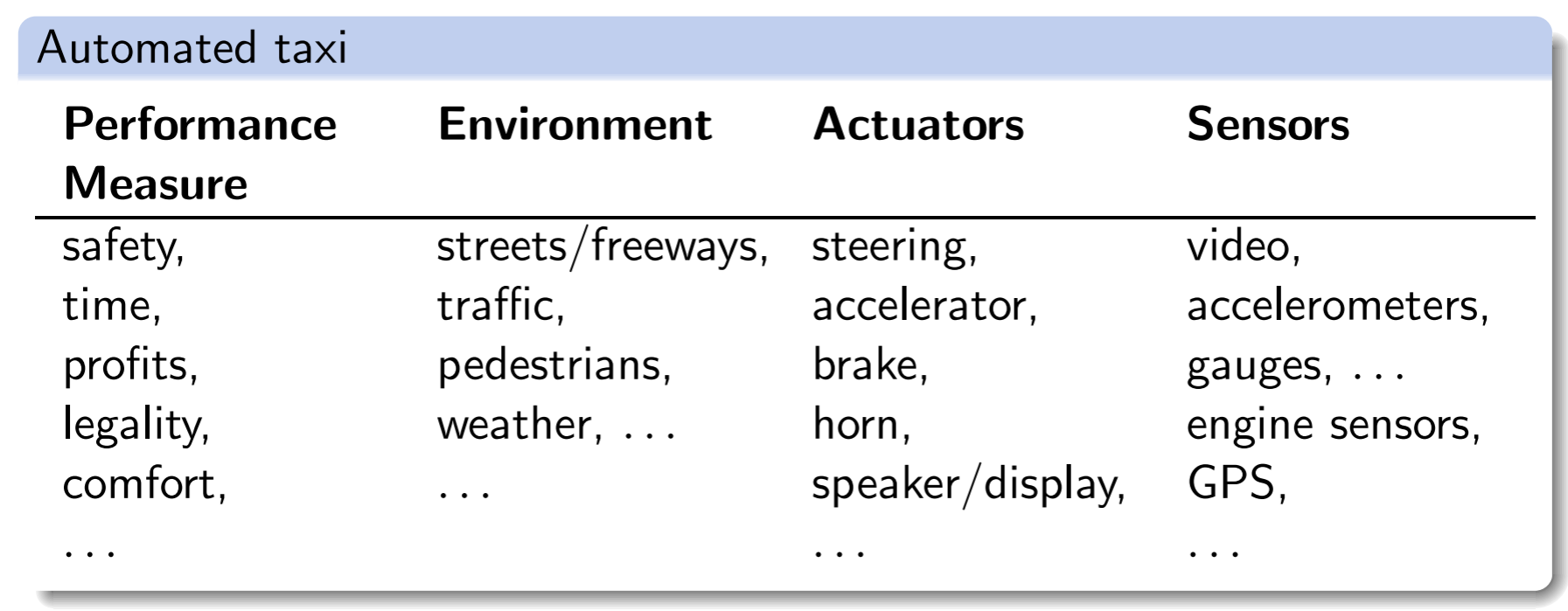
Fully observable/partially observable
一个环境是可全部观测的,若agent可以检测到环境完整的状态,否则就是部分可观测
Single-agent/multi-agent
一个环境是multi agent环境,若它包含多个agent
Deterministic/stochastic
有确定性若下一个状态完全取决于当前状态
Episodic/sequential
episodic若在一个时期(episode,机器人感知和做出行为的时期)的行为不会影响到下一个时期
discrete/continuous
分为状态的离散/连续和时间的离散/连续
static/dynamic
如果环境的变化只基于agent,那么他是static的
known/unknown
known:如果agent知道行为结果或者结果的概率
Agent Types
- simple reflex agent
- reflex agents with state
- goal-based agents
- utility-based agents
simple reflex agents
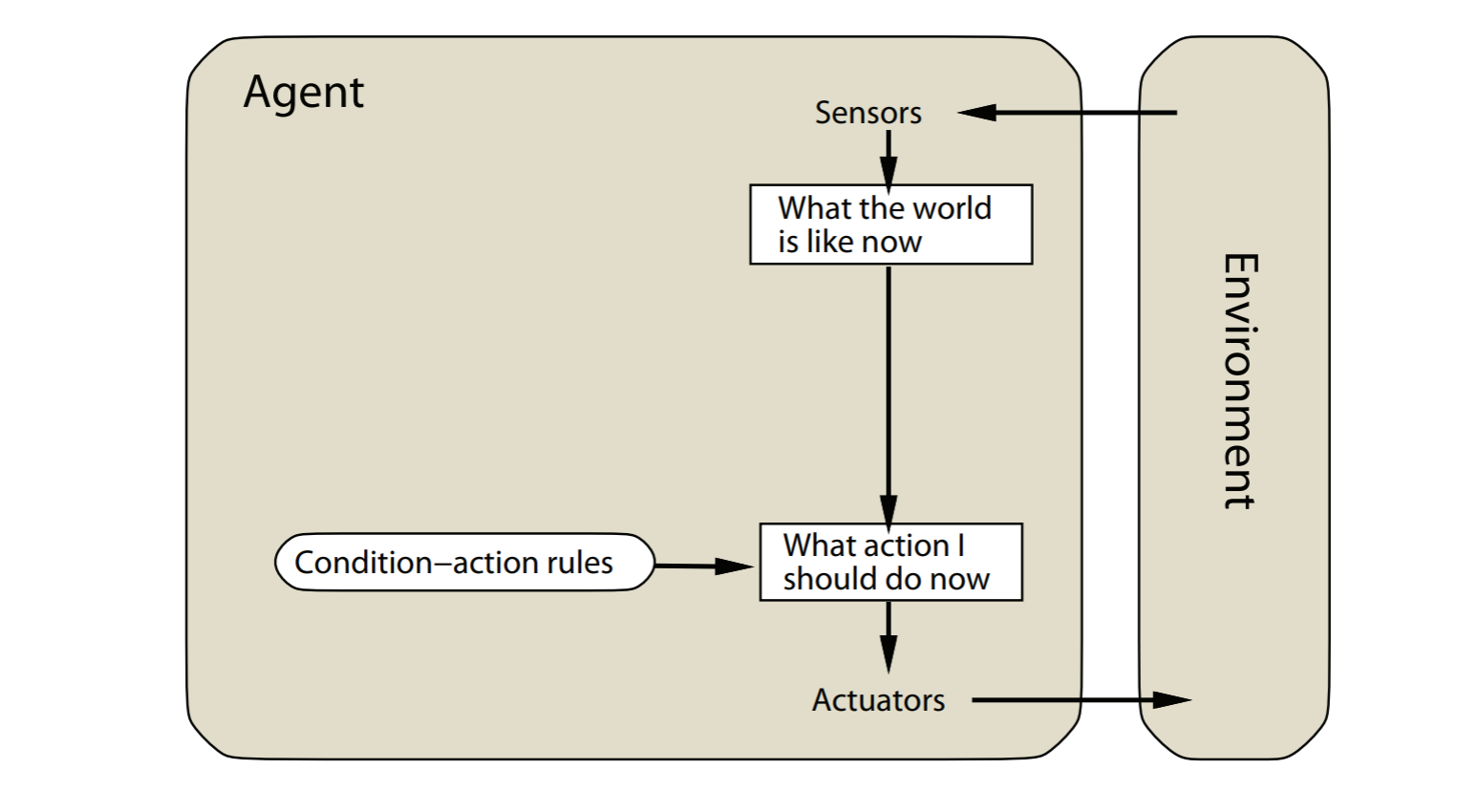
agent的决定基于当前的感知
model-based reflex agents
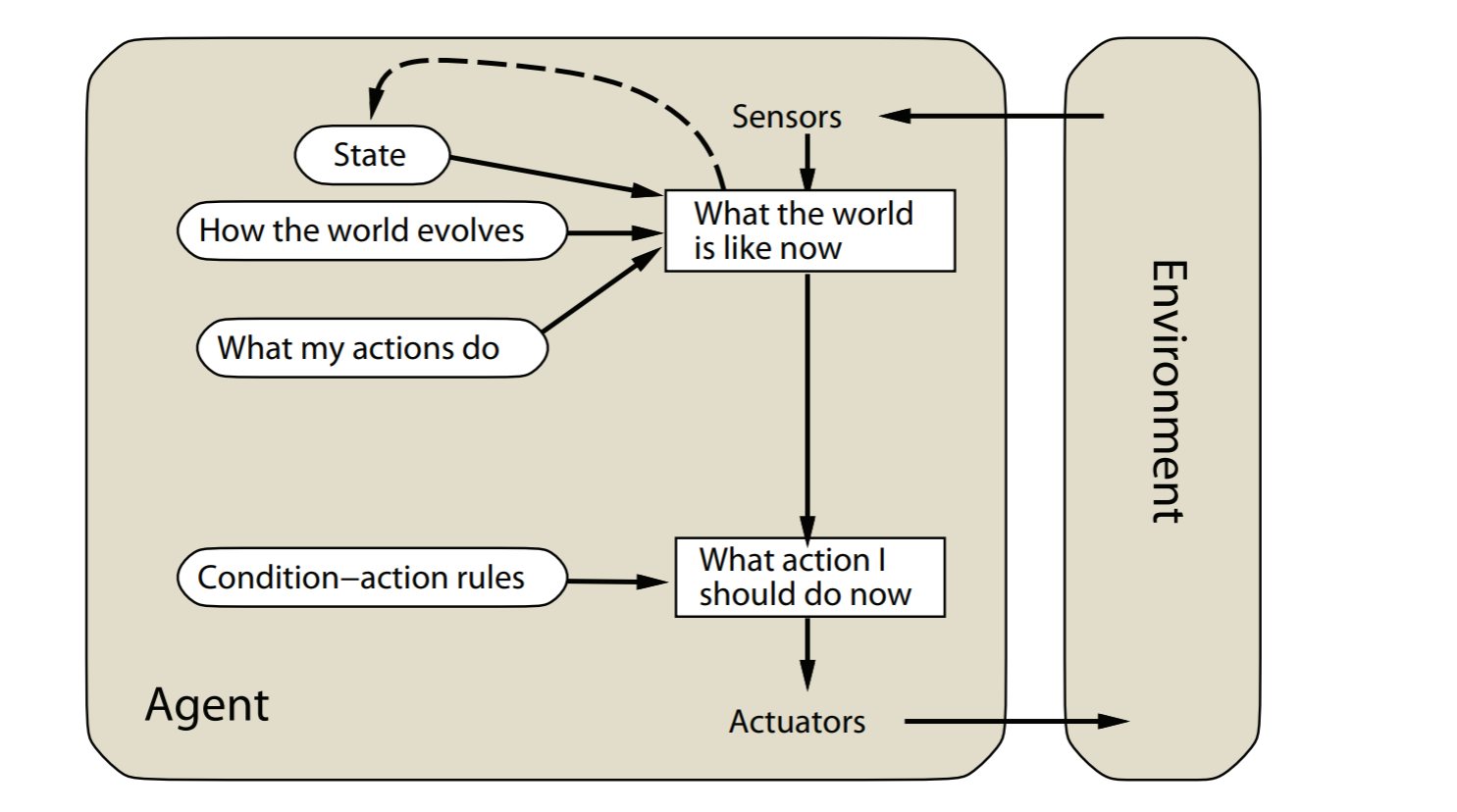
simple reflex agent的扩展版本,可以处理partial observability 通过追踪不能观测的环境
goal-based agents
model-based reflex agents的拓展版本。agent的目标会被explicitly considered明确的考虑
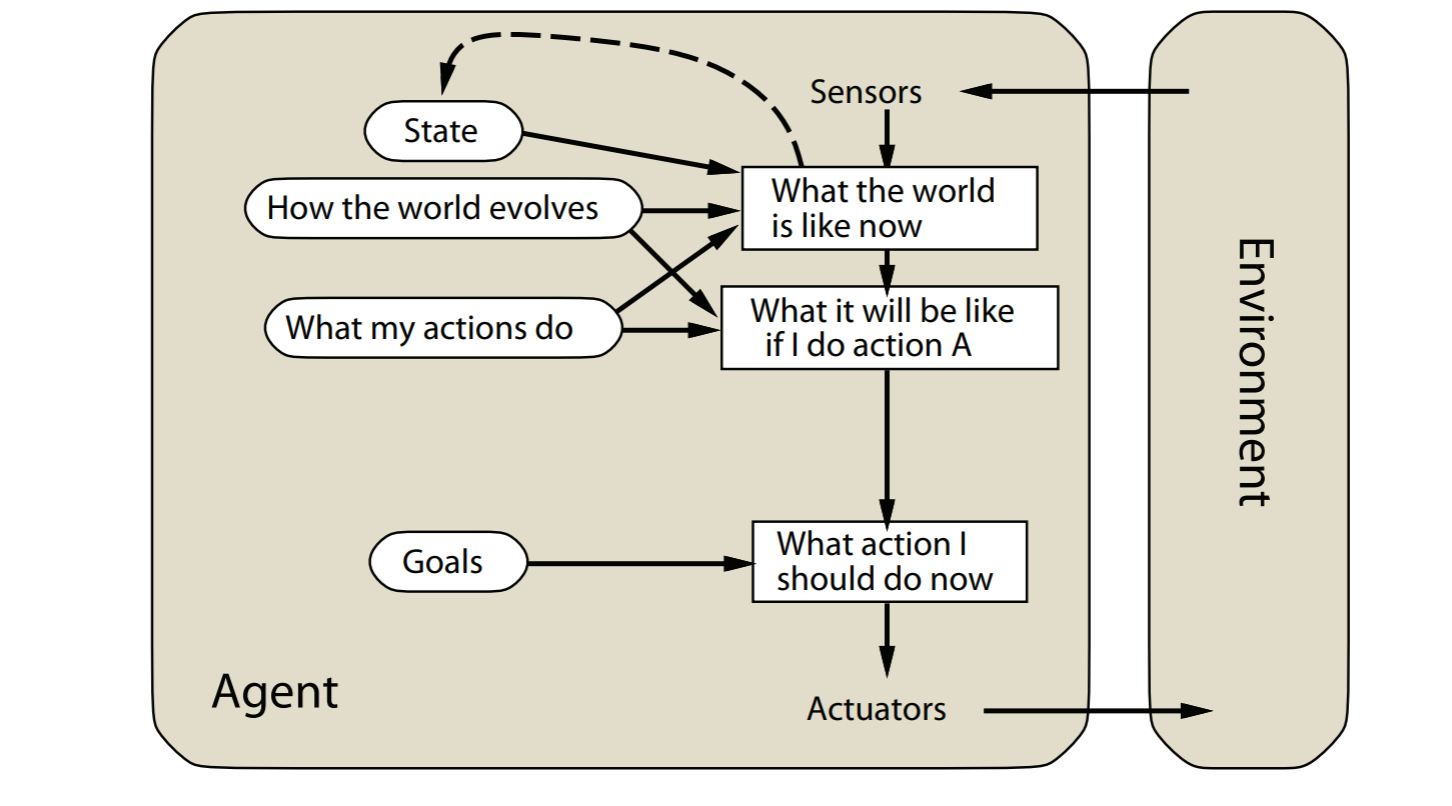
utility-based agents
goal-based reflex agents的扩展版本。
会最大化效用(utility),比如最大化agent的幸福程度
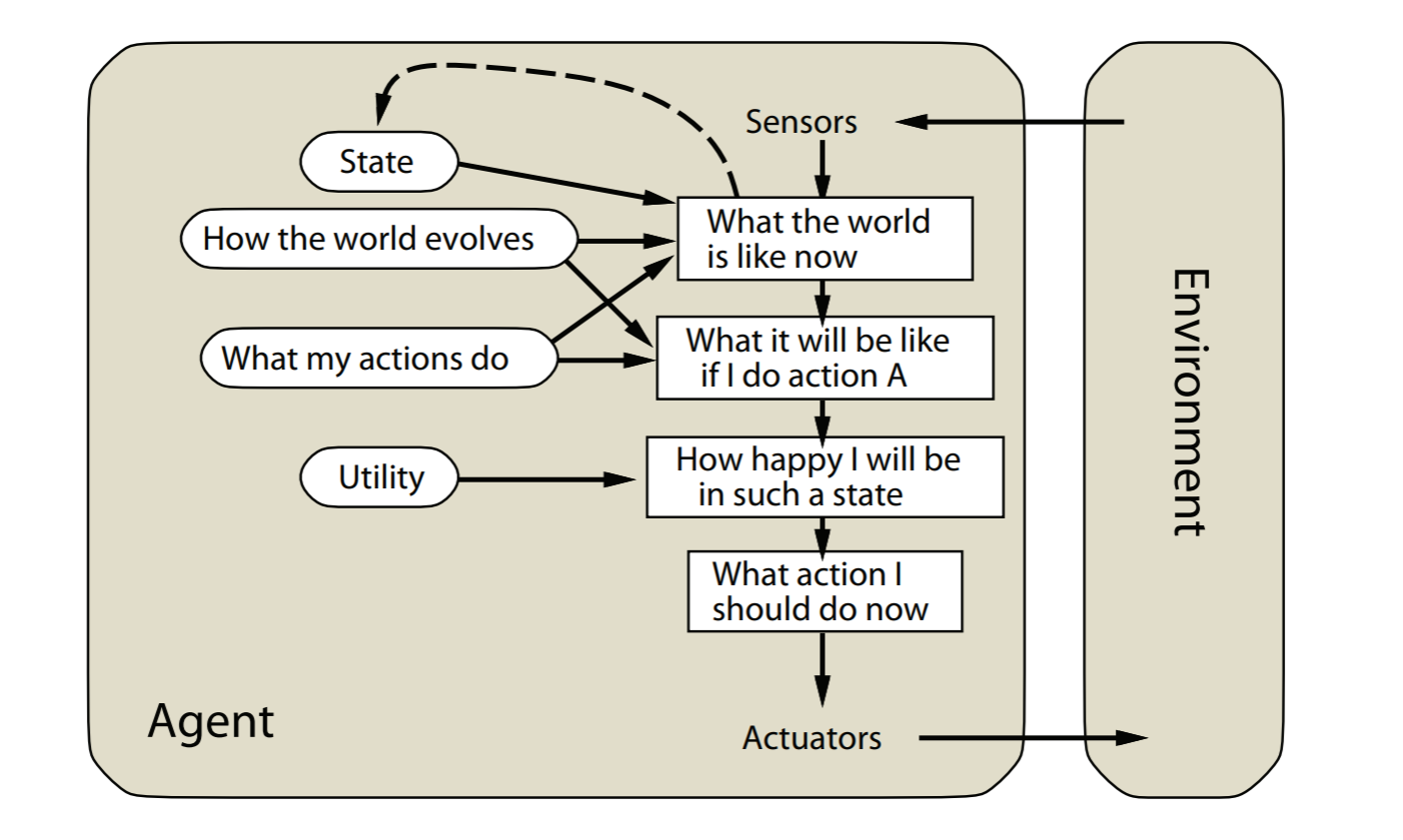
Learning agents
所有agent都可以扩展为学习agent
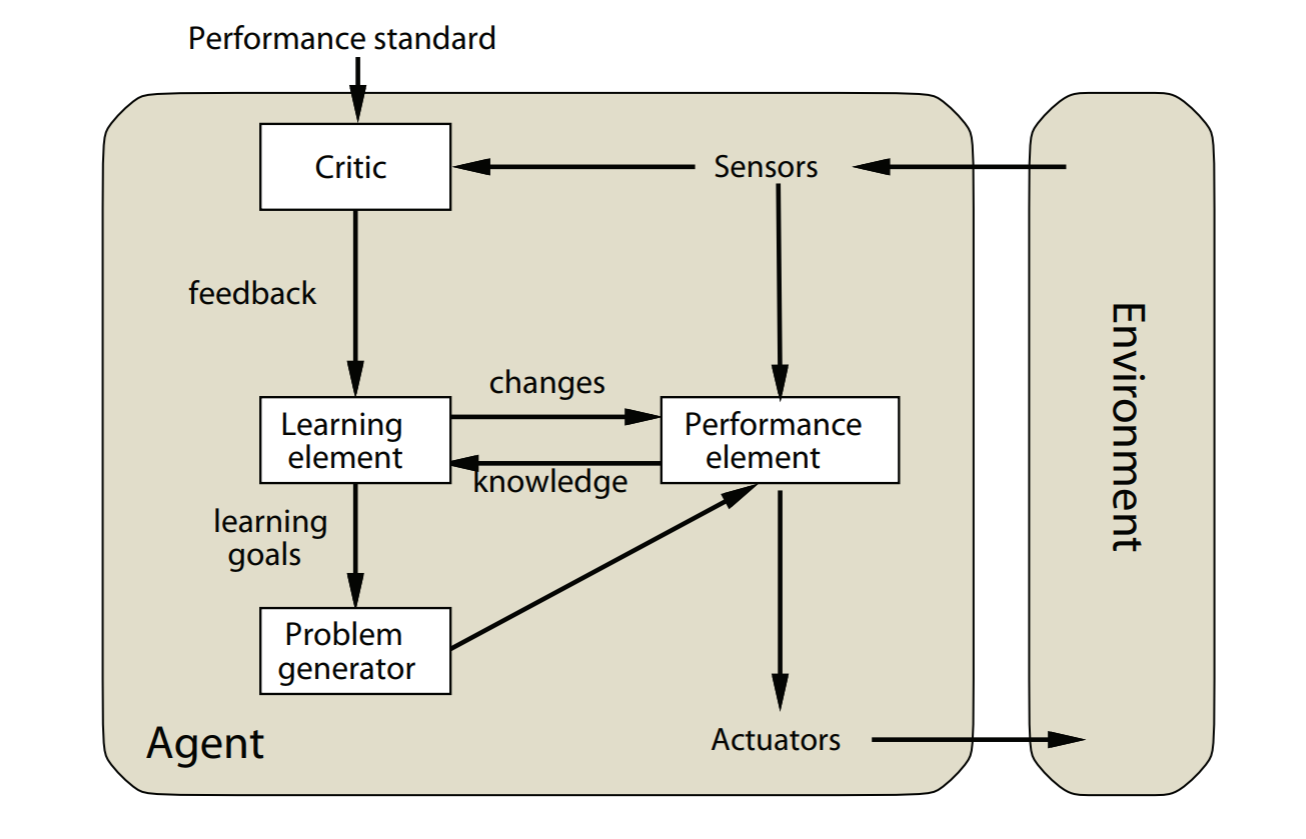
Constraint Satisfaction Problems
A constraint satisfaction problem is a tuple \((X,D,C)\)
\(X\) 是变量集合, \(D\) 是变量的值域,\(C\) 是限制的集合
限制的种类
- unary 单个值 \(sa \ne green\)
- binary 两个变量 \(sa \ne wa\)
- high-order 多个变量 \(sa\ne wa \ne nt\)
人工智能深度学习
模型评估与选择
经验误差与过拟合
错误率
如果\(m\) 个样本中有\(a\) 个错误,则错误率为 \(E=\frac{a}{m}\) ,精度为 \(1 - E\)
误差
学习器在训练集上的误差是训练误差,在新样本上的误差是泛化误差
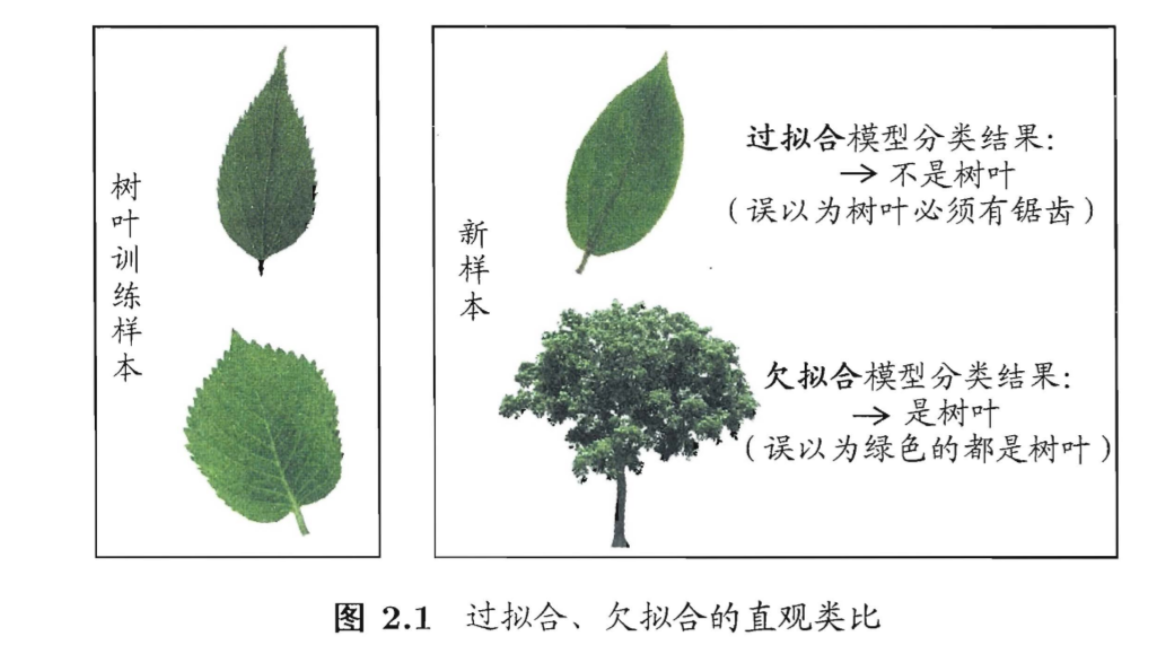
过拟合和欠拟合
过拟合是学习能力过于强大分类标准过于严格,欠拟合是学习能力低下分类标准过于松
评估方法
我们需要训练集来训练样本,测试集来测试样本。怎样更好地划分出这两个集合呢,有下面这几种办法。
留出法
直接把数据集 \(D\) 分成两个互斥的集合,一个作为训练集\(S\) 一个作为测试集 \(T\) 。可以直接三七分或者二八分。但是需要注意数据的平均性。
比如有连续的10年内的数据。不能把前7年训练,后三年测试。但这会破坏数据的分布。应该随机抽取7成数据训练,剩下的再测试。
交叉验证法
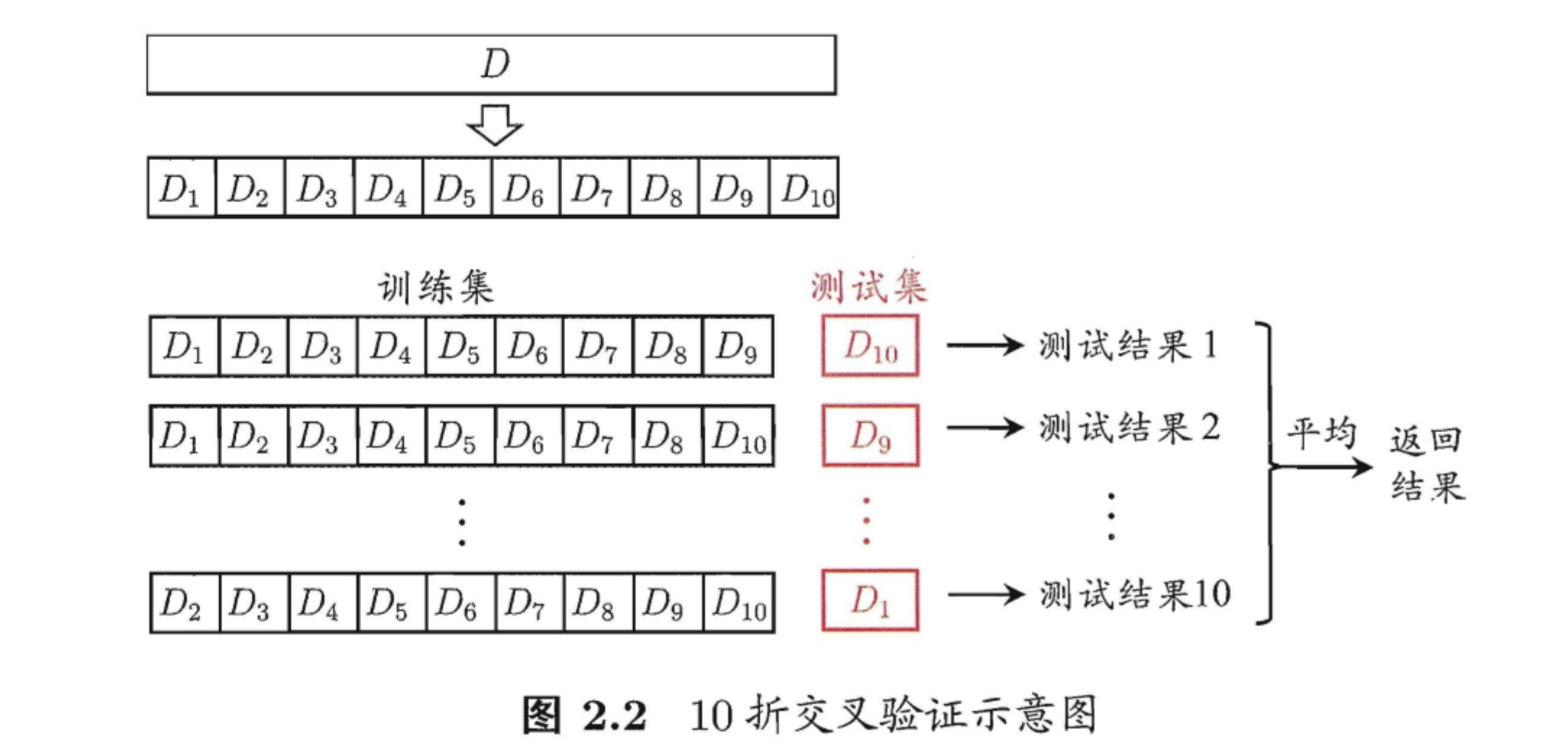
把数据分为10分 \(D_{1}\) 到 \(D_{10}\) ,分别
把\(D_{10}\) 到\(D_{1}\) 作为测试集,其他的作为训练集,测试10次。然后取平均值。这对计算机的算力要求高。
自助法
从包含\(m\)个样本的数据集中每次都随机抽取样本(可以重复), 抽\(m\) 次,对于每个元素,被抽中的概率是 \(\frac{1}{m}\) ,没被抽中的概率是 \(1-\frac{1}{m}\) .所以始终没被选中的概率有 \[ \lim _{m \rightarrow \infty}\left(1-\frac{1}{m}\right)^{m} \mapsto \frac{1}{e} \approx 0.368 \] 也就是大概\(36.8\%\)的数据没有被选中,可以作为测试集。
调参与最终模型
大多数学习算法都有些参数(parameter)需要设定,参数配置不同,学得模型的性能往往有显著差别.因此,在进行模型评估与选择时,除了要对适用学习算法进行选择,还需调参。
每次选定一个参数,都要重新训练一次。所以我们需要一个验证集来多次验证每一次的训练结果。等调好参数后,最终再用测试集测试最终的结果
性能度量
对学习器的泛化性能进行评估需要有衡量模型泛化能力的评价标准,这就是性能度量。
如果训练集是 \(D=\left\{\left( x _{1}, y_{1}\right),\left( x _{2}, y_{2}\right), \ldots,\left( x _{m}, y_{m}\right)\right\}\)
回归任务最常用的是均方误差: \[ E(f ; D)=\frac{1}{m} \sum_{i=1}^{m}\left(f\left( x _{i}\right)-y_{i}\right)^{2} \] 对于数据分布 \(\mathcal{D}\) 和概率密度函数 \(p(\cdot)\) , 它可以描述为 \[ E(f ; D )=\int_{ x \sim D }(f( x )-y)^{2} p( x ) d x \] 也就是对每个样本出现的概率加权,然后在求和。
错误率和精度
错误率
统计错误个数, 然后除以总个数 \[ E(f ; D)=\frac{1}{m} \sum_{i=1}^{m} \mathbb{I} \left(f\left( x _{i}\right) \neq y_{i}\right) \] 这个 \(\mathbb{I}\) 是 判断 \(f \left( x _{i}\right) \neq y_{i}\) 是否成立,如何是就是 \(1\) 否则就是 \(0\).
精度
\[ \operatorname{acc}(f ; D)=\frac{1}{m} \sum_{i=1}^{m} \mathbb{I} \left(f\left( x _{i}\right)=y_{i}\right) \]
查准率,查全率与F1
对于2分类问题,正例是答案正确的,反例是答案错误的。\(TP\)是有多少个正确的答案算对了, \(FN\) 是有多少个正确的答案算错了,\(FP\) 是有多少个错误答案算对了。
比如100个数据,70个标答是正确。预测这70个样本中80个是正例,其中正确的是60个,错误的是20个。那么TP就是60,FP就是20,FN就是10
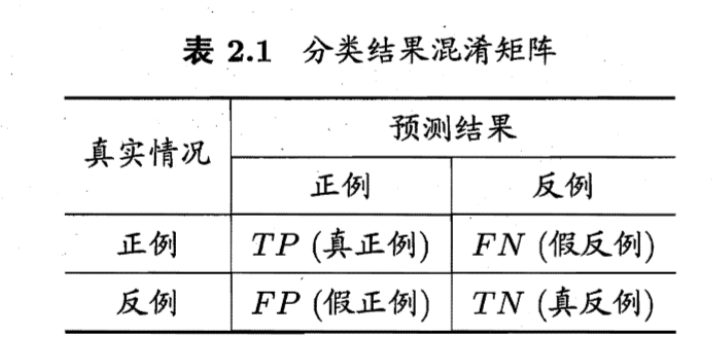
查准率\(P\) 和查全率\(R\) 定义为 \[ \begin{array}{l} P=\frac{T P}{T P+F P} \\ R=\frac{T P}{T P+F N} \end{array} \] 查准率是我预测出来的正例中的正确率是多少。查全率是所有的样本中我预测出来了多少个正例。
人工智能基础概念
预测
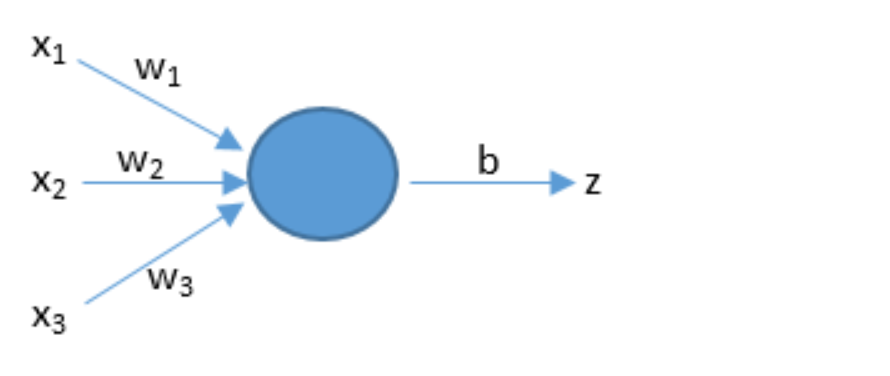
\(z = dot(w,x) + b\)
人工智能通上面的公式来预测。w和x是向量,dot是向量积。b是阈值。x是输入。w1是权值,表示每个输入的重要程度。
激活函数
在实际的神经网络中,我们不能直接用逻辑回归。必须要在逻辑回归外面再套上一个函数。这个函数我们就称它为激活函数。激活函数非常非常重要,如果没有它,那么神经网络的智商永远高不起来。 \[ \sigma(z)=\frac{1}{1+e^{-z}} \] 我们可以画出它的图像。
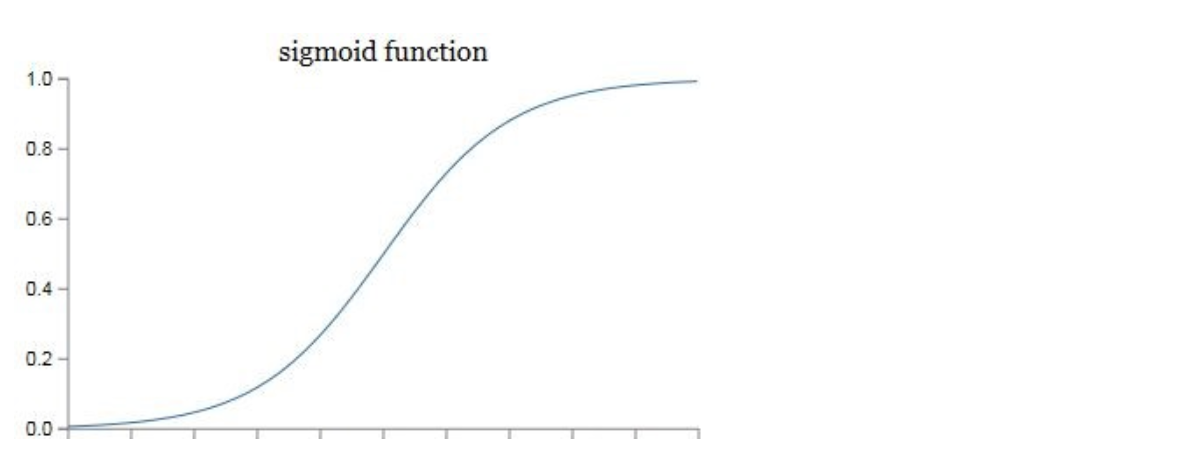
我们在这里先只介绍它的一个用途——把z映射到[0,1]之间。也可以理解为结果的概率
损失函数
神经网络里如何判断自己预测的结果是否准确 \[ \begin{aligned} &\hat{y}^{(i)}=\sigma\left(w^{T} x^{(i)}+b\right)\\ &\sigma\left(Z^{(i)}\right)=\frac{1}{1+e^{-Z^{(i)}}} \end{aligned} \] 在上面的公式中: \(\hat{y}\)表示预测的结果,\(\hat{y}^{(i)}\)上面的i表示针对某个训练样本。比如\(\hat{y}^{(i)}\)是针对\(x^{(i)}\)的预测结果。在实践中,我们会用到下面的公式: \[ L\left(\hat{y}^{(i)}, y^{(i)}\right)=-\left(y^{(i)} \log \left(\hat{y}^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-\hat{y}^{(i)}\right)\right) \] 但是这只是单个样本的公式,如果我们要堆所有的样本进行精度的预测,那么我们就要用到下面的公式,也就是求和再求平均值 \[ J(w, b)=\frac{1}{m} \sum_{i=1}^{m} L\left(\hat{y}^{(i)}, y^{(i)}\right)=-\frac{1}{m} \sum_{i=1}^{m}\left[\left(y^{(i)} \log \left(\hat{y}^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-\hat{y}^{(i)}\right)\right]\right. \]
梯度下降
在预测的公式里。w和b决定了预测结果是否准确。所以得到这两个参数的值的方式是梯度下降,它会一步步改变w和b的值,让预测的结果更加精确。上面的公式是一个漏斗型的函数,我们需要求出再函数底部的一组w和b。
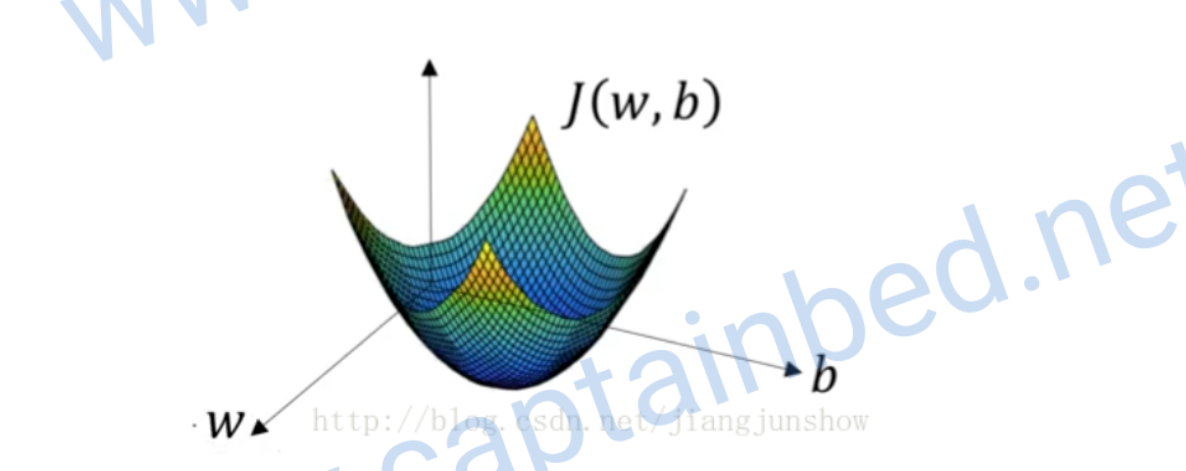
这是一个凸函数(向下凸的函数),我们选择J也是因为它是个凸函数
计算图
计算图是研究人工智能的重要手段。
神经网络的计算是由一个向前传播和一个反向传播构成的。向前传播计算出预测结果和损失。反向传播计算损失函数关于每个参数(w,b)的偏导数来梯度下降。由此往复达到最优的值。
例如:\(J(a, b, c)=3(a+b c)\)
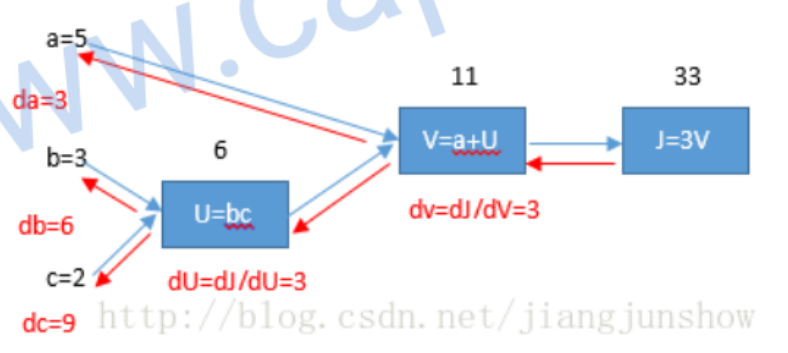 \[
\left\{\begin{array}{l}
U=b c \\
v=a+U \\
J=3 V
\end{array}\right.
\] 我们可以求出对于的偏导数 \[
\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{V}}=3 ,
\frac{\mathrm{d} \mathrm{V}}{\mathrm{d} \mathrm{U}}=1 ,
\frac{\mathrm{d} \mathrm{U}}{\mathrm{d} \mathrm{b}}=c=2 \\
\Rightarrow\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{U}}
=\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{V}} \cdot
\frac{\mathrm{d} \mathrm{V}}{\mathrm{d} \mathrm{U}}=3\cdot1=3
\Rightarrow\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{b}}
=\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{U}} \cdot
\frac{\mathrm{d} \mathrm{U}}{\mathrm{d} \mathrm{b}}=3\cdot2=6 \\
\Rightarrow\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{a}} =3
,\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{b}} =6,\frac{\mathrm{d}
\mathrm{J}}{\mathrm{d} \mathrm{c}} =9 \\
\Rightarrow \mathrm{d} \mathrm{a}=3,\mathrm{d} \mathrm{b}=6,\mathrm{d}
\mathrm{c}=9
\]
\[
\left\{\begin{array}{l}
U=b c \\
v=a+U \\
J=3 V
\end{array}\right.
\] 我们可以求出对于的偏导数 \[
\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{V}}=3 ,
\frac{\mathrm{d} \mathrm{V}}{\mathrm{d} \mathrm{U}}=1 ,
\frac{\mathrm{d} \mathrm{U}}{\mathrm{d} \mathrm{b}}=c=2 \\
\Rightarrow\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{U}}
=\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{V}} \cdot
\frac{\mathrm{d} \mathrm{V}}{\mathrm{d} \mathrm{U}}=3\cdot1=3
\Rightarrow\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{b}}
=\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{U}} \cdot
\frac{\mathrm{d} \mathrm{U}}{\mathrm{d} \mathrm{b}}=3\cdot2=6 \\
\Rightarrow\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{a}} =3
,\frac{\mathrm{d} \mathrm{J}}{\mathrm{d} \mathrm{b}} =6,\frac{\mathrm{d}
\mathrm{J}}{\mathrm{d} \mathrm{c}} =9 \\
\Rightarrow \mathrm{d} \mathrm{a}=3,\mathrm{d} \mathrm{b}=6,\mathrm{d}
\mathrm{c}=9
\]
计算梯度下降的偏导数
例如两个变量的模型,先算出z再算出预测值,然后计算损失函数 \[
\begin{aligned}
&z=w^{T} x+b\\
&\hat{y}=a=\sigma(z)\\
&\mathcal{L}(a, y)=-(y \log (a)+(1-y) \log (1-a))
\end{aligned}
\] 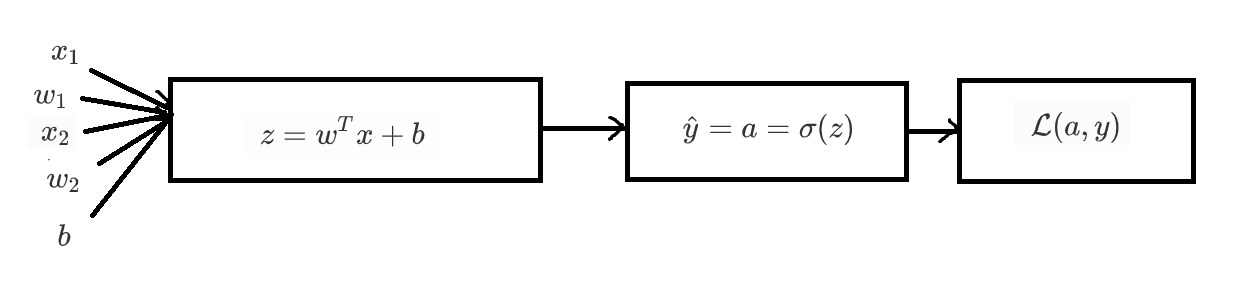
目的是计算出 \(d\mathcal{L}/dw_{1},d\mathcal{L}/dw_{2},d\mathcal{L}/db\), 然后更新 \(w_{1},w_{2},b\) 来小损失函数。首先需要计算dL/da和da/dz。dL/da可以直接求导, \[ \frac{d L}{d a}=-\frac{y}{a}+\frac{1-y}{1-a} \] da/dz需要用到换元法 \[ a=\sigma\left(z\right)=\frac{1}{1+e^{-z}} = (1+e^{-z})^{-1} , g = (1+e^{-z}) \Rightarrow a=g^{-1} \\ \frac{da}{dg}=-g^{-2}, \frac{dg}{dz} = -e^{-z} \Rightarrow \frac{da}{dz}=g^{-2} \cdot e^{-z} \\ \frac{da}{dz}= (1+e^{-z})^{-2} \cdot e^{-z}= \frac{e^{-z}}{(1+e^{-z})^{2}}, 1-a = \frac{1+e^{-z}}{1+e^{-z}}-\frac{1}{1+e^{-z}}=\frac{e^{-z}}{1+e^{-z}} \\ \Rightarrow \frac{da}{dz}= a(1-a) \] 综上可以算出dL/dz \[ \frac{d L}{d a}=-\frac{y}{a}+\frac{1-y}{1-a} ,\quad \frac{d a}{d z}=a(1-a) \\ \begin{aligned} \frac{d L}{d z}=\frac{d L}{d a} \cdot \frac{d a}{d z} &=-y(1-a)+(1-y) a \\ &=-y+ya+a-ya \\ &=a-y \end{aligned} \] 于是有 \[ dw_{1}=\frac{d L}{d w_{1}}=\frac{d L}{d z} \cdot \frac{d z}{d w_{1}}=(a-y) \cdot x_{1} \\ dw_{2}=\frac{d L}{d w_{2}}=\frac{d L}{d z} \cdot \frac{d z}{d w_{2}}=(a-y) \cdot x_{2} \\ db=\frac{d L}{d b}=\frac{d L}{d z} \cdot \frac{d z}{db}=(a-y) \cdot 1 \\ \] 得到这三个值之后,就可以利用它们梯度下降 \[ \begin{array}{l} w_{1}:=w_{1}-\alpha d w_{1} \\ w_{2}:=w_{2}-\alpha d w_{2} \\ b:=b-\alpha d b \end{array} \]
向量化
如果用上面的计算很大的数据,效率是很慢的。我们需要向量化来提速。例如 \[ \sum_{i=1}^{3} A_{i} \cdot B_{i} = A_{1} \cdot B_{1} +A_{2} \cdot B_{2} +A_{3} \cdot B_{3} \] 它等价于 \[ \begin{aligned} &A=[1,2,3]\\ &\mathrm{B}=[1,2,3] \end{aligned} \\ sum=A \cdot B \]
Python环境
Anaconda集成了Jupiter Notebook,是很好的Python开发环境。
链接:https://pan.baidu.com/s/1cTTOBWvLzps1F4XfP875Ig 提取码:050r
下载好后安装完成。打开Anaconda Navigator,点jupyter的launch。

然后点击右上角的new中的Python3
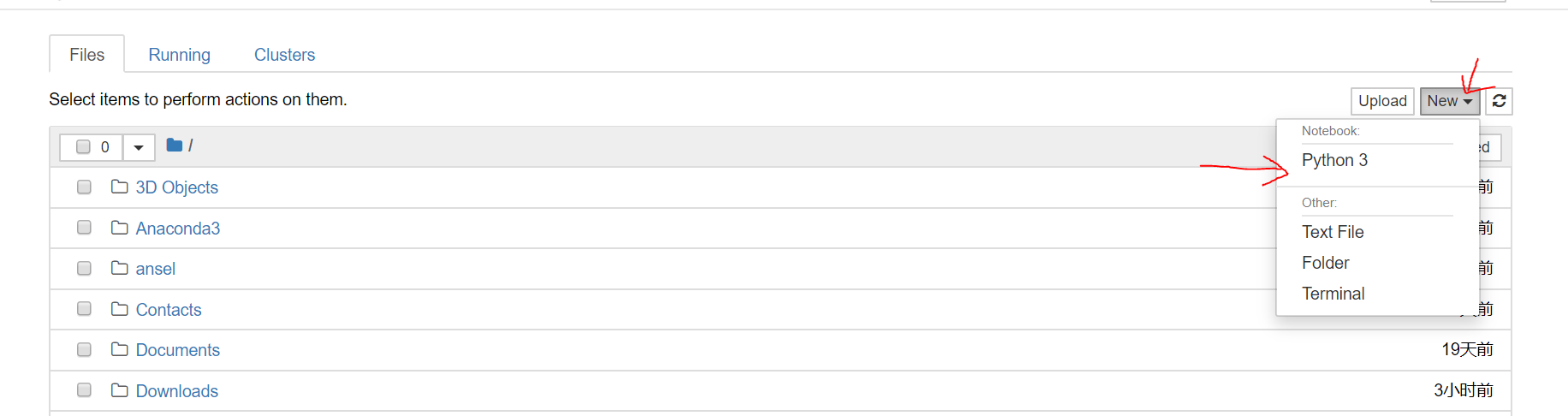
写程序的前置知识
HD5文件
HD5文件。Hierarchical Data Format(HDF)是一种针对大量数据进行组织和存储的。文件格式,大数据行业和人工智能行业都用它来保存数据。
Python读取HD5文件:
1 | import h5py # 加载库 |
numpy语法
shape
1 | a = np.array([[2,3,3],[2,2,5]]) # 定义np数组 |
reshape
改变数组的规格
1 | arr=np.arange(16).reshape(2,8) # 生产一个数组 |

1 | arr = arr.reshape(4,-1) # 改成4行 |

T: 转置
1 | arr=np.arange(16).reshape(2,8) # 上面的2*8数组 |
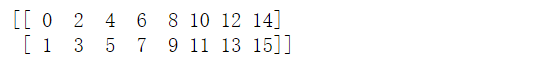
取出列
1 | print(arr[:, 1]) # 取出第1列的数据 |

交换行列
用切片操作
1 | # 交互第1行和第3行 |
初始化
.zero 函数
1 | m = np.zeros((3,2)) # 创建一个3行2列的矩阵并初始化成0 |
指数函数exp
\[ e^{x} \]
1 | arr = [0,1,2,4,5,6] |
求和sum
\[ \sum_{i=1}^{m} arr_{i} \cdot a_{i} \]
1 | arr = np.array([0,1,2,4,5,6]) |
matplotlib
显示图片
1 | index =2 |
或者
1 | # Load the image first |
Python第一个机器学习的例子
加载库和数据
加载库文件
1 | import numpy as np |
加载训练和测试数据
1 | def load_dataset(): |
预处理
数据扁平化和转置
1 | train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T |
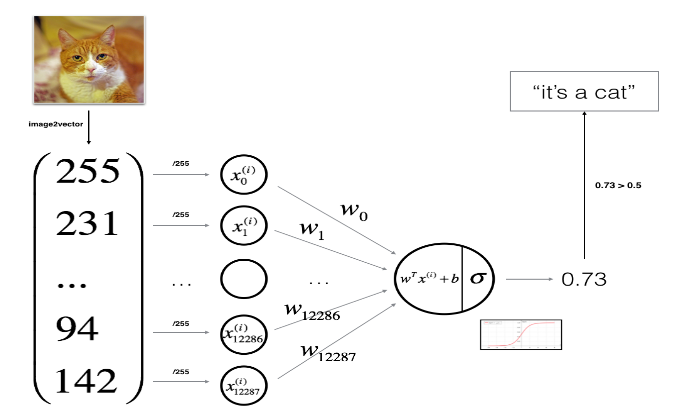
全部除以255,使得每个像素点都在\([0,1]\) 里,方便以后处理
1 | train_set_x = train_set_x_flatten/255. |
我们的神经网络图如下
编写工具函数
sigmoid
\[ \sigma(z)=\frac{1}{1+e^{-z}} \]
1 | def sigmoid(z): |
初始化
我们要初始化权重数组w和阈值b, dim是w的大小,在本例中是12288
1 | def initialize_with_zeros(dim): |
向前传播和反向传播
向前传播: \[ \begin{aligned} &A=\sigma\left(w^{T} X+b\right)=\left(a^{(1)}, a^{(2)}, \ldots, a^{(m-1)}, a^{(m)}\right)\\ &J=-\frac{1}{m} \sum_{i=1}^{m} y^{(i)} \log \left(a^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-a^{(i)}\right) \end{aligned} \] 反向传播: \[ \begin{aligned} &\frac{\partial J}{\partial w}=\frac{1}{m} X(A-Y)^{T}\\ &\frac{\partial J}{\partial b}=\frac{1}{m} \sum_{i=1}^{m}\left(a^{(i)}-y^{(i)}\right) \end{aligned} \]
1 | def propagate(w, b, X, Y): |
更新w和b
1 | def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost = False): |
预测函数
1 | def predict(w, b, X): |
将函数组合
1 | def model(X_train, Y_train, X_test, Y_test, num_iterations = 2000, learning_rate = 0.5, print_cost = False): |
浅层神经网络
之前我们学习的是单神经元的神经网络,其实还有多神经元的,比如下面这个
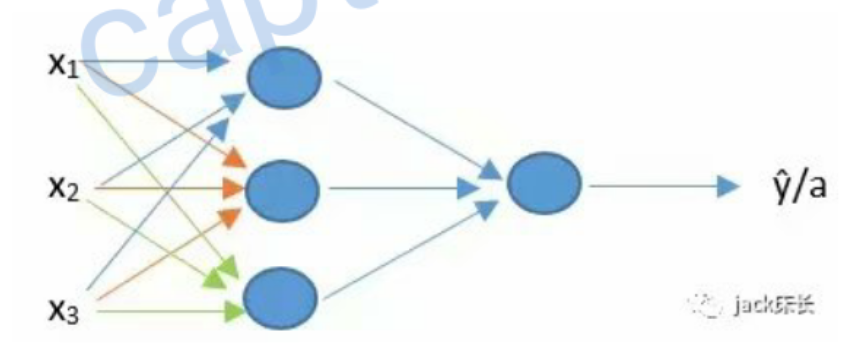
其中的每一个都是单个的神经元
计算向前传播
我们可以先算出第一层神经元的预测值a,上角标表示层数
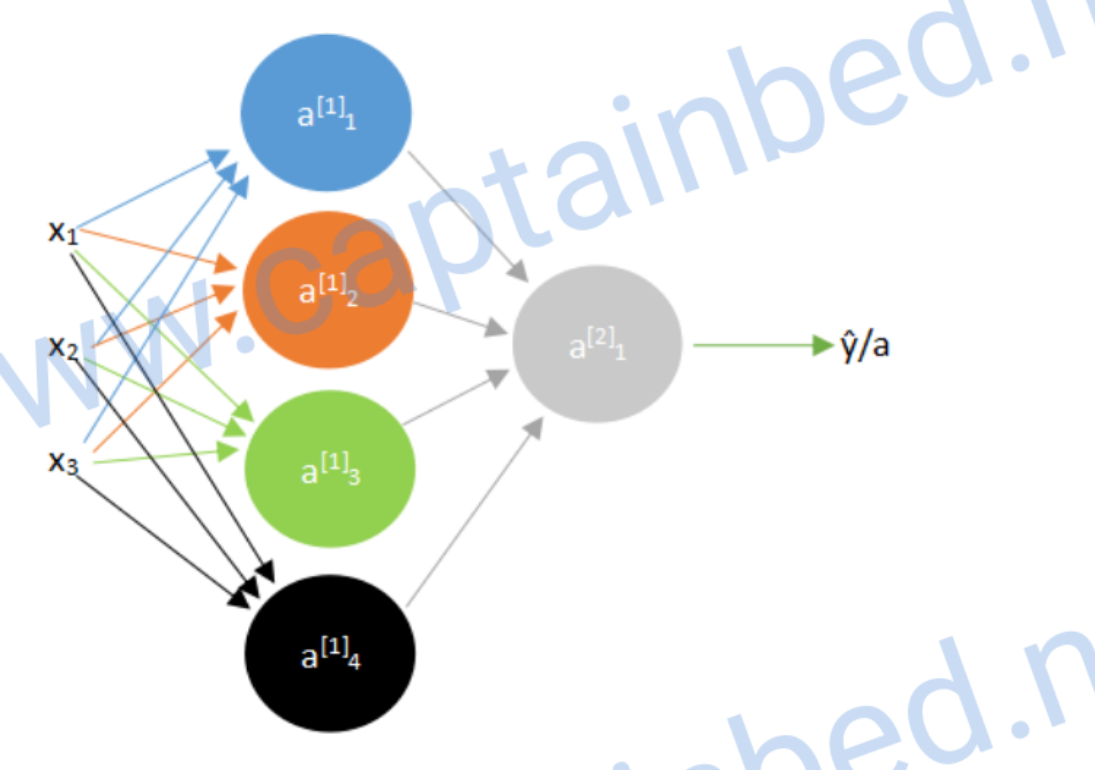 \[
\mathrm{z}_{1}^{[1]}=\mathrm{w}_{1}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{1}^{[1]},\quad
\mathbf{a}_{1}^{[1]}=\sigma(z_{1}^{[1]}) \\
\mathrm{z}_{2}^{[1]}=\mathrm{w}_{2}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{2}^{[1]},\quad
\mathbf{a}_{2}^{[1]}=\sigma(z_{2}^{[1]}) \\
\mathrm{z}_{3}^{[1]}=\mathrm{w}_{3}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{3}^{[1]},\quad
\mathbf{a}_{3}^{[1]}=\sigma(z_{3}^{[1]}) \\
\mathrm{z}_{4}^{[1]}=\mathrm{w}_{4}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{4}^{[1]},\quad
\mathbf{a}_{4}^{[1]}=\sigma(z_{4}^{[1]}) \\
\]
如果有很多神经元,一个个算效率很低,所以我们可以向量化。我们把w值组成一个矩阵
\[
\left[\begin{array}{l}
--\mathrm{w}_{1}^{[1] \mathrm{T}}-- \\
--\mathrm{w}_{2}^{[1] \mathrm{T}}-- \\
--\mathrm{w}_{3}^{[1] \mathrm{T}}-- \\
--\mathrm{w}_{4}^{[1] \mathrm{T}}--
\end{array}\right]\left[\begin{array}{l}
\times 1 \\
\times 2 \\
\times 3
\end{array}\right]+\left[\begin{array}{l}
\mathrm{b}_{1}^{[1]} \\
\mathrm{b}_{2}^{[1]} \\
\mathrm{b}_{3}^{[1]} \\
\mathrm{b}_{4}^{[1]}
\end{array}\right]
\] 于是我们就可以将上面4个式子简化成1个: \[
\mathrm{z}^{[1]}=\mathrm{W}^{[1]\top}\mathrm{x}+\mathrm{b}^{[1]},\quad
\mathbf{a}^{[1]}=\sigma(z^{[1]}) \\
\mathrm{z}^{[2]}=\mathrm{W}^{[2]\top}\mathrm{a}^{[1]}+\mathrm{b}^{[2]},\quad
\mathbf{a}^{[2]}=\sigma(z^{[2]}) \\
\]
上面的式子只使用于计算单个样本。而我们通常是由多个样本的,我们可以把每组数据的特征值组合成矩阵
\[
X=\left[\begin{array}{cccc}
| & | & & | \\
x^{(1)} & x^{(2)} & ... & x^{(m)} \\
| & | & & |
\end{array}\right]
\] 于是计算所有样本又可以这样简化: \[
\mathrm{Z}^{[1]}=\mathrm{W}^{[1]\mathrm{T}}\mathrm{X}+\mathrm{b}^{[1]},\quad
\mathbf{A}^{[1]}=\sigma(Z^{[1]}) \\
\mathrm{Z}^{[2]}=\mathrm{W}^{[2]\mathrm{T}}\mathrm{A}^{[1]}+\mathrm{b}^{[2]},\quad
\mathbf{a}^{[2]}=\sigma(Z^{[2]}) \\
\]
\[
\mathrm{z}_{1}^{[1]}=\mathrm{w}_{1}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{1}^{[1]},\quad
\mathbf{a}_{1}^{[1]}=\sigma(z_{1}^{[1]}) \\
\mathrm{z}_{2}^{[1]}=\mathrm{w}_{2}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{2}^{[1]},\quad
\mathbf{a}_{2}^{[1]}=\sigma(z_{2}^{[1]}) \\
\mathrm{z}_{3}^{[1]}=\mathrm{w}_{3}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{3}^{[1]},\quad
\mathbf{a}_{3}^{[1]}=\sigma(z_{3}^{[1]}) \\
\mathrm{z}_{4}^{[1]}=\mathrm{w}_{4}^{[1]\mathrm{T}}\mathrm{x}+\mathrm{b}_{4}^{[1]},\quad
\mathbf{a}_{4}^{[1]}=\sigma(z_{4}^{[1]}) \\
\]
如果有很多神经元,一个个算效率很低,所以我们可以向量化。我们把w值组成一个矩阵
\[
\left[\begin{array}{l}
--\mathrm{w}_{1}^{[1] \mathrm{T}}-- \\
--\mathrm{w}_{2}^{[1] \mathrm{T}}-- \\
--\mathrm{w}_{3}^{[1] \mathrm{T}}-- \\
--\mathrm{w}_{4}^{[1] \mathrm{T}}--
\end{array}\right]\left[\begin{array}{l}
\times 1 \\
\times 2 \\
\times 3
\end{array}\right]+\left[\begin{array}{l}
\mathrm{b}_{1}^{[1]} \\
\mathrm{b}_{2}^{[1]} \\
\mathrm{b}_{3}^{[1]} \\
\mathrm{b}_{4}^{[1]}
\end{array}\right]
\] 于是我们就可以将上面4个式子简化成1个: \[
\mathrm{z}^{[1]}=\mathrm{W}^{[1]\top}\mathrm{x}+\mathrm{b}^{[1]},\quad
\mathbf{a}^{[1]}=\sigma(z^{[1]}) \\
\mathrm{z}^{[2]}=\mathrm{W}^{[2]\top}\mathrm{a}^{[1]}+\mathrm{b}^{[2]},\quad
\mathbf{a}^{[2]}=\sigma(z^{[2]}) \\
\]
上面的式子只使用于计算单个样本。而我们通常是由多个样本的,我们可以把每组数据的特征值组合成矩阵
\[
X=\left[\begin{array}{cccc}
| & | & & | \\
x^{(1)} & x^{(2)} & ... & x^{(m)} \\
| & | & & |
\end{array}\right]
\] 于是计算所有样本又可以这样简化: \[
\mathrm{Z}^{[1]}=\mathrm{W}^{[1]\mathrm{T}}\mathrm{X}+\mathrm{b}^{[1]},\quad
\mathbf{A}^{[1]}=\sigma(Z^{[1]}) \\
\mathrm{Z}^{[2]}=\mathrm{W}^{[2]\mathrm{T}}\mathrm{A}^{[1]}+\mathrm{b}^{[2]},\quad
\mathbf{a}^{[2]}=\sigma(Z^{[2]}) \\
\]
计算反向传播
我们先计算出第二层预测值的偏导数
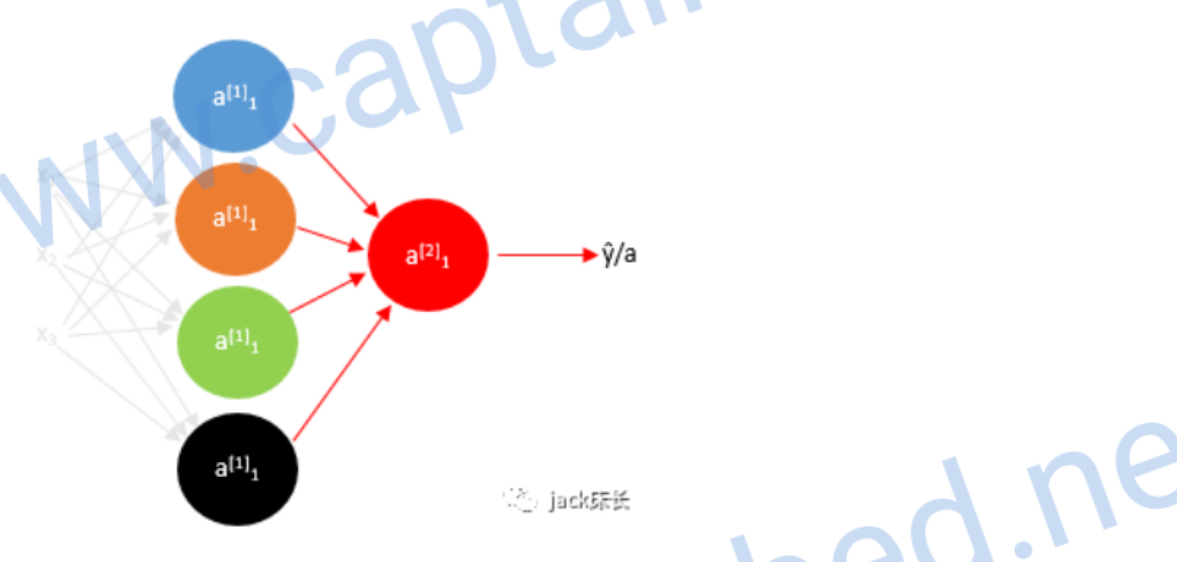
之前我们计算量单神经元的公式: \[
dz=a-y\\
dw_{1}=dz \cdot x_{1} \\
dw_{2}=dz \cdot x_{2} \\
db=dz \\
\] 这个模型和上个单神经元的模型一样,所以我们可以直接套用公式得出
\[
\begin{aligned}
&\mathrm{d} \mathrm{z}^{[2]}=\mathrm{a}^{[2]}-\mathrm{y}\\
&\mathrm{d} \mathrm{W}^{[2]}=\mathrm{d} \mathrm{z}^{[2]}
\mathrm{A}^{[1] \top}\\
&\mathrm{d} \mathrm{b}^{[2]}=\mathrm{d} \mathrm{z}^{[2]}
\end{aligned}
\] 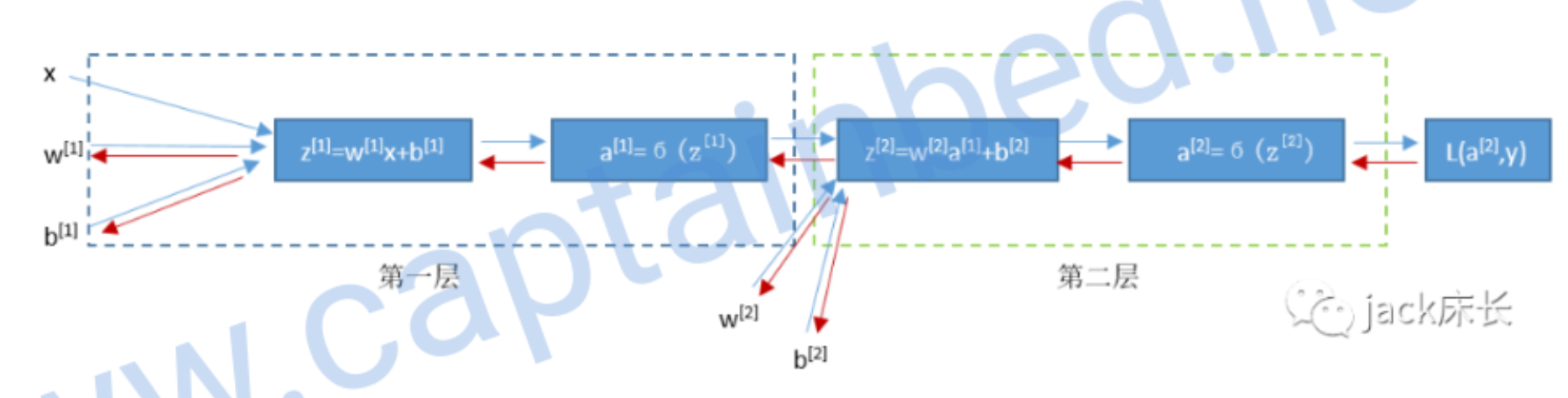
然后我们可以求出\(\frac{dL}{da^{[1]}}\)
\[
\frac{dL}{da^{[1]}}=\frac{dL}{dz^{[2]}} \cdot \frac{dz^{[2]}}{da^{[1]}}
= (\mathrm{a}^{[2]}-\mathrm{y}) \cdot W^{[2]\top} = W^{[2]\top}dz^{[2]}
\] 由于激活函数不知有sigmoid,之后我们会具体介绍,我们先用 \({g^{[1]}}'(z^{[1]})\) 来表示激活函数
\(a^{[1]}\) 关于 \(z^{[1]}\) 的偏导数 \[
dz^{[1]}=\frac{dL}{dz^{[1]}}=\frac{dL}{da^{[1]}} \cdot
\frac{da^{[1]}}{dz^{[1]}} =W^{[2]\top}dz^{[2]} \cdot
{g^{[1]}}'(z^{[1]})
\] 得出 \(dz^{[1]}\) 后,\(dW^{[1]}\) 和 \(db^{[1]}\) 就可以通过 \(dz^{[1]}\) 算出来: \[
\begin{aligned}
&d W ^{[1]}= d z ^{[1]} x ^{\top}\\
&db ^{[1]}= d z ^{[1]}
\end{aligned}
\] 以上的出来的公式是单样本的公式,多样本的公式如下 \[
\mathrm{d} \mathrm{Z}^{[2]}=\mathrm{A}^{[2]}-\mathrm{Y}\\
\mathrm{d} \mathrm{W}^{[2]}=\mathrm{d} \mathrm{Z}^{[2]} \mathrm{A}^{[1]
\top}/m \\
\mathrm{d} \mathrm{b}^{[2]}=np.sum(\mathrm{d} \mathrm{z}^{[2]})/m\\
dZ^{[1]}=W^{[2]\top}dZ^{[2]} \cdot {g^{[1]}}'(Z^{[1]}) \\
d W ^{[1]}= d Z ^{[1]} X ^{\top}/m\\
db ^{[1]}= np.sum(d z ^{[1]},axis=1,keepdims=True)/m
\] 最后一行中 axis=1
的作用是让sum只把每一行的加起来,keepdims是保持维度,以免出现 \((n^{[1]},)\) 的形式
激活函数
为什么要激活函数?因为我们每一层计算的都是线性的,无法表示复杂情况。就算有多层神经网络也没有用(因为代入之后依然是线性函数)。只有加入了激活函数,才可以表达复杂情况。下面是几种常见的激活函数。
sigmoid
尤其使用于二元分类的问题中,因为0到1的输出值可以表示概率
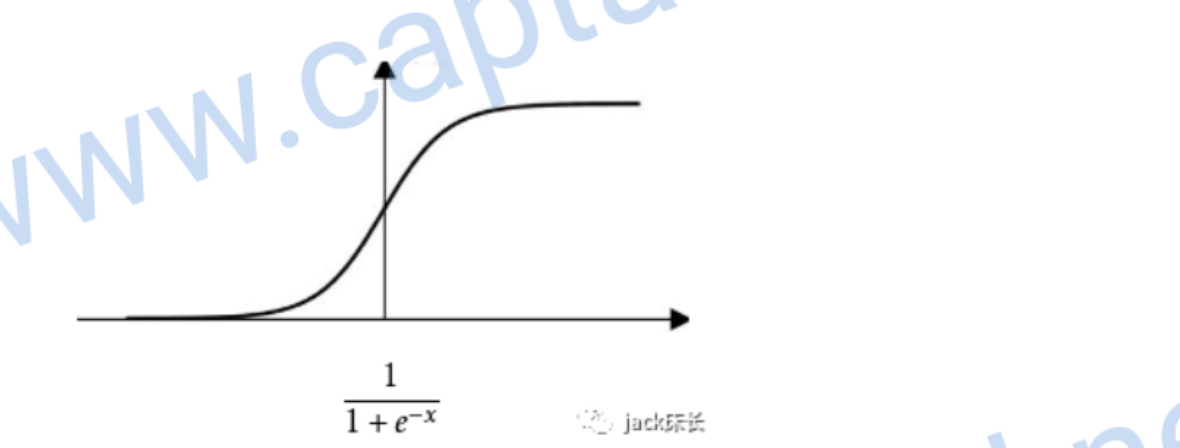
它的偏导数 \[ g'(z)= a(1-a) \]
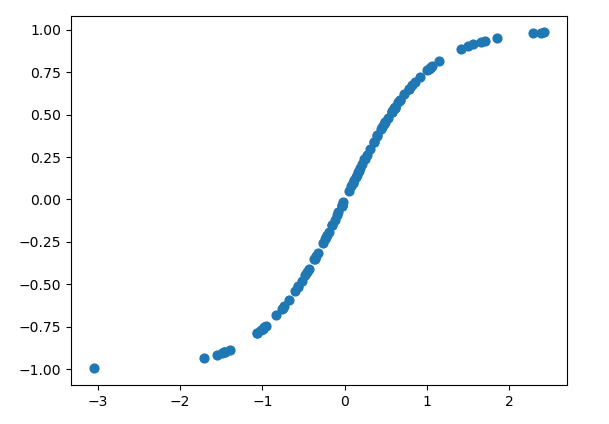
tanh
它是sigmoid的升级版,各方面都比sigmoid优秀一点
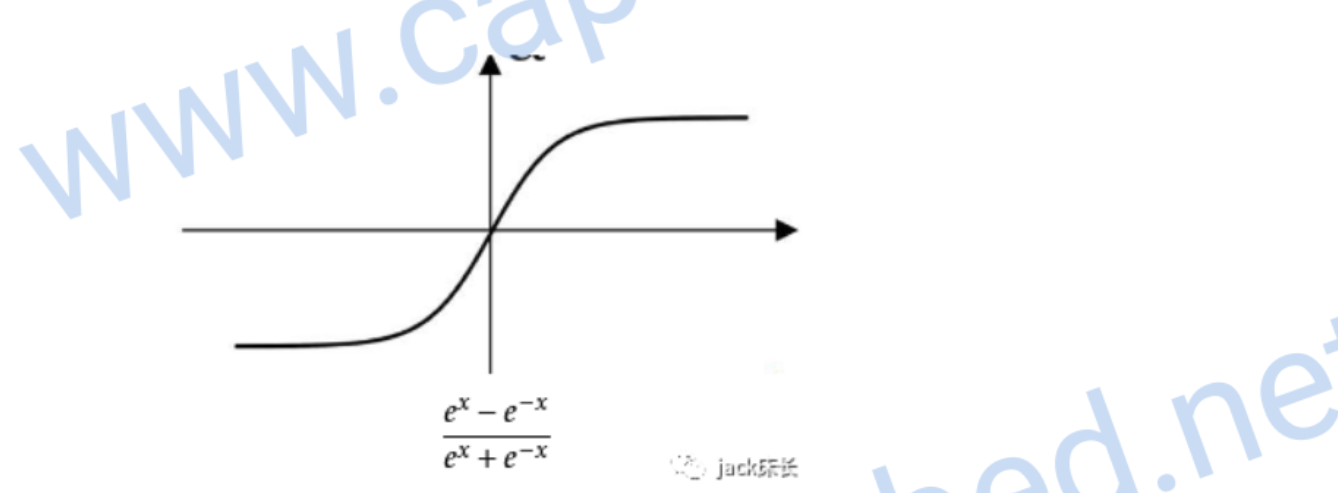
它的偏导数 \[ g'(z)= 1-a^{2} \]
relu
一般来说,relu用到的最多
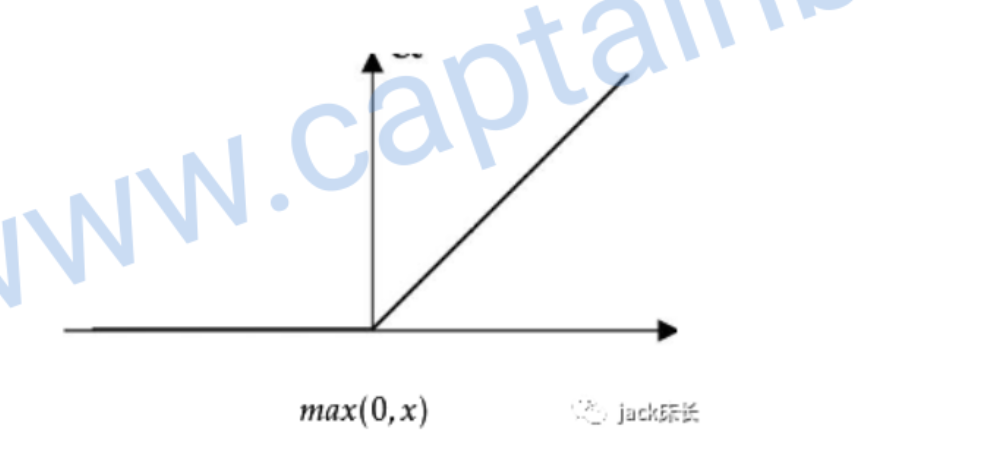
偏导数: \[ g'(z)=\left\{\begin{array}{ll} 0 & , z<0 \\ 1 & , z>=0 \end{array}\right. \]
leaky relu
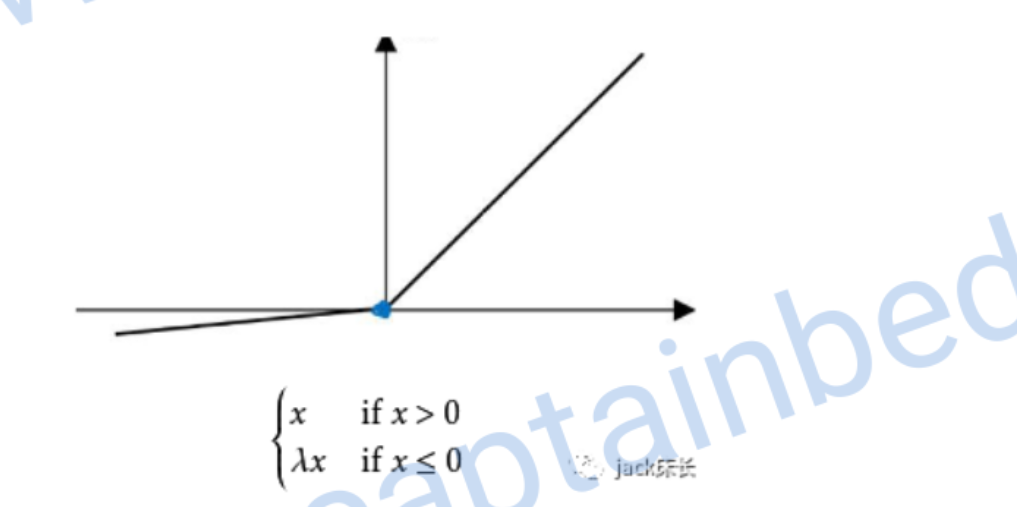
偏导数: \[ g'(z)=\left\{\begin{array}{ll} 0.01 & , z<0 \\ 1 & , z>=0 \end{array}\right. \]
随机初始化参数
对于多层神经网络来说,初始化参数不能都设置成0。否则它就变成了单个神经元。因为输入参数一样,计算结果一样。
一般使用numpy.random.randn来进行随机初始化。
比如 \(w^{[1]} = numpy.random.randn((2,2))*0.01\) 。我们在后面乘0.01的目的是把w变得更加小一点,这样带入sigmod函数里计算出的斜率会大,这样梯度下降的速度就快,神经网络的学习速度就快。
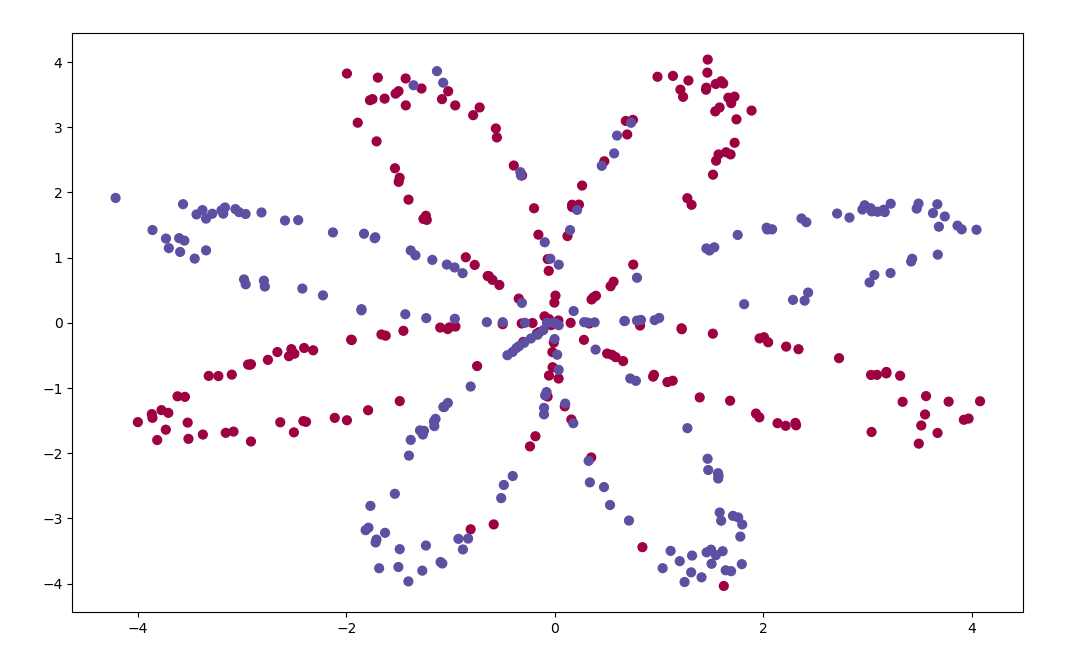
实战编写浅层神经网络
给定一个坐标,判断是蓝色还是红色
Python知识
ravel扁平化
可以把多维数组压缩成1维数组
1 | print(Y.shape, Y.ravel().shape) |
matplotlib.pyplot.scatter绘制散点
1 | plt.scatter(X[0, :], X[1, :], c=Y.ravel(), s=40, cmap=plt.cm.Spectral) |
例如画一个tanh函数
1 | n = 100 |
sklearn单神经元学习
1 | clf = sklearn.linear_model.LogisticRegressionCV() |
库文件
这次多了sklearn。它是数据挖掘,数据分析和机器学习的库,里面内置了很多人工智能的函数
1 | import numpy as np |
函数
初始化参数
1 | def initialize_parameters(n_x, n_h, n_y): |
向前传播
1 | def forward_propagation(X, parameters): |
计算成本函数
1 | # 这个函数被用来计算成本 |
反向传播
1 | def backward_propagation(parameters, cache, X, Y): |
梯度下降
1 | # 用上面得到的梯度来进行梯度下降(更新参数w和b,使其更优化) |
把函数组合在一起
1 | # 上面已经将各个所需的功能函数都编写好了。现在我们将它们组合在一个大函数中来构建出一个训练模型。 |
预测新数据
1 | # 我们已经可以通过上面的函数来进行参数训练。 |
评估
1 | # 好,所有函数都实现完毕了,我们已经构建好了一个浅层神经网络了。 |
深层神经网络
浅层神经网络只有两层。而深层神经网络可以由任意层。简单来说,就是把上一层的结果作为下一层的输入。
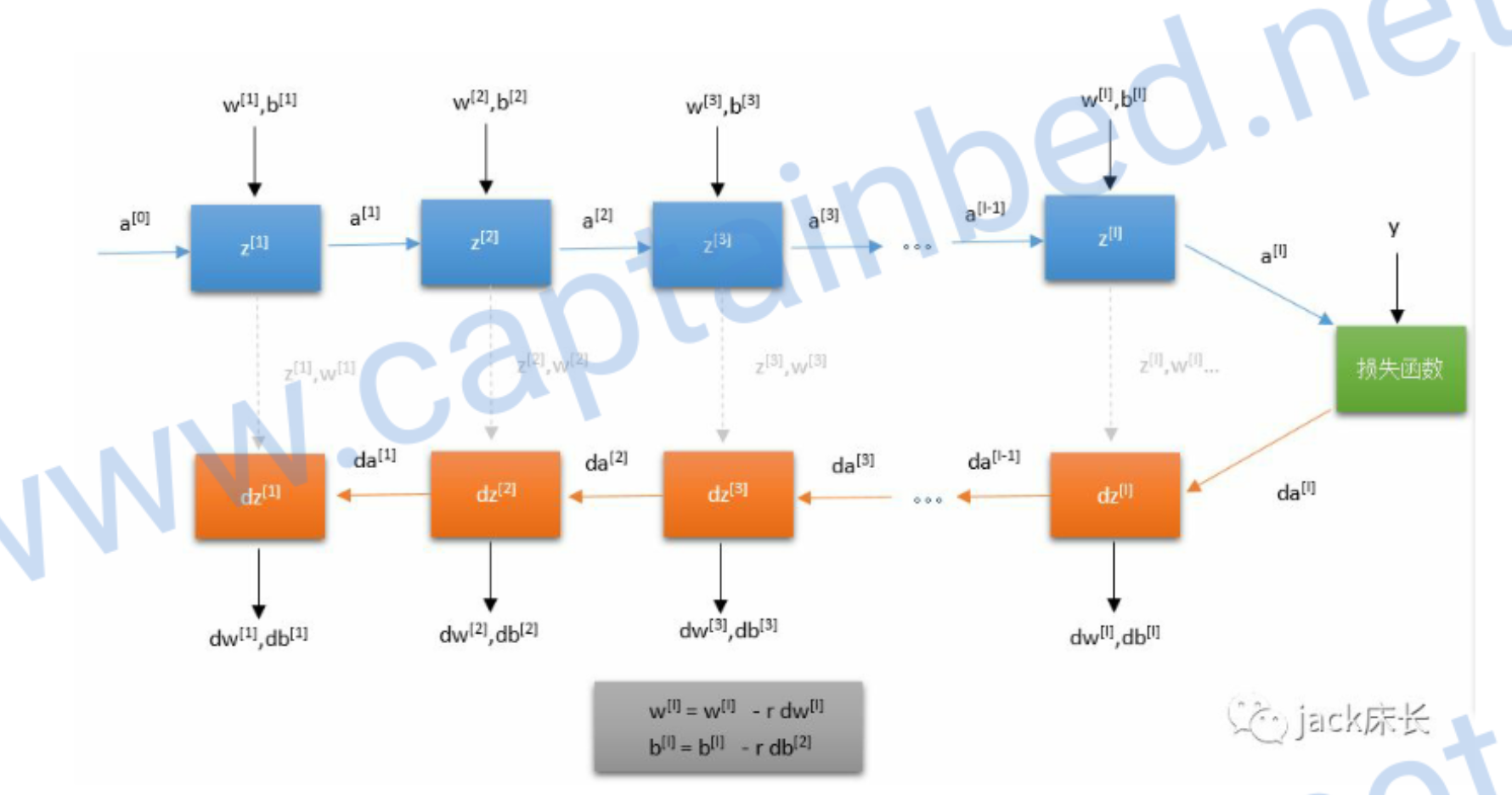
核对矩阵的维度
编写程序的时候,我们很容易由于维度的错误而出现错误。比如下面这张图。
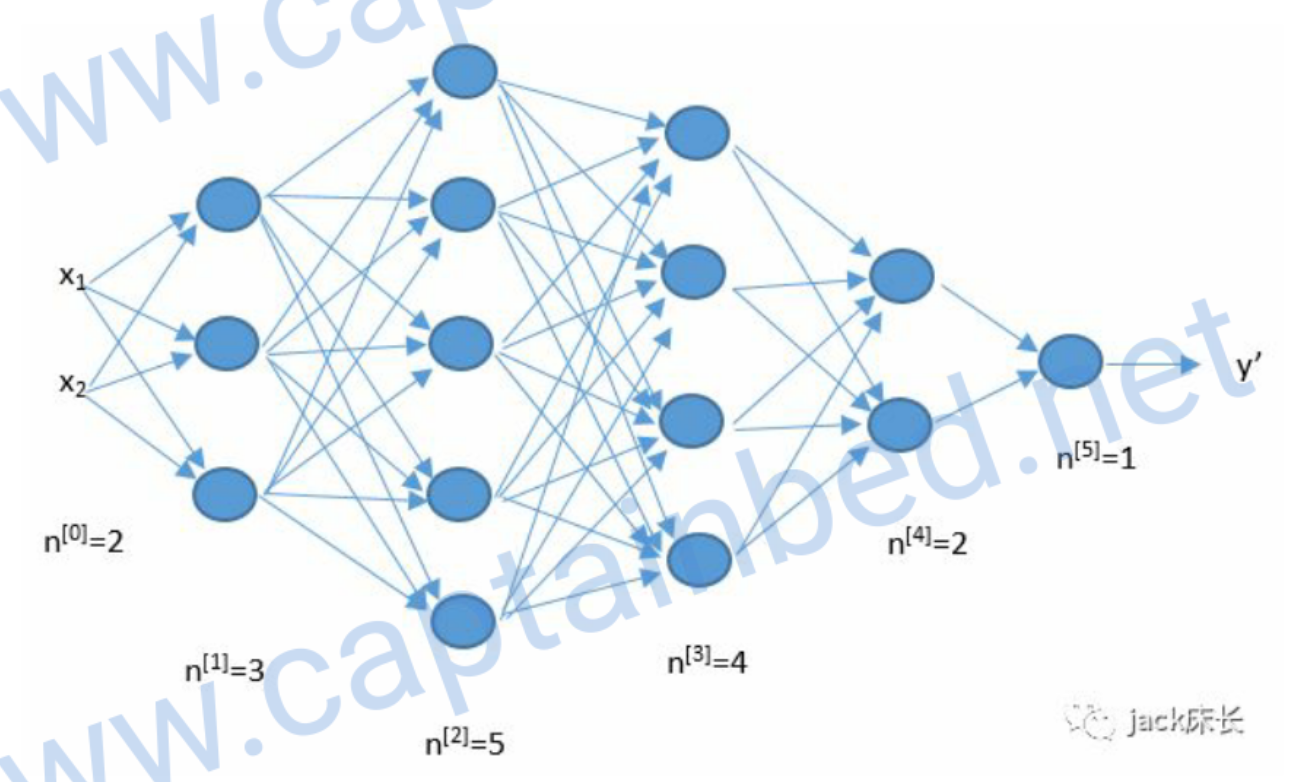
输入层有2个元素,所以\(n^{[0]}=2\) \[ W^{[l]} \rightarrow (n^{[l]},n^{[l-1]}) \\ b^{[l]} \rightarrow (n^{[l]},1) \\ z^{[l]} \rightarrow (n^{[l]},1) \\ a^{[l]} \rightarrow (n^{[l]},1) \\ da^{[l]} \rightarrow (n^{[l]},1) \\ dz^{[l]} \rightarrow (n^{[l]},1) \\ db^{[l]} \rightarrow (n^{[l]},1) \\ dW^{[l]} \rightarrow (n^{[l]},n^{[l-1]}) \\ \]
 wechat
wechat alipay
alipay